This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When handling large amounts of complex data, or bigdata, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. The MPP system leverages a shared-nothing architecture to handle multiple operations in parallel.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time. Then, bigdata analytics technologies, such as Hadoop, NoSQL, Spark, or Grail, the Dynatrace data lakehouse technology, interpret this information.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
This can include the use of cloud computing, artificial intelligence, bigdata analytics, the Internet of Things (IoT), and other digital tools. One of the significant challenges that come with digital transformation is ensuring that software systems remain reliable and secure. This is where software testing comes in.
Werner Vogels weblog on building scalable and robust distributed systems. Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for bigdata analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics.
The data platform is built on top of several distributed systems, and due to the inherent nature of these systems, it is inevitable that these workloads run into failures periodically. We have been working on an auto-diagnosis and remediation system called Pensive in the data platform to address these concerns.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This technique facilitates validation on multiple fronts.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
Bigdata is at the center of all business decisions these days. It refers to large volumes of data generated through different sources, and this data then provides the foundation for business decisions. There are different ways through which we can process data. The size of data in batch processing is known.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
Bigdata is like the pollution of the information age. The BigData Struggle and Performance Reporting. Alternatively, a number of organizations have created their own internal home-grown systems for managing and distilling web performance and monitoring data. Conclusion.
Finally, imagine yourself in the role of a data platform reliability engineer tasked with providing advanced lead time to data pipeline (ETL) owners by proactively identifying issues upstream to their ETL jobs. Let’s review a few of these principles: Ensure data integrity ?—?Accurately Enable seamless integration?—?
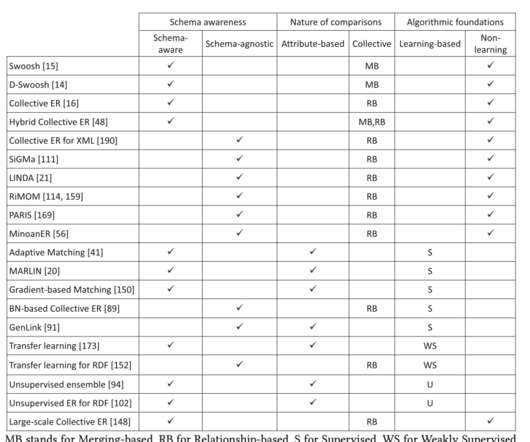
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. Open source ER systems. ACM Computing Surveys, Dec. 2020, Article No. All of the discussed approaches require schemas.
During earlier years of my career, I primarily worked as a backend software engineer, designing and building the backend systems that enable bigdata analytics. I developed many batch and real-time data pipelines using open source technologies for AOL Advertising and eBay. What is your favorite project?
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
While automating IT practices can save administrators a lot of time, without AIOps, the system is only as intelligent as the humans who program it. This kind of automation can support key IT operations, such as infrastructure, digital processes, business processes, and big-data automation. Bigdata automation tools.
Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. The configuration of these devices is controlled by several other systems including source of truth, application of configurations to devices, and back up.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our bigdata platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
AIOps combines bigdata and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. Like the development and design phases, these applications generate massive data volumes that offer relevant and actionable insights.
I love data. I have spent virtually my entire career looking at data. Synthetic data, network data, systemdata, and the list goes on. As much as I love data, data is cold, it lacks emotion. I still love data, but I am starting to love emotion-filled data. Dynatrace news.
Honestly, these two terms have recently been doing rounds in the bigdata world. Over the years, EDI has become a standard document exchange system, whereas API is on its way to becoming a popular alternative to EDI.
Early implementations of NoOps were just ‘lift and shift’ efforts that replicated existing systems to the cloud. AIOps , a term coined by Gartner in 2016, combines bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection and causality determination. Evolution of NoOps.
In fact, Gartner estimates that 80% of enterprises will shut down their on-premises data centers by 2025. This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. So, what is ITOps? Why is IT operations important?
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The processed data is typically stored as data warehouse tables in AWS S3.
Containers enable developers to package microservices or applications with the libraries, configuration files, and dependencies needed to run on any infrastructure, regardless of the target system environment. This means organizations are increasingly using Kubernetes not just for running applications, but also as an operating system.
Supported technologies include cloud services, bigdata, databases, OS, containers, and application runtimes like the JVM. Akamas is comparing data across different experiments to identify the optimal configuration of your system. Automation is the key to optimizing our systems. via Cloud APIs or plain simple SSH).
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., Microsoft’s bigdata clusters have 10s of thousands of machines, and are used by thousands of users to run some pretty complex queries. ICDE’16 (PowerDrill is a Google internal system). VLDB’19.
She dispelled the myth that more bigdata equals better decisions, higher profits, or more customers. Investing in data is easy but using it is really hard”. The fact is, data on its own isn’t meaningful. Tricia quoted the statistic that companies typically use 3% of their data to inform decisions.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
Additionally, efforts such as lowered data retention times, two-tiered storage systems, shaky index management, sampled data, and data pipelines reduce the overall amount of stored data. Grail addresses today’s challenges of bigdata and cloud everywhere: Grail is highly scalable, cost-effective, and super-fast.
Over the past decade, the industry moved from paper-based to electronic health records (EHRs)—digitizing the backbone of patient data. As patient care continues to evolve, IT teams have accelerated this shift from legacy, on-premises systems to cloud technology to more build, test, and deploy software, and fuel healthcare innovation.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. The audits check for equality (i.e.
.” Accessing business insights and data with precision and long-term context After working with Dynatrace, BCLC now has a twenty-four-seven data center team with an easy-to-share, intuitive datacenter hyper wall dashboard showing the overall health of the entire system — infrastructure, applications, networks, and user experience.
However, as the system has increased in scale and complexity, Pensive has been facing challenges due to its limited support for operational automation, especially for handling memory configuration errors and unclassified errors. To handle errors efficiently, Netflix developed a rule-based classifier for error classification called “Pensive.”
Artificial intelligence for IT operations, or AIOps, combines bigdata and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. The four stages of data processing. This process continues until the system identifies a root cause. Two types of root cause.
Log4Shell required many organizations to take devices and applications offline to prevent malicious attackers from gaining access to IT systems and sensitive data. As a result, organizations need to be vigilant in identifying and addressing vulnerabilities to protect their systems and data.
I took a big-data-analysis approach, which started with another problem visualization. This is what I wanted to optimize and avoid and many traditional (or homegrown) systems aren’t doing this. This time defines when Dynatrace will invoke the integration to 3 rd party system for a problem after it has been detected.
Gartner defines AIOps as the combination of “bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” This contrasts stochastic AIOps approaches that use probability models to infer the state of systems. What is AIOps?
The variables that can impact the performance of an application vary; from coding errors or ‘bugs’ in the software, database slowdowns, hosting and network performance, to operating system and device type support.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content