This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages.
Efficient data processing is crucial for businesses and organizations that rely on bigdata analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
This article describes 3 different tricks that I used in dealing with bigdata sets (order of 10 million records) and that proved to enhance performance dramatically. This trick enhanced the performance dramatically. Trick 1: CLOB Instead of Result Set.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. The engine should be able to ingest both streaming data and data from Hadoop i.e. serve as a custom query engine atop of HDFS. High performance and mobility.
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support bigdata processing. In addition, pySpark applications can be tuned to optimize performance and achieve better execution time, scalability, and resource utilization.
In my recent Performance Clinic with Stefano Doni , CTO & Co-Founder of Akamas , I made the statement, “Application development and release cycles today are measured in days, instead of months. Increase in environment complexity and increased frequency in delivery requires a novel approach to performance optimization.
Bigdata is like the pollution of the information age. The BigData Struggle and Performance Reporting. Alternatively, a number of organizations have created their own internal home-grown systems for managing and distilling web performance and monitoring data. No fuss, no muss.
Spark-Radiant is Apache Spark Performance and Cost Optimizer. Spark-Radiant will help optimize performance and cost considering catalyst optimizer rules, enhance auto-scaling in Spark, collect important metrics related to a Spark job, Bloom filter index in Spark, etc. Spark-Radiant is now available and ready to use.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights. Choose a repository to collect data and define where to store data.
Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud. Driving down the cost of Big-Data analytics. Comments ().
In today's world, data is generated in high volumes and to make something out of it, extracted data is needed to be transformed, stored, maintained, governed and analyzed. These processes are only possible with a distributed architecture and parallel processing mechanisms that BigData tools are based on.
This is a guest post by Limor Maayan-Wainstein , a senior technical writer with 10 years of experience writing about cybersecurity, bigdata, cloud computing, web development, and more. High performance computing (HPC) enables you to solve complex problems which cannot be solved by regular computing.
Application Performance Monitoring (APM) in its simplest terms is what practitioners use to ensure consistent availability, performance, and response times to applications. APM can also be referred to as: Application performance management. Performance monitoring. Dynatrace news. Application monitoring.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Performance.
In short, it is the ability to handle more data, more users, and more demand without sacrificing performance, reliability, or security. The reason is straightforward, today, applications generate enormous amounts of data. It is not uncommon to question why scalability has grabbed the attention of the masses these days.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI.
Apache Spark is a leading platform in the field of bigdata processing, known for its speed, versatility, and ease of use. This article delves into various techniques that can be employed to optimize your Apache Spark jobs for maximum performance.
This blog will explore these two systems and how they perform auto-diagnosis and remediation across our BigData Platform and Real-time infrastructure. The streaming platform recently added Data Mesh , and we need to expand Streaming Pensive to cover that.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards.
Our customers have frequently requested support for this first new batch of services, which cover databases, bigdata, networks, and computing. Effortlessly optimize Azure database performance. Database-service views provide all the metrics you need to set up high-performance database services. Azure Front Door.
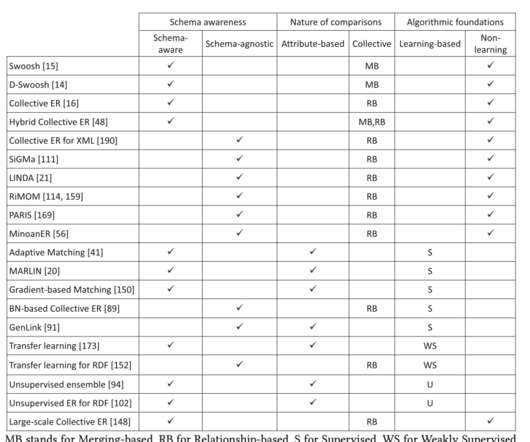
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. ACM Computing Surveys, Dec. 2020, Article No.
Netflix’s unique work culture and petabyte-scale data problems are what drew me to Netflix. During earlier years of my career, I primarily worked as a backend software engineer, designing and building the backend systems that enable bigdata analytics. Moreover, its petabyte scale also brings unique engineering challenges.
