This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We also see much higher L1 cache activity combined with 4x higher count of MACHINE_CLEARS. a usage pattern occurring when 2 cores reading from / writing to unrelated variables that happen to share the same L1 cache line. Cache line is a concept similar to memory page?—? Thread 0’s cache in this example.
Sustainable memory bandwidth using multi-threaded code has closely followed the peak DRAM bandwidth, typically delivering best case throughput of 75%-85% of the peak DRAM bandwidth in each generation. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications.
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Missing caching layers, e.g. provide a read-only cache for static data. Well – there are many answers to this.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
only to find that the resource they’re requesting isn’t in that PoP ’s cache. Application runtime: It’s kind of obvious really, but the time it takes to run your actual application code is going to be a large contributor to your TTFB. Routing: If you are using a CDN—and you should be!—a
Photo by Freepik Part of the answer is this: You have a lot of control over the design and code for the pages on your site, plus a decent amount of control over the first and middle mile of the network your pages travel over. For a myriad of reasons, older hardware can't always accommodate faster speeds. but couldn't find anything.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. <code> 127.0.0.1:6379> <code> 127.0.0.1:6379>
Apart from library code, maybe your application doesn't have frame pointers either, in which case everything is broken. Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. An AWS Lambda function is a simpler option that you can use, as it only requires you to code the logic, set it, and forget it.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency. ASPLOS’19.
First, its origin was in a monoculture (the browser) wher e there was no need for compatibility with legacy code. Unfortunately, languages like Python have proven resistant to efficient implementation, partly because of their design, and partly because of limitations imposed by the need to interop with C code. MICRO 15 , Gope et al.,
Hardware considerations The first thing we have to consider here is the resources that the underlying host provides to the database. Global caches like the InnoDB buffer pool and MyISAM key cache and session-level caches like the sort buffer, join buffer, random read buffer, etc. Do these queries use more caches?
Hardware error. We focus on software so much that we forget about the hardware failures. If the hardware gets disconnected or stops working then we cannot expect correct output from the software. Example: Printers and other hardware devices return bits of information that something is not right. Hardware issues.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
After 20 years of neck-in-neck competition, often starting from common code lineages, there just isn't that much left to wring out of the system. Enable developers to compress data efficiently without downloading large amounts of code to the browser. is access to hardware devices. Compression Streams. Keyboard Lock API.
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
” This contains updated and new material that reflects the latest C++ standards and compilers, with a focus to using modern C++11/14/17 effectively on modern hardware and memory architectures. On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
Cache-Headers missing? Where possible, remove unused JavaScript code or focus on only delivering a script that will be run by the current page. This approach is known as code splitting and is extremely effective in improving TTI. Service workers that will cache the bytecode result of a parsed and compiled script.
In this particular investigation, which spanned twenty months, we suspected hardware failure, compiler bugs, linker bugs, and other possibilities. Jumping too quickly to blaming hardware or build tools is a classic mistake, but in this case the mistake was that we weren’t thinking big enough.
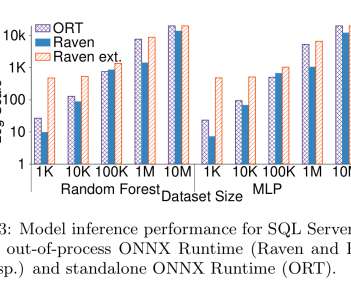
statement adds the source code for the model pipeline (Python in the example) to the database. A runtime code generator creates a SQL query incorporating all of these optimisations. For single or very small numbers of predictions, Raven is faster due to SQL Server’s caching. An INSERT INTO model. categorical encoding).
Sustainable memory bandwidth using multi-threaded code has closely followed the peak DRAM bandwidth, typically delivering best case throughput of 75%-85% of the peak DRAM bandwidth in each generation. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. Microarchitectural channels. There are also stateless interconnects including buses and on-chip networks. Threat scenarios. IPC) input and output channels.
