This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
The more indexes, the more the requirement of memory for effective caching. Indexes need more cache than tables Due to random writes and reads, indexes need more pages to be in the cache. Cache requirements for indexes are generally much higher than associated tables. Learn more about Percona Training
These guidelines work well for a wide range of applications, though the optimal settings, of course, depend on the workload. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. have been released since then with some major changes.
I've also used and helped develop many other technologies for debugging, primarily perf, Ftrace, eBPF (bcc and bpftrace), PMCs, MSRs, Intel vTune, and of course, [flame graphs] and [heat maps]. This diverse environment has always provided me with interesting things to explore, to understand, analyze, debug, and improve.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
As some of you may remember I was pretty excited when Amazon Simple Storage Service (S3) released its website feature such that I could serve this weblog completely from S3. My templates and blog posts are now located in DropBox and thus locally cached at each machine I use. Driving Storage Costs Down for AWS Customers.
We use high-performance transactions systems, complex rendering and object caching, workflow and queuing systems, business intelligence and data analytics, machine learning and pattern recognition, neural networks and probabilistic decision making, and a wide variety of other techniques. Driving Storage Costs Down for AWS Customers.
NOTE : All tests were applied for MySQL version 8.0.30, and in the background, I ran every query three to five times to make sure that all of them were fully cached in the buffer pool (for InnoDB) or by the filesystem (for MyISAM). But why we can’t just cache the actual number of the rows?
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. DynamoDB was the first service at AWS to use SSD storage.
In particular, she highlighted her transformative MIT’78 VLSI System Design Course she designed and taught as a Visiting Professor of EECS at MIT. The best paper runner-up was “ Dynamic Multi-Resolution Data Storage ”. . Goodman, and “Speculative Cache Ways: On-Demand Cache Resource Allocation” published at MICRO 1999 by David H.
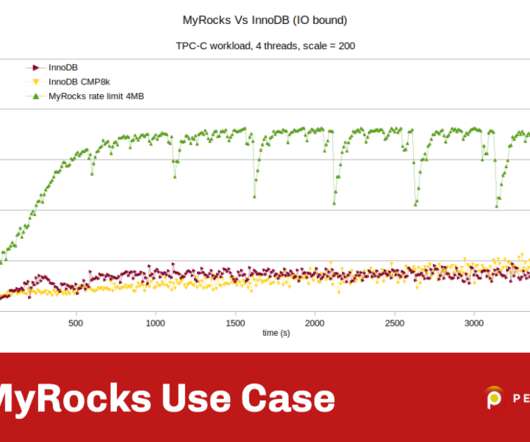
I wrote this post on MyRocks because I believe it is the most interesting new MySQL storage engine to have appeared over the last few years. I decided to use a virtual machine with two CPU cores, four GB of memory, and storage limited to a maximum of 1000 IOPs of 16KB. I emulated these limits using the KVM iotune settings in my lab. <iotune>
" Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing. The Dynamo paper was well-received and served as a catalyst to create the category of distributed database technologies commonly known today as "NoSQL."
This operation is quite expensive but our database can run it in a few milliseconds or less, thanks to several optimizations that allow the node to execute most of them in memory with no or little access to mass storage. Of course, we are still talking about a low number of rows and running threads but the gain is there.
Coupled with stateless application servers to execute business logic and a database-like system to provide persistent storage, they form a core component of popular data center service archictectures. Oh, you mean a cache? Yes, a bit like those 2nd-level caches we were talking about earlier, e.g. Ehcache from 2003 onwards.
These systems however adopt a cloud-based, centralised architecture that does not include any "edge computing" component – they typically assum an external, independent data ingestion pipeline that directs edge streams to cloud storage endpoints such as Kafka or Event Hubs.
The fact that this shows up as CPU time suggests that the reads were all hitting in the system cache and the CPU time was the kernel overhead (note ntoskrnl.exe on the first sampled call stack) of grabbing data from the cache. Now that we suspect file I/O it’s necessary to go to Graph Explorer-> Storage-> File I/O.
Its raison d’être is to cache result rows from a plan subtree, then replay those rows on subsequent iterations if any correlated loop parameters are unchanged. Table-valued functions use a table variable, which can be used to cache and replay results in suitable circumstances. Spools are the least costly way to cache partial results.
The challenging thing of course, is efficiently maintaining all of these parallel universes. If we do that naively though, we’re going to end up with a lot of universes to store and maintain and the storage requirements alone will be prohibitive. Expressing privacy policies.
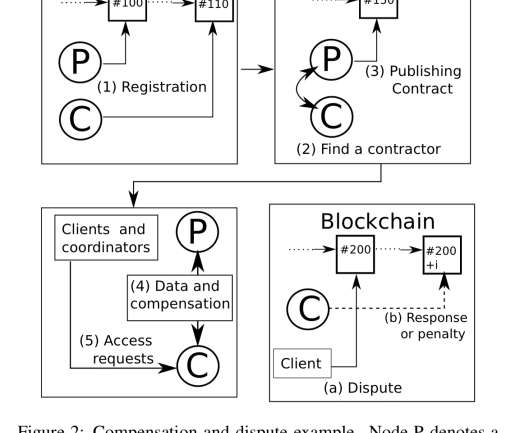
Our approach differs substantially by (1) providing economic incentives for data to be contributed and integrated into existing schemas, (2) offering a SQL interface instead of graph based approaches, (3) including the computational and storage infrastructure in the architectural vision. Coordinators that don’t want to pay contractors?
