This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? Caching them at the other end: How long should we cache files on a user’s device? Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one.
Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached. Reducing Code Complexity : We reduce a lot of code complexity in Counter Abstraction by delegating a major portion of the functionality to an existing service.
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. TCP: Establishing a reliable connection to the server.
Expensive requests such as expensive searches or inefficient application code, components, etc. Insufficient dispatcher caching. Lack of browser caching. Insufficient server sizing or incorrect architecture. Lack of proper maintenance. Lack of CDN. Too many scripts loaded on-page and loaded at top of the page.
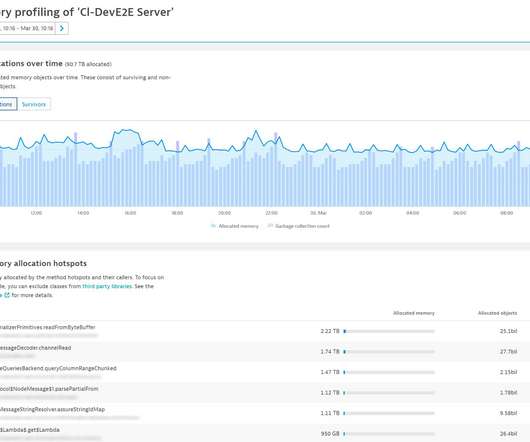
Optimize your code by finding and fixing the root cause of garbage collection problems. These details arm you with the knowledge necessary to find the respective code and remove unnecessary allocations. Any significant reduction in allocations will inevitably speed up your code. You can even look at the source code directly. .
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. Critical assets are far too valuable to leave on someone else’s servers. Penalty: Caching. Risk: Service Shutdowns.
You only need to write platform-specific code where it’s necessary, for example, to implement a native UI or when working with platform-specific APIs. Almost 50% of the production code in our Android and iOS apps is decoupled from the underlying platform. Debugging Kotlin source code from Xcode.
These include options where replay traffic generation is orchestrated on the device, on the server, and via a dedicated service. Moreover, allowing the device to execute untested server-side code paths can inadvertently expose an attack surface area for potential misuse.
Serverless architecture shifts application hosting functions away from local servers onto those managed by providers. This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Let’s get started. Serverless architecture: A primer. Application integration.
Reduce Transfer Size Broadly simplified… Web servers don’t send whole files at once—they chunk them into packets and send those. permitted the opening of multiple simultaneous connections to a server at once. Interestingly, 304 responses are still a form of redirect: the server is redirecting your visitor back to their HTTP cache.
Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Impacting Server-Side Requests: Dynatrace allows you to drill into your server-side requests to understand why your business logic is executing slow or fails. Well – there are many answers to this.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Browsers now understand the classic shared HTTP cache behaviour as a privacy bug.
A lot of people surmise that TTFB is merely time spent on the server, but that is only a small fraction of the true extent of things. TTFB isn’t just time spent on the server, it is also the time spent getting from our device to the sever and back again (carrying, that’s right, the first byte of data!). Expect closer to 75ms.
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. In the world of HTTP Headers, there is one header that I believe deserves more air-time and that is the Server-Timing header. Setting Server-Timing. Sean Roberts. 2022-05-16T10:00:00+00:00.
The Multicore Era Over the past ~15 years, server processors from Intel and AMD have evolved from the early quad-core processors to the current monsters with over 50 cores per socket. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
On the Android team, while most of our time is spent working on the app, we are also responsible for maintaining this backend that our app communicates with, and its orchestration code. Image taken from a previously published blog post As you can see, our code was just a part (#2 in the diagram) of this monolithic service.
This method involves providing the lowest level of access by default, deleting inactive accounts, and auditing server activity. For these, it’s important to turn off auto-completing forms, encrypt data both in transit and at rest with up-to-date encryption techniques, and disable caching on data collection forms.
When software runs in a monolithic stack on on-site servers, observability is manageable enough. While classic logging is an essential tool in debugging issues, it often lacks context and only provides snapshot information of one specific location in your code/application. Those are prime candidates for their own spans.
By Karthik Yagna , Baskar Odayarkoil , and Alex Ellis Pushy is Netflix’s WebSocket server that maintains persistent WebSocket connections with devices running the Netflix application. What if we wanted to move past Pushy’s pattern of delivering server-side messages? It served Pushy’s needs well for many years.
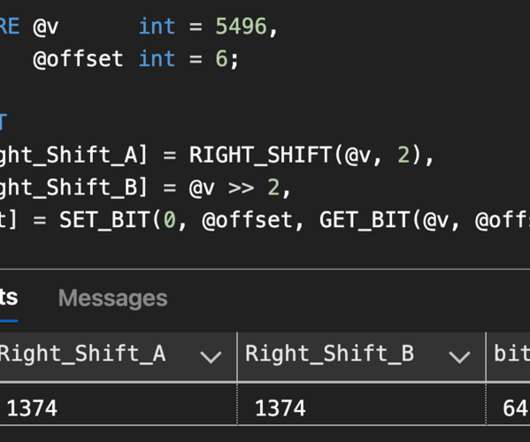
Even SQL Server stores some flag-based data using bitwise representation. Examples include the following: The set_options and required_cursor_options cached plan attributes, which you obtain using the sys.dm_exec_plan_attributes DMF. Setting the server configuration option “ user options” using bitwise representation.
