This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. The pipelines can be stateful and the engine’s middleware should provide a persistent storage to enable state checkpointing. Interoperability with Hadoop.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
A data lakehouse features the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. How does a data lakehouse work?
Teams have introduced workarounds to reduce storage costs. Additionally, efforts such as lowered data retention times, two-tiered storage systems, shaky index management, sampled data, and data pipelines reduce the overall amount of stored data. Dynatrace discovers logs automatically at scale.
Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix. Pallavi, what’s your journey to data engineering at Netflix?
As cloud and bigdata complexity scales beyond the ability of traditional monitoring tools to handle, next-generation cloud monitoring and observability are becoming necessities for IT teams. With agent monitoring, third-party software collects data and reports from the component that’s attached to the agent.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Open-source software drives a vibrant Kubernetes ecosystem. Java, Go, and Node.js
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Storage provisioning.
At Dynatrace Perform 2023 , Maciej Pawlowski, senior director of product management for infrastructure monitoring at Dynatrace, and a senior software engineer at a U.K.-based based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
By embracing public cloud and hybrid cloud computing environments, IT teams can further accelerate development and automate software deployment and management. A container is a small, self-contained, fully functional software package that can run an application or service, isolated from other applications running on the same host.
In this talk, Jessica Larson shares her takeaways from building a new data platform post-GDPR. Data Productivity at Scale Recording Speaker : Iaroslav Zeigerman (Co-Founder and Chief Architect at Tobiko Data) Summary : The development and evolution of data pipelines are hindered by outdated tooling compared to software development.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. ITOps refers to the process of acquiring, designing, deploying, configuring, and maintaining equipment and services that support an organization’s desired business outcomes.
As teams try to gain insight into this data deluge, they have to balance the need for speed, data fidelity, and scale with capacity constraints and cost. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
Utilizing cloned real traffic, we can exercise the diversity of inputs from a wide range of devices and device application software versions in production. Given the scale of the data being generated using replay traffic, we record the responses from the two sides to a cost-effective cold storage facility using technology like Apache Iceberg.
Expanding the Cloud - Amazon S3 Reduced Redundancy Storage. Today a new storage option for Amazon S3 has been launched: Amazon S3 Reduced Redundancy Storage (RRS). This new storage option enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy. Comments ().
With the launch of the AWS Europe (London) Region, AWS can enable many more UK enterprise, public sector and startup customers to reduce IT costs, address data locality needs, and embark on rapid transformations in critical new areas, such as bigdata analysis and Internet of Things. Fraud.net is a good example of this.
This article will help you understand the core differences in data structure, scalability, and use cases. Whether you need a relational database for complex transactions or a NoSQL database for flexible datastorage, weve got you covered. This allows for precise data manipulation and retrieval.
To our shareowners: Random forests, naïve Bayesian estimators, RESTful services, gossip protocols, eventual consistency, data sharding, anti-entropy, Byzantine quorum, erasure coding, vector clocks. Look inside a current textbook on software architecture, and youll find few patterns that we dont apply at Amazon. At werner.ly
The implementation of emerging technologies has helped improve the process of software development, testing, design and deployment. Any organization recruits experienced testing agencies to comply with their specifications for software testing. Here is the list of software testing trends you need to look out for in 2021.
Helios also serves as a reference architecture for how Microsoft envisions its next generation of distributed big-data processing systems being built. What follows is a discussion of where bigdata systems might be heading, heavily inspired by the remarks in this paper, but with several of my own thoughts mixed in.
No one can expect human users to explicitly control concurrency, integrity, consistency, or data type validity. On the other hand, it turned out that software applications are not so often interested in in-database aggregation and able to control, at least in many cases, integrity and validity themselves.
However, the data infrastructure to collect, store and process data is geared toward developers (e.g., In AWS’ quest to enable the best datastorage options for engineers, we have built several innovative database solutions like Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift. Bigdata challenges.
Incoming data is saved into datastorage (historian database or log store) for query by operational managers who must attempt to find the highest priority issues that require their attention. The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
These companies can now benefit from the fact that the new Sao Paulo Region is similar to all other AWS Regions, which enables software developed for other Regions to be quickly deployed in South America as well. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. At werner.ly
Earlier this year I met with an ISV partner who transformed his on-premise ERP software into a software-as-a-service offering. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. Driving down the cost of Big-Data analytics. At werner.ly Syndication. or rss feed.
Flexibility is one of the key principles of Amazon Web Services - developers can select any programming language and software package, any operating system, any middleware and any database to build systems and applications that meet their requirements. Driving Storage Costs Down for AWS Customers. Comments (). At werner.ly Syndication.
release , we added support for physical backups and restores to significantly reduce Recovery Time Objective ( RTO ), especially for bigdata sets. However, the problem of losing data between backups – in other words, Recovery Point Objective (RPO) – for physical backups was not solved. spec: backup: enabled: true.
This makes RabbitMQ an attractive option for developers and enterprises seeking to optimize their software architecture. Can RabbitMQ handle the high-throughput needs of bigdata applications? For high-throughput bigdata applications, RabbitMQ may fall short of expectations.