And of course, scrapers could scrape your site to look for security vulnerabilities or exposed contact or sales lead details. Search Engine And Web Archive Cached Results. Another common category of imposter domains are domains used by search engines for delivering cached results or archived versions of page views. Ad Scraping.
Here’s what Google suggests: PageSpeed Insights demonstrates how much storage and bandwidth websites stand to save with WebP. That’s why it’s no surprise that it’s developed a built-in WebP caching and image processing solution that helps developers more easily deliver the right file formats to visitors. What Is WebP Caching?
Alternatives to MongoDB Enterprise There are plenty of alternatives, but we’re not going to cover them all here, of course. Storing large datasets can be a challenge, as Redis’ storage capacity is limited by available RAM. Also, Redis is designed primarily for key-value storage and lacks advanced querying capabilities.
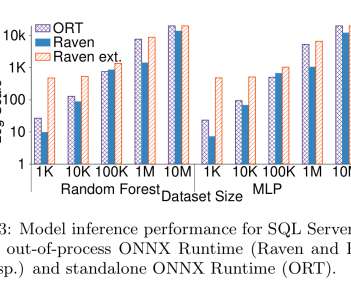
… based on interactions with enterprise customers, we expect that storage and inference of ML models will be subject to the same scrutiny and performance requirements of sensitive/mission-critical operational data. There are limitations to this model of course. It can’t handle loops for example (an analysis of 4.6M
The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. Traditional pointers address a memory location (often virtual of course). in front of that memory , as we saw last week). At least, the nature of pointers that we want to make persistent.
Of course, there are the SEO benefits of images, too. Instead, you can integrate your existing image server (on your web host) or external storage service (like S3) with ImageKit. However, once you integrate your images or image storage with ImageKit, the tool will take control of your image sizing.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. The L3 cache size is 64MB. The L3 cache size is 64MB. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0 lanes for I/O connectivity.
Chrome has missed several APIs for 3+ years: Storage Access API. An extension to Service Workers that enables browsers to present users with cached content when offline. It of course is personally frustrating to not be able to deliver these improvement for developers who wish to reach iOS users — which is all developers.
I've also used and helped develop many other technologies for debugging, primarily perf, Ftrace, eBPF (bcc and bpftrace), PMCs, MSRs, Intel vTune, and of course, flame graphs and heat maps. This diverse environment has always provided me with interesting things to explore, to understand, analyze, debug, and improve.
As with traditional storage, applications are writing to a shared storage environment which is necessary to support VM movement. It is the shared storage that often causes performance issues for data bases which are otherwise separated across nodes. The idea here is to simulate the two main storage workloads of a DB.
Hardware optimization : You need to ensure that the CPU, memory, and storage components meet the performance requirements of the database workload. Connection pooling: Minimizing connection overhead and improving response times for frequently accessed data by implementing mechanisms for connection pooling and caching strategies.
Consider costs : Multiple factors will, of course, affect how much you should budget. Depending on your setup, costs can include: Hardware devices (servers, storage devices, network switches, etc.) That will minimize problems that can occur when nodes share access to and the ability to modify the same memory or storage.
I’m not going to demonstrate it for space reasons, but if you change the column data type to the deprecated ntext type (which defaults to off-row LOB storage) or use sp_tableoption to store the nvarchar(max) data off-row, locks will be held for longer. This is true, of course, but there’s a bit more to say.
Add onto that the yawning chasm between low-end and high-end device performance thanks to chip design factors like cache sizes, and it can be difficult to know where to set a device baseline. Time required to read bytes from disk (it’s not zero, even on flash-based storage!). Time to execute and run our code.
Guest profiles also start with empty caches, empty cookie stores, empty browser storage, etc. These may get populated during testing, but we can clear them at any time via Application > Storage > Clear Site Data in DevTools. Opening a guest profile in Chrome 2.
MariaDB retains compatibility with MySQL, offers support for different programming languages, including Python, PHP, Java, and Perl, and works with all major open source storage engines such as MyRocks, Aria, and InnoDB. Stock MySQL has provided several storage engines beyond just InnoDB (the default) and MyISAM. Supported Engines.
Whether you're scaling storage solutions like S3 buckets, compute resources like EKS clusters, or content delivery mechanisms via CDNs, Terraform offers a streamlined approach.  â€Of course, the latter. Beyond just VM instances, this scalability extends to other aspects of your infrastructure.
Whether you're scaling storage solutions like S3 buckets, compute resources like EKS clusters, or content delivery mechanisms via CDNs, Terraform offers a streamlined approach. Of course, the latter. Transitioning between CDN providers or even changing CDN configurations can be tricky.
Network partitions of course can lead to violation of this guarantee. (G, Permanent redirection means that the client is able to cache the mapping between the shard and the node. This redirect is a one-time and should not be cached. In this article, we, of course, consider only a couple of applied techniques.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. Cliff Click : The JVM is very good at eliminating the cost of code abstraction, but not the cost of data abstraction.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Not as much as we'd like, of course, but the worldwide baseline has changed enormously. There are differences, of course, but not where it counts. The Moto G4 , for example.
An obvious metric here is CPU usage, but memory usage and other forms of data storage also play their part. I, for one, have typically added Google Analytics to every site I manage as a matter of course. I predominantly use Nginx, and I have a particular fondness for FastCGI cache and have found it to be especially efficient.
This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. Sean Larkin has a free course on Webpack: The Core Concepts and Jeffrey Way has released a fantastic free course on Webpack for everyone. Use progressive enhancement as a default.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content