This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Break data silos and add context for faster, more strategic decisions : Unifying metrics, logs, traces, and user behavior within a single platform enables real-time decisions rooted in full context, not guesswork. Generative AI enhances response speed and clarity, accelerating incident resolution and boosting team productivity.
Our latest enhancements to the Dynatrace Dashboards and Notebooks apps make learning DQL optional in your day-to-day work, speeding up your troubleshooting and optimization tasks. Next, let’s use the Kubernetes app to investigate more metrics.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward. The result?
In this blog series, we’ll guide you through creating powerful dashboards that transform complex data into actionable insights. In our next blog post, we’ll further enhance this dashboard with AI and increase its visual appeal and usability. To find the metric, go to the Explore section on the data tab.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Dynatrace has recently enhanced its Metrics APIs, allowing everyone to send any type of metric with any set of data dimension to Davis, Dynatrace’s AI engine. In our conversation, I mentioned the new Dynatrace Metrics ingestion and off we went. ?? There are many use cases for using this API.
Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well. Ensure better user experience with paint-focused performance metrics. These metrics are tightly connected to the perceived load speed of your application.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
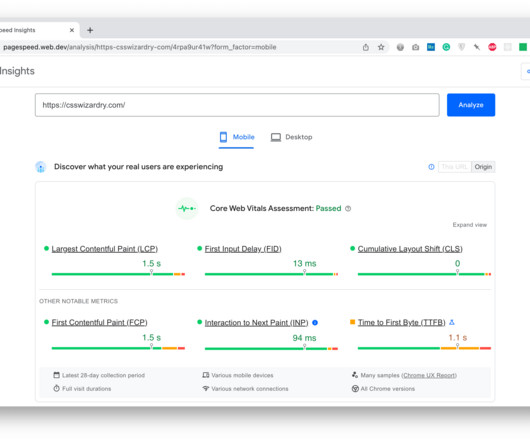
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
This is an announcement for the OneAgent version 1.171 release: you may see a change in Visually complete and Speed index calculation once you upgrade to OneAgent 1.171. The Visually complete metric measures the time it takes for the visible portion of a web application to fully render on your end-users’ device screens. Implications.
This tech blog highlights our recent progress toward this goal. VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. For more background information, interested readers may refer to our first and second tech blogs on VMAF. animation vs. documentary).
Dynatrace Visually complete is a point-in-time web performance metric that measures when the visual area of a page has finished loading. Dynatrace is the only solution that provides these user experience metrics consistently for real user monitoring as well as for synthetic monitors. More precisely, you can now: . What you can achieve.
In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
Google do strongly encourage you to focus on site speed for better performance in Search, but, if you don’t pass all relevant Core Web Vitals (and the applicable factors from the Page Experience report) they will not push you down the rankings. While Core Web Vitals can help with SEO, there’s so much more to site-speed than that.
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. Therefore, many organizations turn to a data lakehouse, which combines the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. Learn more.
Custom data buckets for faster queries, increased control, and custom retention periods The first layer in the Grail data model consists of buckets and tables (and views for entities, which is outside this blog post’s scope). This improves query speeds and reduces related costs for all other teams and apps.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. – blog.
Serverless functions extend applications to accelerate speed of innovation. Full integration with existing Dynatrace capabilities for AWS Lambda (for example, metric ingestion via AWS Cloud Watch). Fully integrated with existing Dynatrace capabilities for AWS Lambda, including metric ingestion via AWS Cloud Watch.
As a full stack monitoring platform, Dynatrace collects a huge number of metrics for each OneAgent monitored host in your environment. Depending on the types of technologies you’re running on your individual hosts, the average number of metrics is about 500 per computational node. New metric identifiers and structure.
You can, for example, drive ad hoc multidimensional analysis to analyze, chart, and report on microservice-based metrics without code changes. You can use powerful dashboard capabilities to visualize whatever metrics are most relevant to your teams and let the Davis AI causation engine automatically identify the root cause of problems.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed. Thus, Grail was born.
