This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the course of this post, we will talk about our approach to this migration, the strategies that we employed, and the tools we built to support this. This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI.
Of course writes were much less common than reads, so I added a caching layer for reads, and that did the trick. So in addition to all the optimization work we did for Google Docs, I got to spend a lot of time and energy working on the measurement problem: how can we get end-to-end latency numbers?
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. com , which introduces yet more latency for the connection setup.
The fact that this shows up as CPU time suggests that the reads were all hitting in the system cache and the CPU time was the kernel overhead (note ntoskrnl.exe on the first sampled call stack) of grabbing data from the cache. This means that there is no caching between RuntimeBroker.exe and this file.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
Tue-Thu Apr 25-27: High-Performance and Low-Latency C++ (Stockholm). On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.” If you’re interested in attending, please check out the links, and I look forward to meeting and re-meeting many of you there.
Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. ” Even re-reading that today, the letter of the law there is surprisingly strict to me: you can use the local memory space or filesystem as a brief single transaction cache, but no more.
It’s limited by the laws of physics in terms of end-to-end latency. We saw earlier that there is end-user pressure to replace batch systems with much lower latency online systems. We are observing significant demand from users in terms of avoiding batch telemetry pipelines altogether. Emphasis mine ). Emphasis mine ).
Prediction serving latency matters. Lesson 4: prediction serving latency matters. In a experiment introducing synthetic latency, Booking.com found that an increase of about 30% in latency cost about 0.5% Even mathematically simple models have the potential of introducing relevant latency.
These guidelines work well for a wide range of applications, though the optimal settings, of course, depend on the workload. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. have been released since then with some major changes.
Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. I’m going to update my referenced URL to the new site to help decrease latency that adds drag to the initial page load. Text-based assets. KB to 11.2
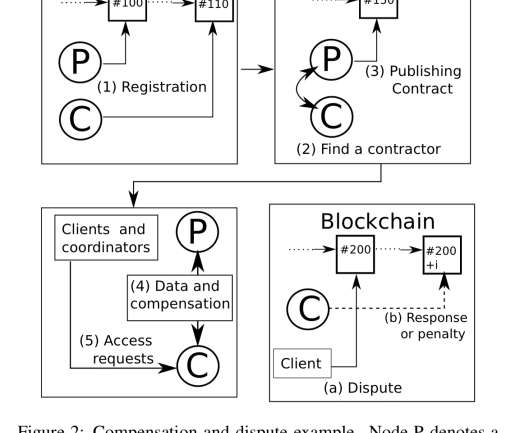
Caching of query results on the other hand, looks like a good business model, at large enough scale these might amount to pretty much the same thing). How’s that going to work given what we know about the throughput and latency of blockchains, and the associated mining costs?" An embodiment for structured data for IoT.
" Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
This, of course, is unless I can organize my products by country as well, which is a bit unusual nowadays but not impossible. One example could be using an RDBMS for most of the Online transaction processing ( OLTP) data shared by country and having the products as distributed memory cache with a different technology.
Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions. Opting for synchronous replication within distributed storage brings about reinforced consistency and integrity of data, but also bears higher expenses than other forms of replicating data.
The file size of your images of course is very important, but SEO and social media also play an important part in helping your website perform and convert better. KeyCDN’s Cache Enabler plugin is fully compatible the HTML attributes that make images responsive. jpg 480 KB 407 KB 43 KB 89% jpg-to-webp-2.jpg
This approach was touted to be better for fine-grained caching because each subresource could be cached individually and the full bundle didn’t need to be redownloaded if one of them changed. Finally, not inlining resources has an added latency cost because the file needs to be requested. Large preview ).
Platforms such as Snipcart , CommerceLayer , headless Shopify , and Stripe enable you to manage products in a friendly UI while taking advantage of the benefits of Jamstack: Amazon’s famous study reported that for every 100ms in latency, they lose 1% of sales. Of course the template approach is cheaper.