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. Cached vs Scaled Workloads.
More specifically, we’re going to talk about storage and UI differences, which are the ones that most often cause confusion to developers when writing Flutter code that they want to be cross-platform. Running Different Code On Different Platforms. In this article, we’re going to see some of those differences and how to overcome them.
Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? Interacting components in the execution of an MPI job — a brief outline (from memory): The user source code, which contains an ordered set of calls to MPI routines.
Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? Interacting components in the execution of an MPI job — a brief outline (from memory): The user source code, which contains an ordered set of calls to MPI routines.
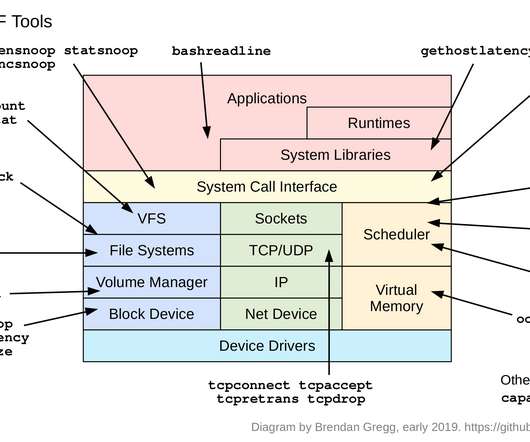
It was created by Alastair Robertson, a talented UK-based developer who has previously won various coding competitions. hardwareHardware counter-based instrumentation. Hence static instrumentation, where event points are hard-coded and become a stable API. tracepoint Kernel static instrumentation points. bashreadline.bt
A wide range of users with different operating systems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. Some APM solutions can monitor code during development to ensure performance. What is real user monitoring (RUM)? Usage performance.
It’s one of the things we look at during a health audit, and Kimberly has a great query from her Plan cache and optimizing for adhoc workloads post that’s part of our toolkit. About 1GB of the plan cache is for prepared and procedure plans, and they only take up about 300MB worth of space. DBCC FREEPROCCACHE ; GO. EXEC dbo. [
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. What about security?
For this page to be done loading it needs to be responsive to user input — the “interactive” in “Time to Interactive” Browsers process user input by generating DOM events that application code listens to. The gzip compression factor for JS code is between 5x and 7x. Execute the script.
According to the article “ When Women Stopped Coding “, the percent of women in Computer Science 30 years ago was nearly twice what it is now. Hardware engineers design and implement solutions in RTL, while software engineers attempt to solve the problem either at the OS or application level.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
how much data does the browser have to download to display your website) and resource usage of the hardware serving and receiving the website. This represents a relatively meager saving, but by establishing a philosophy of pruning unwanted code and requests from our pages, we can make much more significant performance improvements.
So consider the dense matrix multiplication operation C += A*B, where A, B, and C are dense square matrices of order N, and the matrix multiplication operation is equivalent to the pseudo-code: for (i=0; i<N; i++) { for (j=0; j<N; j++) { for (k=0; k<N; k++) { C[i][j] += A[i][k] * B[k][j]; } } }.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
My VirtualScan program just called NtQueryVirtualMemory in the obvious loop to scan the address space of a specified process, the code worked, it took a really long time to scan the gmail process (10-15 seconds), and it triggered the hang. MiB, 32112, 98 code blocks. The CFG memory block is best thought of a cache with bounded size.
My development collogues and I are starting a regular blog series, outlining the vast range of scalability improvements, allowing SQL Server 2016 to run across a wide array of hardware configurations, faster and better than previous releases of SQL Server. The following table is taken from an ASP.NET, session state cache, stress test.
An example of a specification is the correct operation of the hardware of a microprocessor. An example protection technique that can provide this capability is an Error Correcting Code (ECC). An SDC is the worst possible outcome of a fault, as it can have an arbitrary impact on the correctness of software running on the hardware.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content