This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Cache This is the easy one.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
Sustainable memory bandwidth using multi-threaded code has closely followed the peak DRAM bandwidth, typically delivering best case throughput of 75%-85% of the peak DRAM bandwidth in each generation. The example below is for a 2005-era processor with 60 ns memory latency and 6.4 Units of nanoseconds (ns) are most convenient.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. On a slower, higher-latency connection, the story is much, mush worse. Penalty: Caching. All completely avoidable.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. This can be set up with a couple of lines of code in your Spring Boot project. You can find all the details and sample code in our documentation.
It provides a good read on the availability and latency ranges under different production conditions. Adding forking logic and complexity to the device code can create dependencies on device application release cycles that generally run at a slower cadence than service release cycles, leading to bottlenecks in the migration.
Half of the time is instead spent on a cross-origin redirect — a separate HTTP request that returns a redirect response before we can even make the request that returns the websites HTML code. On a high-latency connection with a 150 millisecond RTT, making those eight round trips will take 1.2 2 HTTP requests: 2 round trips.
On the Android team, while most of our time is spent working on the app, we are also responsible for maintaining this backend that our app communicates with, and its orchestration code. Image taken from a previously published blog post As you can see, our code was just a part (#2 in the diagram) of this monolithic service.
As the scale of the messages being processed increased and we were making more code changes in the message processor, we found ourselves looking for something more flexible. In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered. It served Pushy’s needs well for many years.
The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache.
Examples of observability data include metrics, logs, and traces which provide visibility into the app’s behavior and performance at different levels of the stack, including the application code, infrastructure, and network. Load time and network latency metrics. Issue remediation. Performance optimization.
Using an interactive no/low code editor, you can create workflows or configure them as code. The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc.
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Of course writes were much less common than reads, so I added a caching layer for reads, and that did the trick. Then in 2008, Google issued a code yellow for application speed, and I was the code yellow lead for Google Docs. Leadership wanted to know the real page load times end users were experiencing.
Data lakehouses deliver the query response with minimal latency. Distributed tracing and code-level analysis technology like PurePath automatically integrates high-fidelity distributed tracing with user experience data and provides code-level analytics. Massively parallel processing.
Get it wrong and you’re looking at sleepless nights, struggling to keep up with growth and fighting to keep your app available while you rewrite critical portions of your code. Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. This can be set up with a couple of lines of code in your Spring Boot project. You can find all the details and sample code in our documentation.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. This can be set up with a couple of lines of code in your Spring Boot project. You can find all the details and sample code in our documentation.
Disclaimer: I didn’t find a solution, but I did find some crazy code. The fact that this shows up as CPU time suggests that the reads were all hitting in the system cache and the CPU time was the kernel overhead (note ntoskrnl.exe on the first sampled call stack) of grabbing data from the cache. Think about that for a moment.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?
Every unnecessary bit of JavaScript code you bundle and serve will be more code the client has to load and process. How will you serve blazingly fast code, then? Jamstack is popular with documentation sites that usually compile code to HTML files and host them on the CDN. Active Memory Caching. Caching Schemes.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Developers rely on the functionality of the relational database (not the application code) to enforce the schema and preserve the referential integrity of the data within the database. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
Cliff Click : The JVM is very good at eliminating the cost of code abstraction, but not the cost of data abstraction. That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. An AWS Lambda function is a simpler option that you can use, as it only requires you to code the logic, set it, and forget it.
Examples of non-timing information you could send: HTTP Response status code, regions, request ids, etc. This is how they offer drop-in monitoring of all requests being made without us needing to change our code to monitor a request. Code used to monitor resources (fetch, XHR, images, stylesheets, scripts, HTML, etc.)
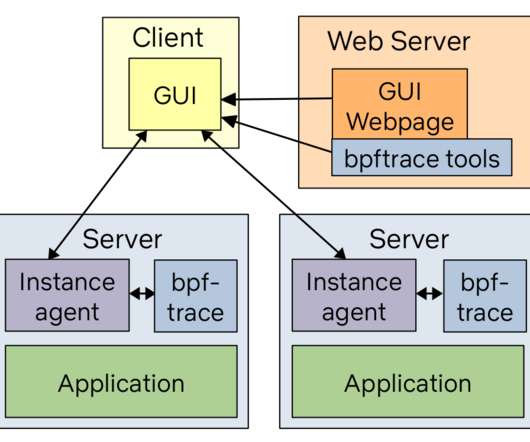
biolatency Disk I/O latency histogram heat map. cachestat File system cache statistics line charts. runqlat CPU scheduler latency heat map. This is thinking like a sysadmin who installs and maintains software, and not like a programmer who codes everything. as a traced function was renamed or a new code path added.
Sustainable memory bandwidth using multi-threaded code has closely followed the peak DRAM bandwidth, typically delivering best case throughput of 75%-85% of the peak DRAM bandwidth in each generation. The example below is for a 2005-era processor with 60 ns memory latency and 6.4 Units of nanoseconds (ns) are most convenient.
Tue-Thu Apr 25-27: High-Performance and Low-Latency C++ (Stockholm). On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.” If you’re interested in attending, please check out the links, and I look forward to meeting and re-meeting many of you there.
The most obvious and common way this happens is when companies try to evolve their caches into a data platform that can, for example, be used as highly available enterprise key-value stores for volatile data. Let’s look at a typical scenario involving the javax cache API, also known as JSR107. How hard can it be?
The code for the site is available on GitHub for reference. Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. This is a very basic site made with simple HTML, CSS, and JavaScript.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.
It’s limited by the laws of physics in terms of end-to-end latency. We saw earlier that there is end-user pressure to replace batch systems with much lower latency online systems. We are observing significant demand from users in terms of avoiding batch telemetry pipelines altogether. Emphasis mine ). Emphasis mine ).
We have spent a great deal of time at ScaleOut Software re-architecting our in-memory data grid (IMDG)’s code base to make best use of many cores and large memory. Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Please retry later.
That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. to understand YouTube video performance) drive tens of thousands of canned (known in advance) queries per second, that need to be served with latency in the tens of milliseconds.
Preventing code reuse across databases. This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. The same code is used for MySQL and PostgreSQL and can be used for other similar databases as well.
This prevents code reuse across databases. This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. The same code is used for MySQL and PostgreSQL and can be used for other similar databases as well.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content