This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Cache This is the easy one.
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. The batch job creates a high-level summary that captures some key comparison metrics.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. com , which introduces yet more latency for the connection setup.
ISPs do cache DNS however which means if your first provider goes down it will still try to query the first DNS server for a period of time before querying for the second one. Using a fast DNS hosting provider ensures there is less latency between the DNS lookup and TTFB. DNS speed comparison report Who offers the best free DNS?
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery. MongoDB makes use of both the filesystem cache and the WiredTiger internal cache. Compaction operation defragments data files & indexes.
The most obvious and common way this happens is when companies try to evolve their caches into a data platform that can, for example, be used as highly available enterprise key-value stores for volatile data. Let’s look at a typical scenario involving the javax cache API, also known as JSR107. How hard can it be?
Examples of this might be, expecting that the HTML is fully static, such that we can cache it downstream in some deterministic manner — “partially dynamic” HTML bodies are much more likely to be handled incorrectly by caching logic. Here are a few that come to mind: Is this request served from the service worker cache?
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. During load-balancing, the client gets the following exception when accessing the cache: ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later.
Quick summary : Node vs React Comparison is not correct because both technologies are entirely different things. Node JS vs. React JS Comparison. with its low latency I/O operations, gives the benefit of ‘No buffering’ to developers. Now, let us make a comparison between React and Node.js. Node JS vs. React JS Comparison.
For query executors that can be frequently started and stopped the authors explore performance with cold and warm caches (where applicable), and also the horizontal and vertical scaling performance. It is advantageous in the cloud to shut down compute resources when they are not being used, but there is then a query latency cost.
KeyCDN’s Cache Enabler plugin is fully compatible the HTML attributes that make images responsive. The main reason is because it decreases the latency to the user where they are located by serving your images from a POP physically closest to them. The Cache Enabler plugin then delivers WebP images based to supported browsers.
There are three generations of GPUs that are relevant to this comparison. The Hopper H100 was announced in 2022 and is the current volume product that people are using, so that is used as the baseline for comparison. The HGX H100 8-GPU system is the baseline for comparison, and its datasheet performance is shownbelow.
In comparison, for Linpack Frontier operates at 68% of peak capacity. I have always been particularly interested in the interconnects and protocols used to create clusters, and the latency and bandwidth of the various offerings that are available.
For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. An extension to Service Workers that enables browsers to present users with cached content when offline. Thankfully, the advent of M1 Macs makes it possible to remove hardware differences from comparisons.
This approach was touted to be better for fine-grained caching because each subresource could be cached individually and the full bundle didn’t need to be redownloaded if one of them changed. Finally, not inlining resources has an added latency cost because the file needs to be requested. Large preview ). What Does It All Mean?
Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. in front of that memory , as we saw last week).
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. HTTP/2 versus HTTP/3 protocol stack comparison ( Large preview ).
Cons of logical backups As it reads all data, it can be slow and will require disk reads too for databases that are larger than the RAM available for the WT cache—the WT cache pressure increases, which slows down the performance. Hence, the node would still be available for other operations.
It’s widely accepted that self-hosted fonts are the fastest option: same origin means reduced network negotiation, predictable URLs mean we can preload , self-hosted means we can set our own cache-control. On a high-latency connection, this spells bad news. Put another-other way, this file is latency-bound, not bandwidth-bound.
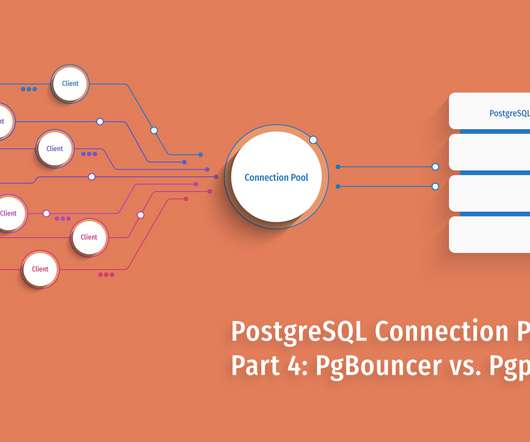
In our final post, we will put them head-to-head in a detailed feature comparison and compare the results of PgBouncer vs. Pgpool-II performance for your PostgreSQL hosting ! Patterns of data access would play a role, as would the latencies involved based on your architecture. PostgreSQL Connection Pooling Series.
Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth. Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). Two-way latency is often called round-trip time (RTT).
Given its unchanging nature, static content is ideal for caching. This type of traffic originates directly from the server, making it more challenging to handle due to latency and server load considerations; it’s hard but not impossible. It doesn’t change very often and is generally not affected by user sessions.
This type of traffic originates directly from the server, making it more challenging to handle due to latency and server load considerations; it’s hard but not impossible. Statistics reveal that a 1% improvement in latency can lead to a 3% increase in viewer engagement, highlighting its significance in live content delivery.3.
It also features a dual view interface that lets you see a before-and-after comparison. A CDN will pull the GIF files from your origin server and cache them. This results in a reduction in distance travelled and therefore latency, as well as reduces the load on your origin server.
Alternatively, you can also use Speed Scorecard (also provides a revenue impact estimator), Real User Experience Test Comparison or SiteSpeed CI (based on synthetic testing). Paddy Ganti’s script constructs two URLs (one normal and one blocking the ads), prompts the generation of a video comparison via WebPageTest and reports a delta.
To get a good first impression of how your competitors perform, you can use Chrome UX Report ( CrUX , a ready-made RUM data set, video introduction by Ilya Grigorik), Speed Scorecard (also provides a revenue impact estimator), Real User Experience Test Comparison or SiteSpeed CI (based on synthetic testing).
Build Optimizations JavaScript modules, module/nomodule pattern, tree-shaking, code-splitting, scope-hoisting, Webpack, differential serving, web worker, WebAssembly, JavaScript bundles, React, SPA, partial hydration, import on interaction, 3rd-parties, cache. Note that new CrUX datasets are released on the second Tuesday of each month.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content