If CPU usage is not a bottleneck in your setup, you can leverage compression as it can improve performance which means that less data needs to be read from disk and written to memory, and indexes are compressed too. It can help us to save costs on storage and backup times. MyRocks is shipped in Percona Server for MySQL.
Resolvers operate in a completely separate hierarchy which is bottoms up, starting with software caches in a browser or the OS, to a local resolver or a regional resolver operated by an ISP or a corporate IT service. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. At werner.ly
AWS Database Services is responsible for setting the database strategy and delivering distributed structured storage services to our AWS customers. For more information: Head of Software Development  . Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. Contact Info. Other places.
During my academic career, I spent many years working on HPC technologies such as user-level networking interfaces, large scale high-speed interconnects, HPC software stacks, etc. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. Driving down the cost of Big-Data analytics.
Shell leverages AWS for bigdata analytics to help achieve these goals. Due to the exponential growth of the biology and informatics fields, Unilever needs to maintain this new program within a highly-scalable environment that supports parallel computation and heavy datastorage demands.
Modern CPUs strongly favor lower latency of operations with clock cycles in the nanoseconds and we have built general purpose software architectures that can exploit these low latencies very well. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. At werner.ly Syndication. or rss feed.
A wide variety of operating systems and software configurations is available for use. This allows for a very fine-grain control of software and data configuration. While the instance is stopped it does not accrue any usage hours and customers are only charged for the storage associated with the Amazon EBS volume.
With some minor configuration changes, they can simply move the software running in the AWS EU Region to the AWS Singapore Region and rapidly begin serving Asia Pacific customers. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. Driving down the cost of Big-Data analytics.
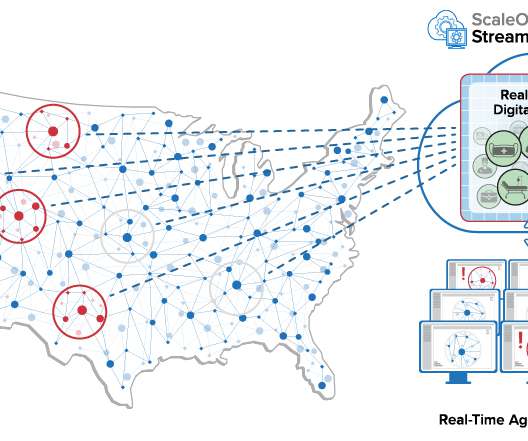
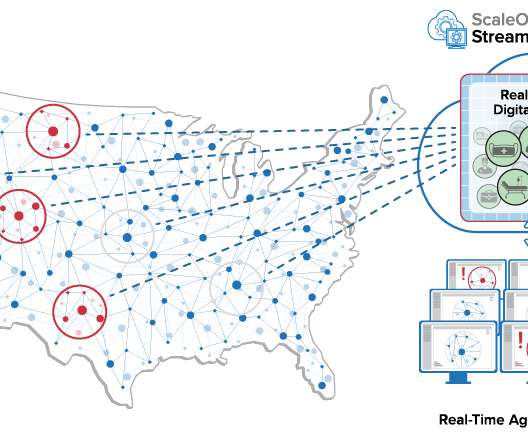
What’s missing is a flexible, fast, and easy-to-use software system that can be quickly adapted to track these assets in real time and provide immediate answers for logistics managers. These questions can be answered using the latest data as it streams in from the field. What are real-time digital twins and why are they useful here?
What’s missing is a flexible, fast, and easy-to-use software system that can be quickly adapted to track these assets in real time and provide immediate answers for logistics managers. These questions can be answered using the latest data as it streams in from the field. What are real-time digital twins and why are they useful here?
IBM BigData and Analytics Hub website cited a case study, where a US insurance company was estimating 15% of their testing efforts to be just test data collection for the backend system and the frontend system. The test data management for the company had become a big problem and had to be solved.
According to Wikipedia, Data-Driven Testing(DDT) is a software testing methodology that is used in the testing of computer software to describe testing done using a table of conditions directly as test inputs and verifiable outputs as well as the process where test environment settings and control are not hard-coded. CSV files.
These unassuming pieces of software have the potential to reshape the way you engage with your customers, market your products or services, and, ultimately, grow your business. A phone call tracking app is a software tool that enables businesses to monitor and analyze incoming calls. What Is a Phone Call Tracking App?
However when one of these extreme failure conditions occurs it may be that the stronger consistency options are briefly not available while the software reorganizes itself to ensure that it can provide strong consistency. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. At werner.ly
The rise of BigData - the ability to store and analyze large volumes of structured and unstructured, internal and external data - promises to let companies react more nimbly than ever before. A megabyte of cloud-based disk storage is no different from a kilowatt of electricity. Nor is cloud computing.
LISA originally stood for "Large Installation System Administration," where "large" meant systems with more than a gigabyte of storage, or with more than 100 users. Some topics are still present at LISA, such as network management and uptime (reliability), but many others have been updated over the years.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content