This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. In this blog, we will focus on histograms and why to use them. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. What are histograms, and why use them?
In this blog post, we look at these enhancements, exploring methods for monitoring your Kubernetes environment and showcasing how modern dashboards can transform your data. Next, let’s use the Kubernetes app to investigate more metrics.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023. What’s ahead in 2023.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. If you’ve read about observability, you likely know that collecting the measurements of logs, metrics, and distributed traces are the three key pillars to achieving success.
In a recent blog post, we announced and demonstrated how the new Distributed Tracing app provides effortless trace insights. Conclusion In this blog post, we explored how the Distributed Tracing app can be harnessed to visualize data ingested from the OpenTelemetry collector to get an overview of application health.
In this blog series, we’ll guide you through creating powerful dashboards that transform complex data into actionable insights. In our next blog post, we’ll further enhance this dashboard with AI and increase its visual appeal and usability. To find the metric, go to the Explore section on the data tab.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
With the most important components becoming release candidates , Dynatrace now supports the full OpenTelemetry specification on all runtimes and automatically adds intelligence to metrics at enterprise scale. So these metrics are immensely valuable to SRE and DevOps teams. Automation and intelligence for metrics at enterprise scale.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Automate smarter using actual customer experience metrics, not just server-side data. Follow the “Dynatrace for Executives” blog series.
I used to work at another Observability vendor, and many of the OpenTelemetry examples that I played with and blogged about in the last 2 years or so featured sending OTel data to that backend. Theres a time and place for each, and you can check out my blog post on OTel Collector Anti-patterns on the OTel Blog to learn more.
This is the second in a series of blogs discussing unified observability with microservices and the Oracle database. This second blog will take a deeper dive into the Metrics, Logs, and Tracing exporters (which can be found at [link] ), describing them and showing how to configure them, Grafana, alerts, etc.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Within the target pipeline, you can also define processing rules, extract metrics, set the security context, and define retention periods. Now’s the time to see how it can benefit your organization.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. I was pulled into that troubleshooting call and started taking notes and screenshots so I can share how easy it is to troubleshoot the Kubernetes workload with our engineers and you – our readers – on this blog post. Dynatrace news.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Have a look at our recent Davis CoPilot blog post for more information and practical use cases. Your trained eye can interpret them at a glance, a skill that sets you apart.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. This blog post is part of our series on Tailored access management.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
The Carbon Impact app directly supports our customers sustainability efforts through granular real-time emissions reporting and analytics, translating host utilization metrics into their CO2 equivalent (CO2e). Youll be able to read more about our approach to cloud cost optimization in an upcoming blog post.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
All metrics, traces, and real user data are also surfaced in the context of specific events. With Dynatrace, you can create custom metrics based on user-defined log events. Also depicted is Dynatrace instrumentation of the pods that deliver metrics and trace data to the Dynatrace environment.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Logs, metrics, and traces make up the bulk of all telemetry data. The data life cycle has multiple steps from start to finish.
To calculate the service-level indicator for the Kubernetes namespace memory efficiency SLO, simply query the memory working set and request the memory metrics that are provided out of the box. However, if you require more granular information, you can adjust the levels for resource utilization monitoring accordingly.
We also explore how to improve user experiences within the Zero Trust framework and how to develop security metrics that eliminate DevSecOps bottlenecks. Episode 40 – Security Metrics: Measure Twice, Cut Once with Rick Stewart. Security Metrics: Measure Twice, Cut Once with Rick Stewart. appeared first on Dynatrace blog.
While histograms look much like time-series bar charts, they’re different in that each bar represents a count (often termed frequency) of metric values. We will release another dedicated blog post in the next few days. That way, you can compare multiple charts more easily, regardless of the metric or time span.
The post Identify issues immediately with actionable metrics and context in Dynatrace Problem view appeared first on Dynatrace blog. To learn more about how Dynatrace can help optimize your user experiences across mobile, web, IoT, and APIs, visit Dynatrace Digital Experience Monitoring (DEM) or sign up for a 15-day free trial.