The scale and speed of the program triggered challenges for these banks that they had never before imagined. Speed up loan processing to deliver critically needed relief to small businesses? Full speed ahead. The post Billion-dollar problem solved through 21-day digital transformation appeared first on Dynatrace blog.
Observability requires complete access to metrics, traces, and logs. OpenTelemetry is an open source standard for gathering observability signals, including metrics, traces, and logs. Overall, the survey identified three key market trends affecting observability. . 1: Observability is more of an attribute than a process .
framework , the SNMP extensions are a bundle of everything that’s needed (DataSource configuration, a dashboard template, a unified analysis page template, topology definition, entity extraction rules, relevant metric definitions and more) to get going with monitoring. As with other extensions based on the new Dynatrace Extensions 2.0
But this is hard to achieve at scale: Development teams need specific insights into the microservices they are responsible for, reflecting particular metrics, dashboards, custom alerts, service-level objectives (SLOs), or even automatic remediation steps. , or “Did the last update cause the application issue or was it something else?”
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. This is what this blog is all about. Its a detailed tutorial blog that explains how you can make the first steps towards SLI/SLO-based Quality Gates. For this blog I will be using the same Node.js
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
The theme for the event focused on ‘APM to Observability’, which we’ll recap shortly within this blog. And for observability to be successful, it requires much more than just logs, metrics, and traces. Figure 4 How Dynatrace enriches metrics, traces, and logs to identify problems with precise root cause analysis.
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. Enable the Davis AI causation engine to automatically analyze every metric.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Check out the on-demand Power Demo, Dynatrace and Business Observability: Tying IT Metrics to Business Outcomes. appeared first on Dynatrace blog.
Step 4: Identify key metrics to use as service-level indicators (SLIs). Work with your SRE and Operations teams to understand what key metrics your observability platform provides and which ones you would need to track. Either way, alerts should route to the right team or individual to speed up triaging issues and reduce MTTR.
To measure service quality, IT teams monitor infrastructure, applications, and user experience metrics, which in turn often support service level objectives (SLO)s. But these metrics and SLOs are only indirectly connected to business KPIs, which often leads to misplaced priorities, ineffective collaboration, and lost business opportunities.
Metrics and Logs : You can enable the collection of metrics and logs for Virtual Machine (VM) and App Services resources by installing Dynatrace OneAgent on those resources. Automatic collection of metrics and logs. Furthermore, you can activate the sending of Azure subscription activity logs and resource logs to Dynatrace.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). In the workshop, I also answered the question: How can we measure those metrics (=SLIs) that are behind our objectives?
Today, the speed of software development has become a key business differentiator, but collaboration, continuous improvement, and automation are even more critical to providing unprecedented customer value. Dynatrace’s version awareness allows you to stay in control despite speeding up application delivery.
The complexity of such deployments has accelerated with the adoption of emerging, open-source technologies that generate telemetry data, which is exploding in terms of volume, speed, and cardinality. All Dynatrace enhancements mentioned in this blog post will be available within the next 90 days. Next steps.
Kafkas proprietary protocol is optimized for high-speed data transfer, ensuring minimal latency and efficient message distribution. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations.
Traditional monitoring systems cannot keep up with the speed of change in those highly dynamic large-scale container environments. These enhancements include: Integration of the new Kubernetes/OpenShift cluster metrics with custom charting. Universal container-level metrics for resource contention analytics.
This guest blog is authored by Raphael Pionke , DevOps Engineer at T-Systems MMS. I, Andreas Grabner, helped to bring the blog to life! While the test step, use case, and thread group name context are helpful we also want to speed up the analysis of individual requests that fail. Dynatrace news.
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Watch webinar now!
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Lastly, we’re working on a ready-made dashboard for the DORA metrics based on GitHub and ArgoCD metadata.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content