Many projects have already chosen to upgrade and are enjoying the benefits of full React Suspense support and many other improvements, for advice on migrating your tRPC React client code you can follow TanStack Query's own migration guide. This enables you to build highly dynamic applications without suffering from server-client waterfalls.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Best of all, our page can load much faster since everything is cached in Elasticsearch. To act on the change, we need a GraphQL server that supports introspection.
With Lambda, you are charged based on the number of requests for your functions and their duration (the time it takes for your code to execute) with millisecond granularity. This gives operations teams specific answers to help prioritize and the root cause with end-to-end visibility down to the code level to resolve the problem.
Every unnecessary bit of JavaScript code you bundle and serve will be more code the client has to load and process. The resource loading waterfall is a cascade of files downloaded from the network server to the client to load your website from start to finish. How will you serve blazingly fast code, then? More after jump!
What if another file on the critical path had dropped out of cache and needed fetching from the network? We can take reasonable measures (always refresh from a cold cache; throttle to a constant network speed), but we can’t account for everything. What if we incurred a DNS lookup this time that we hadn’t the previous time?
Dependency agent Installation – Maps connections between servers and processes. Application Insights – Collects performance metrics of the application code. This requires the installation of an instrumentation package into the code making it a hands-on approach to monitoring. Hybrid and multi-cloud platform –.
Its raison d’être is to cache result rows from a plan subtree, then replay those rows on subsequent iterations if any correlated loop parameters are unchanged. Table-valued functions use a table variable, which can be used to cache and replay results in suitable circumstances. Spools are the least costly way to cache partial results.
I also compare them with stored procedures, mainly focusing on differences in terms of default optimization strategy, and plan caching and reuse behavior. Before implementing the function itself, here’s code to create a supporting index on the Sales.Orders table: USE TSQLV5 ; GO. CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.
One of the main benefits of GraphQL is the client’s ability to request what they need from the server and receive that data exactly and predictably. We’ll be learning how to do this with GraphQL Features like Cache Update, Subscriptions, and Optimistic UI. Let’s get right into the code. David Atanda. 2021-11-04T11:30:00+00:00.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Evaluating factors like hit rate, which assesses cache efficiency level, or tracking key evictions from the cache are also essential elements during the Redis monitoring process.
Get it wrong and you’re looking at sleepless nights, struggling to keep up with growth and fighting to keep your app available while you rewrite critical portions of your code. Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads.
Learn how to properly design RESTful APIs communication with clients, accounting for request structure, authentication, and caching. In this second part, we will talk in more detail about how the server should react to incoming requests with status codes. We are using the principles of RESTful architecture over HTTP.
Often the data is held in memory by consumers and used as a “total cache”, where it is accessed at runtime by client code and atomically swapped out under the hood. for example Open Connect Appliance cache configuration, supported device type IDs, supported payment method metadata, and A/B test configuration.
Creating A Magento PWA: Customizing Themes vs. Coding From Scratch. Creating A Magento PWA: Customizing Themes vs. Coding From Scratch. One of the reasons for that is because a PWA has the same code base. So unlike the case with native applications, the progressive web app needs to be coded only once. Alex Husar.
Without build optimizations (incremental builds, caching, we will get to those soon) this will eventually become unmanageable as well — think about going through all images in a website: resizing, deleting, and/or creating new files over and over again. Under the hood, it simplifies a lot of the work to the server-side.
You’ll also find example code or references to more specific guides so you can implement these tips to your PWA. The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. Cached content with IndexedDB. Skeleton screen examples on Code My UI.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Segmented Rendering is a new pattern for the Jamstack that lets you personalize content statically, without any sort of client-side rendering or per-request Server-Side Rendering. Like other similar UI libraries, React provides two ways of rendering content: client-side and server-side. CSR, SSR, SSG… Let’s Clarify What They Are.
The gRPC code is auto-generated from the gNMI protobuf model and gNMI carries the data modeled in OpenConfig, which has some encoding. We chose to build gnmi-gateway in Golang given the first-class support for protobufs in Go and that much of the existing reference code for gNMI exists in Golang.
The output of the code above would be the following: WeakMap {{…} => 'done'} man = null; console.log(human). The object is retained in memory and can be accessed with the following code: console.log(human[0]). let human = new WeakMap(): // Create an object, and assign it to a variable called man. It keeps the object in memory.
A website’s performance can make or break its success, yet in August 2020, despite many improvements we had previously made, such as implementing Server-Side Rendering (SSR), the ratio of Wix websites with good Google Core Web Vitals (CWV) scores was only 4%. Dan Shappir. 2021-11-22T10:30:00+00:00. 2021-11-22T11:06:56+00:00.
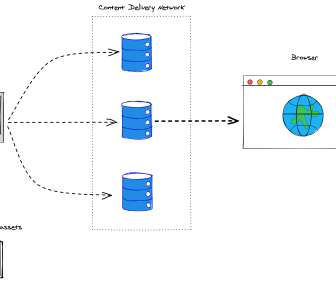
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. This speeds up accesses and updates while offloading back-end database servers.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. This speeds up accesses and updates while offloading back-end database servers.
Using high-fidelity metrics, logs, code-level tracing, and a dynamic topology map of your applications, Davis can identify the precise root cause and prioritize its business impact. Missing caching layers. Instead, it remains up to human experts to correlate and analyze the data in time-consuming war rooms. Reliability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content