This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When handling large amounts of complex data, or bigdata, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Greenplum features a cost-based query optimizer for large-scale, bigdata workloads. Query Optimization.
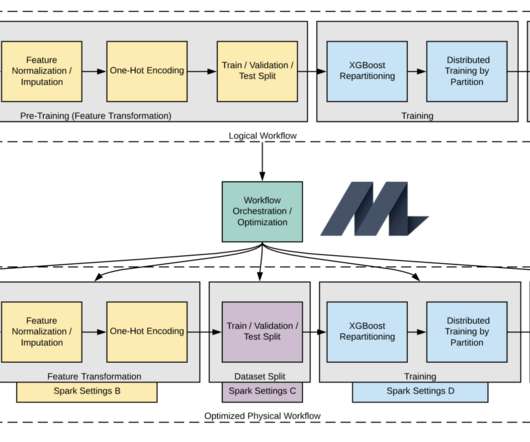
Michelangelo , Uber’s machine learning (ML) platform, powers machine learning model training across various use cases at Uber, such as forecasting rider demand , fraud detection , food discovery and recommendation for Uber Eats , and improving the accuracy of … The post Productionizing Distributed XGBoost to Train Deep Tree Models with Large (..)
AI that is based on machine learning needs to be trained. This requires significant data engineering efforts, as well as work to build machine-learning models. This kind of automation can support key IT operations, such as infrastructure, digital processes, business processes, and big-data automation.
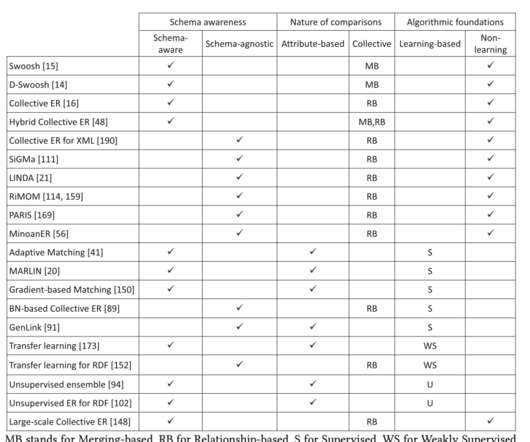
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. Learning-based methods train classifiers for pruning. ACM Computing Surveys, Dec. 2020, Article No.
Artificial intelligence for IT operations, or AIOps, combines bigdata and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. It works without having to identify trainingdata, then training and honing. A huge advantage of this approach is speed.
We also use Python to detect sensitive data using Lanius. Orchestration The BigData Orchestration team is responsible for providing all of the services and tooling to schedule and execute ETL and Adhoc pipelines. These libraries are the primary way users interface programmatically with work in the BigData platform.
Gartner defines AIOps as the combination of “bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” They require extensive training, and real-user must spend valuable time filtering any false positives. What is AIOps?
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., Microsoft’s bigdata clusters have 10s of thousands of machines, and are used by thousands of users to run some pretty complex queries. Creating training datasets for machine learning ! VLDB’19.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. In particular, we use a simple Feedforward Multilayer Perceptron (MLP) with two heads, one to predict each outcome.
I bring my breadth of bigdata tools and technologies while Julie has been building statistical models for the past decade. A lot of my learning and training was self-guided until 2016, when a manager at my last company took a chance on me and helped me make the rare transfer from a role in HR to Data Science.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
With the launch of the AWS Europe (London) Region, AWS can enable many more UK enterprise, public sector and startup customers to reduce IT costs, address data locality needs, and embark on rapid transformations in critical new areas, such as bigdata analysis and Internet of Things. Fraud.net is a good example of this.
Democratizing data consumption Democratizing data consumption means making data available and accessible. While many employees are familiar with IT processes, few are traineddata practitioners. Observability platforms make it possible to capture and contextualize data, creating a shared foundation for staff.
automatic speech recognition, natural language understanding, image classification), collect and clean the trainingdata, and train and tune the machine learning models. Effectively applying AI involves extensive manual effort to develop and tune many different types of machine learning and deep learning algorithms (e.g.
IPS enables users to continue to use the data processing patterns with minimal changes. Introduction Netflix relies on data to power its business in all phases. As our business scales globally, the demand for data is growing and the needs for scalable low latency incremental processing begin to emerge. append, overwrite, etc.).
Each time, the underlying implementation changed a bit while still staying true to the larger phenomenon of “Analyzing Data for Fun and Profit.” ” They weren’t quite sure what this “data” substance was, but they’d convinced themselves that they had tons of it that they could monetize.