Alternatives to MongoDB Enterprise There are plenty of alternatives, but we’re not going to cover them all here, of course. Redis can handle a high volume of operations per second, making it useful for running applications that require low latency. Such organizations might seek a more straightforward alternative.
It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. Our baseline, then, should probably trade lower throughput/higher-latency for packet loss.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. This is why we have a distinction between HTTP (without TLS) and HTTPS (with TLS).
For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. An extension to Service Workers that enables browsers to present users with cached content when offline. Offscreen Canvas. Improves the smoothness of 3D and media applications by moving rendering work to a separate thread.
Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. in front of that memory , as we saw last week).
1:18pm a key observation was made that an API call to populate the homepage sidebar saw a huge jump in latency. There’s much more colour around these in the full thesis report of course). Members of the team begin diagnosing the issue using the #sysops and #warroom internal IRC channels. " – wikipedia.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously.
In such a case we have a Bandwidth heavy workload profile (reporting) sharing with a Latency Sensitive workload (transactional). The key thing to observe is the impact on the latency sensitive (OLTP) workload. The “Data” disks are doing both reads (from DB cache misses) and writes committed transactions.
The L3 cache size is 64MB. Of course, if I were buying an AMD-based server for on-premises SQL Server use right now, I would try to get the newer, frequency-optimized AMD EPYC 7371 processor. The L3 cache size is 64MB. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0 Memory (GiB).
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously.
A CDN will pull the GIF files from your origin server and cache them. This results in a reduction in distance travelled and therefore latency, as well as reduces the load on your origin server. Of course, web optimization is always about weighing costs and benefits.
Of course publishing it on Martin Fowler’s site was always going to get it to a wider audience (thanks Martin!), I also rewrote the section on Startup Latency since Cold Starts are one of the big “FUD” areas of Serverless. Because of course it did. Finally, of course, there’s the community section.
A pipeline breaker occurs when the output of one operator must be materialized to disk or transferred over the network, as opposed to being directly communicated from operator to operator via CPU cache, or, in the worst case, via RAM. Once a library of UDFs have been built up of course, they could be reused across computations.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
With just one click you can enable content to be distributed to the customer with low latency and high-reliability. Of course non-AWS origins are also permitted. Query String based Caching: the ability to include query string parameters as part of the objects cache key. Persistent Connection to Origins.
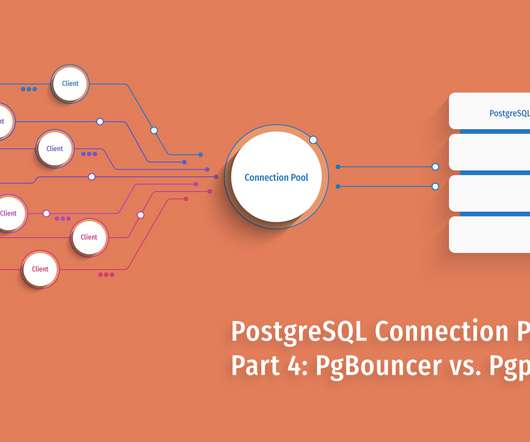
Also, note the test here was actually perfectly crafted for Pgpool-II – since when N > 32, the number of clients and number of children processes were the same, and hence, each reconnection was guaranteed to find a cached process. Patterns of data access would play a role, as would the latencies involved based on your architecture.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. Cliff Click : The JVM is very good at eliminating the cost of code abstraction, but not the cost of data abstraction.
Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth. Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). Two-way latency is often called round-trip time (RTT).
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Not as much as we'd like, of course, but the worldwide baseline has changed enormously. There are differences, of course, but not where it counts. The Moto G4 , for example.
The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency. Smaller microservices demonstrated much better instruction-cache locality than their monolithic counterparts. Hardware implications.
This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Thanks to Tim Kadlec, Henri Helvetica and Alex Russel for the pointers!
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Of course, your data might show that your customers are not on these devices, but perhaps they simply don’t show up in your analytics because your service is inaccessible to them due to slow performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content