Dynatrace currently supports the following: Traces Logs Metrics What information do I need to send OpenTelemetry data to Dynatrace? Does Dynatrace support OpenTelemetry metrics? Yes, but its important to note the following: Dynatrace requires metrics data to be sent with delta temporality and not cumulative temporality.
Read on for links to blog posts that highlight the key benefits you get with our next-generation AI causation engine. These blog posts, published over the course of this year, span a huge feature set comprising Davis 2.0, detects suspicious metric behavior by analyzing the value distribution of metrics.
Particularly during the COVID-19 pandemic, we’ve seen how poor application performance can impact business bottom lines and lead to lost revenue for many organizations, as laid out in our recent blog post about digital experience. with: Aggregated field metrics?rather?than?valuable?details Metrics and recommendations?rather
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
This blog post will share broadly-applicable techniques (beyond GraphQL) we used to perform this migration. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render.
In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
Check out the following related resources to learn more: Enhancing Duet AI for Developers through our partner ecosystem – Google blog Learn more about the powerful synergy that revolutionizes the cloud landscape when integrating Dynatrace observability with Vertex and Duet AI. Learn more.
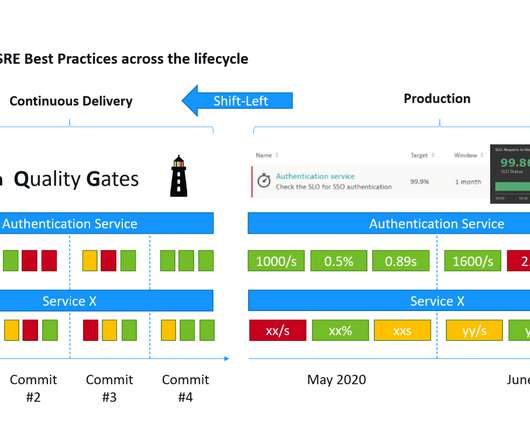
In this blog, I want to dig a bit into a core capability of Keptn which is used across all use cases: SLI/SLO-based Evaluations for Quality Gates as well as Auto-Remediation. While an SLI is just a metric, an SLO just a threshold you expect your SLI to be in and SLA is just the business contract on top of an SLO.
This followed a previous blog on the same topic. Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. Try it athome It couldnt be easier to get started with Configs!Just
For example, you might be using: any of the 60+ StatsD compliant client libraries to send metrics from various programming languages directly to Dynatrace; any of the 200+ Telegraf plugins to gather metrics from different areas of your environment; Prometheus, as the dominant metric provider and sink in your Kubernetes space.
This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal. The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels.
In this blog post, we’ll examine one such case where we use the Sentry JavaScript SDK to instrument Jest (which runs our frontend test suite) and how we addressed the issues that we found. We have high-level metrics for how well (or not) our CI is performing.
The previous blog post in this series discussed the benefits of implementing early observability and orchestration of the CI/CD pipeline using Dynatrace. This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. Why reliability?
Davis AI contextually aligns all relevant data points—such as logs, traces, and metrics—enabling teams to act quickly and accurately while still providing power users with the flexibility and depth they desire and need. This is explained in detail in our blog post, Unlock log analytics: Seamless insights without writing queries.
How we define auto-adaptive thresholds at Dynatrace This blog post explores how Dynatrace leveraged the Site Reliability Guardian to establish a fast feedback loop for Davis AI model improvements. Our data scientists utilize metrics and events to store these quality metrics.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. This blog post will delve into the techniques leveraged at Netflix to introduce these changes to production.
The ops team understood the concept of business metrics like NPS, conversions rates, even call center volume—but believed these KPIs were meant for other teams. Similarly, IT’s solid SLOs and Apdex scores—important metrics agreed upon by the app owner and IT—were met with a lack of enthusiasm by the business team.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content