Seer: leveraging bigdata to navigate the complexity of performance debugging in cloud microservices Gan et al., A DNN model is trained to recognise patterns in space and time that lead to QoS violations. This retraining uses transfer learning with weights from previous training rounds stored on disk as a starting point.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Using local SSDs inside of the GPU node delivers fast access to data during training, but introduces challenges that impact the overall solution in terms of scalability, data access, and data protection.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
We believe that with the launch of the Seoul Region, AWS will enable many more enterprise customers in Korea to reduce the cost of their IT operations and innovate faster in critical new areas such as bigdata analysis, Internet of Things, and more. Many of these enterprises are assisted by our extensive partner ecosystem in Korea.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
You’ll have access to training including hands-on bootcamps and labs, and 1:1 sessions with AWS Solutions Architects. Topics include Introduction to AWS, BigData, Compute & Networking, Architecture, Mobile & Gaming, Databases, Operations, Security, and more. AWS Technical Bootcamps.
The diversity of products demands that we employ modern regression techniques like trained random forests of decision trees to flexibly incorporate thousands of product attributes at rank time. Driving down the cost of Big-Data analytics. The end result of all this behind-the-scenes software? Spot Instances - Increased Control.
We also provided web-based training, self-paced labs, customer support, third-party offers, and up to $100,000 in AWS service credits–all at no charge. The first platform is a real time, bigdata platform being used for analyzing traffic usage patterns to identify congestion and connectivity issues.
It became a great success; every time when I visit the loft there is a great buzz with people getting advice from our solution architects, getting training or attending talks and demos. Usually these cost $600, but at the AWS Pop-up Loft we are offering them for free.
big-data processing, machine learning, quantum computing, and so on). Her current work focuses on hardware/software co-design for extremely large-scale deep learning training. Computer architecture is an important and exciting field of computer science, which enables many other fields (eg.
can be estimated by means of classification and regression models trained on historical data for customers who have received incentives in the past and those who did not. Propensity models are regression and classification models trained on customer data. The analysis of principal regressors can suggest customer segments.
We found that the biggest struggle for developers working with new tools is training (34%), and another 12% said the biggest struggle is “ease of use.” But 20% are changing their onboarding and upskilling processes, 15% are hiring new developers, and 13% are using self-service engineering platforms.
For this purpose the data is collected, analyzed, and a data set is created for the algorithm. A part of this data will act as the trainingdata for the spam detection algorithm and the other part will be used as test data. Machine learning and BigData are driving the major industry decisions today.
Examples are DevOps, AWS, BigData, Testing as Service, testing environments. It becomes necessary to provide them with proper training and knowledge to be a perfect fit for starting cloud testing. People: What people in the team will need to quickly adapt to cloud testing by learning new technologies.
With new cryptographic techniques that can enable analysis on the data without actually “seeing” it, data may one day be accessible outside of the corporate silos in which it currently resides. Today, we freely give data, content, and other forms of value in exchange for the use of “free” products. Where does change begin?
Heterogeneous and Composable Memory (HCM) offers a feasible solution for terabyte- or petabyte-scale systems, addressing the performance and efficiency demands of emerging big-data applications. However, building and utilizing HCM presents challenges, including interconnecting various memory technologies (e.g.,
You can review call recordings, identify areas for improvement, and train your staff to serve your customers better. Moreover, the data collected by the app can help you understand customer pain points and preferences. Data-Driven Decision Making In the age of bigdata, data-driven decision-making is paramount.
The conference kicks off next week on Wednesday February 21st with Training Days and lasts through Saturday, February 24th. Best practices on Building a BigData Analytics Solution – Michael Rys. If you want to learn about Azure Data Lake, there is no one better. SELECT * FROM Azure Cosmos DB – Andrew Liu.
In this year's CFP we’re looking for topics covering the latest trends and best practices in cloud computing, containerization, machine learning, bigdata, infrastructure, scalability, DevOps, IT management, automation, reliability, monitoring, performance tuning, security, databases, programming, datacenters, and more.
In this year's CFP we’re looking for topics covering the latest trends and best practices in cloud computing, containerization, machine learning, bigdata, infrastructure, scalability, DevOps, IT management, automation, reliability, monitoring, performance tuning, security, databases, programming, datacenters, and more.
In the age of big-data-turned-massive-data, maintaining high availability , aka ultra-reliability, aka ‘uptime’, has become “paramount”, to use a ChatGPT word. Keep it simple Thanks to the magic of open-source and hyperscalers, it’s very easy to rapidly assemble a system from a large number of third-party components.
It’s difficult to detect if someone on a desktop is on a broadband connection or is tethering through a data-limited dongle or mobile. Many people work on the train like that, or live in an area where broadband infrastructure is poor but mobile signal is strong.
Bigdata, web services, and cloud computing established a kind of internet operating system. When there’s a breakthrough that puts advanced computing power into the hands of a far larger group of people, yes, ordinary people can do things that were once the domain of highly trained specialists.
We already have an idea of how digitalization, and above all new technologies like machine learning, big-data analytics or IoT, will change companies' business models — and are already changing them on a wide scale. The workplace of the future.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content