It has been a norm to perceive that distributed databases use the method of adding cheap PC(s) to achieve scalability (storage and computing) and attempt to store data once and for all on demand. However, doing the same cannot achieve equivalent scalability without massively sacrificing query performance on graph systems.
Application Performance Monitoring (APM) in its simplest terms is what practitioners use to ensure consistent availability, performance, and response times to applications. APM can be referred to as: Application performance monitoring. Application performance management. Performance monitoring. Dynatrace news.
Data lakehouses take advantage of low-cost object stores like AWS S3 or Microsoft Azure Blob Storage to store and manage data cost-effectively. Data lakehouses offer a way to interrogate the data and send processing instructions in the form of queries. Data lakehouses deliver the query response with minimal latency.
Honestly, these two terms have recently been doing rounds in the bigdata world. These technologies specialize in transmitting large amounts of data across different trading partners and companies. These technologies specialize in transmitting large amounts of data across different trading partners and companies.
Nowadays, BigData tests mainly include data testing, paving the way for the Internet of Things to become the center point. Factors such as reliability and quality are being given extra attention that results in the decrease of software app errors, enhancing the security and the app performance.
The demand for more IT resource-intensive applications has significantly increased today, whether it is to process quicker transactions, gain real-time insight, crunch bigdata sets, or to meet customer expectations. That’s because NVMe provides 6x higher bandwidth and IOPS advantage compared to SAS/SATA SSD.
This meant there were still operations, only they were performed by someone else! AIOps , a term coined by Gartner in 2016, combines bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection and causality determination.
This kind of automation can support key IT operations, such as infrastructure, digital processes, business processes, and big-data automation. Bigdata automation tools. These tools provide the means to collect, transfer, and process large volumes of data that are increasingly common in analytics applications.
In February 2021, Dynatrace announced full support for Google’s Core Web Vitals metrics , which will help site owners as they start optimizing Core Web Vitals performance for SEO. Not everyone has expertise in performance optimization and how it can impact SEO. To do this effectively, you need a bigdata processing approach.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our bigdata platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
AIOps combines bigdata and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. Aggregation.
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., Microsoft’s bigdata clusters have 10s of thousands of machines, and are used by thousands of users to run some pretty complex queries. VLDB’19. in the paper). The accuracy was considered adequate by the developer.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. These include Quality-of-Experience(QoE) measurements at the customer device level, Service-Level-Agreements (SLAs), and business-level Key-Performance-Indicators(KPIs).
With bigdata on the rise and data algorithms advancing, the ways in which technology has been applied to real-world challenges have grown more automated and autonomous. Financial analysis with real-time analytics is used for predicting investments and drives the FinTech industry's needs for high-performance computing.
Additionally, Grail delivers unrivaled performance without losing the precision of unsampled, gapless data. Grail addresses today’s challenges of bigdata and cloud everywhere: Grail is highly scalable, cost-effective, and super-fast. Turn log data into value and activate Grail. Use conditional statements.
Today data is an important factor for business success. In every business, it has been observed that data is playing a game-changing moment to improve business performance. Data is important and necessary in this increasingly competitive world.
The primary goal of ITOps is to provide a high-performing, consistent IT environment. Organizations measure these factors in general terms by assessing the usability, functionality, reliability, and performance of products and services. Performance. What does IT operations do? ITOps vs. AIOps.
A hybrid cloud, however, combines public infrastructure and services with on-premises resources or a private data center to create a flexible, interconnected IT environment. Hybrid environments provide more options for storing and analyzing ever-growing volumes of bigdata and for deploying digital services.
In the era of bigdata, efficient data management and query performance are critical for organizations that want to get the best operational performance from their data investments.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using bigdata compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as data warehouse tables in AWS S3.
The service that orchestrates failover uses numpy and scipy to perform numerical analysis, boto3 to make changes to our AWS infrastructure, rq to run asynchronous workloads and we wrap it all up in a thin layer of Flask APIs. These libraries are the primary way users interface programmatically with work in the BigData platform.
As observability and security data converge in modern multicloud environments, there’s more data than ever to orchestrate and analyze. The goal is to turn more data into insights so the whole organization can make data-driven decisions and automate processes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content