This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This leads to an increase in the size of data as well. Bigdata is generated and transported using various mediums in single requests. With the increase in the size of data, we have activities like serializing, deserializing, and transportation costs added to it. We need to cut down on transportation.
From driver and rider locations and destinations, to restaurant orders and payment transactions, every interaction on Uber’s transportation platform is driven by data.
The sidecar has been implemented by leveraging the highly performant eBPF along with carefully chosen transport protocols to consume less than 1% of CPU and memory on any instance in our fleet. The choice of transport protocols like GRPC, HTTPS & UDP is runtime dependent on characteristics of the instance placement.
In the push model paradigm, various platform tools such as the datatransportation layer, reporting tools, and Presto will publish lineage events to a set of lineage related Kafka topics, therefore, making data ingestion relatively easy to scale improving scalability for the data lineage system.
Bigdata : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch. The data covers the period of January 2021 through September 2022. The report only includes production data from Dynatrace customers and excludes all Kubernetes clusters Dynatrace uses internally or for hosting SaaS offerings.
However, it is paramount that we validate the complete set of identifiers such as a list of movie ids across producers and consumers for higher overall confidence in the datatransport layer of choice.
AWS is helping them reach their goal of becoming the leader in sustainable transport. Scania is planning to use AWS for their connected vehicle systems, which allows truck owners to track their vehicles, collect real-time running data, and run diagnostics to understand when maintenance is needed to reduce vehicle downtime.
AdiMap uses Amazon Kinesis to process real-time streaming online ad data and job feeds, and processes them for storage in petabyte-scale Amazon Redshift. Advanced problem solving that connects bigdata with machine learning. warehouses to glean business insights for jobs, ad spend, or financials for mobile apps.
Shell leverages AWS for bigdata analytics to help achieve these goals. Shell''s IT shop has to figure out how to drive costs down, effectively manage the giant files and make it profitable for the company to deploy these sensors.
In the era of bigdata and complex data processing, data pipelines have emerged as a popular solution for managing and manipulating data. They provide a systematic approach to extract, transform, and load (ETL) data from various sources, enabling organizations to derive valuable insights.
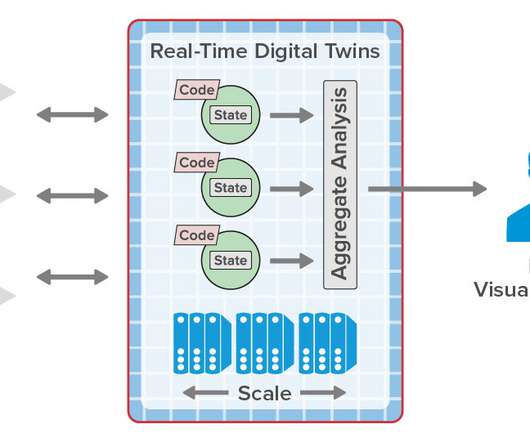
Rapid advances in the telematics industry have dramatically boosted the efficiency of vehicle fleets and have found wide ranging applications from long haul transport to usage-based insurance. Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks.
The rise of BigData - the ability to store and analyze large volumes of structured and unstructured, internal and external data - promises to let companies react more nimbly than ever before. The trend is likely to spread as industries from commercial farming to transportation become dominated by software.
Data Pipeline using Delta In the following sections, we are going to describe the Delta-Connector that connects to a datastore and publishes CDC events to the Transport Layer, which is a real-time datatransportation infrastructure routing CDC events to Kafka topics. In addition, we support Cassandra (multi-master).
More than 20% of the goods will be made, packaged, transported, delivered without any external touch or effect. of companies invest over US$ 50 million in initiatives such as Artificial Intelligence (AI) and BigData in 2020, up from 39.7% By 2025, the person who orders the product will first be the person who touches it.
Also hear from AWS customer Cargill, who shares their data journey and how they built Jarvis, which helps optimization of carbon emissions associated with ocean transportation and uses gen AI to enable faster decision-making. Discover how Scepter, Inc.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content