This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages.
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support bigdata processing. In addition, pySpark applications can be tuned to optimize performance and achieve better execution time, scalability, and resource utilization.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. In the previous section, we noted that many distributed query processing algorithms resemble message passing networks. It is conceptually similar to the in-stream processing pipelines.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
As cloud and bigdata complexity scales beyond the ability of traditional monitoring tools to handle, next-generation cloud monitoring and observability are becoming necessities for IT teams. With agent monitoring, third-party software collects data and reports from the component that’s attached to the agent.
But managing the deployment, modification, networking, and scaling of multiple containers can quickly outstrip the capabilities of development and operations teams. This orchestration includes provisioning, scheduling, networking, ensuring availability, and monitoring container lifecycles. How does container orchestration work?
Modern IT environments — whether multicloud, on-premises, or hybrid-cloud architectures — generate exponentially increasing data volumes. The number and variety of applications, network devices, serverless functions, and ephemeral containers grows continuously. And this expansion shows no sign of slowing down.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
With the launch of the AWS Europe (London) Region, AWS can enable many more UK enterprise, public sector and startup customers to reduce IT costs, address data locality needs, and embark on rapid transformations in critical new areas, such as bigdata analysis and Internet of Things. Fraud.net is a good example of this.
Distributed Systems In distributed systems’ sprawling networks, RabbitMQ is the glue that holds disparate components together. This system allows for scalability and efficiency, demonstrating RabbitMQ’s versatility in real-world applications where speed and reliability are crucial.
Boris has unique expertise in that area – especially in BigData applications. To facilitate discussions, in addition to Q&A, we have panels, “Meeting of the Minds” sessions, and networking events. How to select appropriate IT Infrastructure to support Digital Transformation by Boris Zibitsker, BEZNext.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. They keep the features that developers like but can handle much more data, similar to NoSQL systems.
After the launch of the AWS APAC (Hong Kong) Region, there will be 19 Availability Zones in Asia Pacific for customers to build flexible, scalable, secure, and highly available applications. As well as AWS Regions, we also have 21 AWS Edge Network Locations in Asia Pacific.
Given this, enterprises, public sector bodies, startups, and small businesses are looking to adopt agile, scalable, and secure public cloud solutions. Access to secure, scalable, low-cost AWS infrastructure in Canada allows customers to innovate and provide tools to meet privacy, sovereignty, and compliance requirements. Scalability.
This approach allows companies to combine the security and control of private clouds with public clouds’ scalability and innovation potential. Mastering Hybrid Cloud Strategy Are you looking to leverage the best private and public cloud worlds to propel your business forward? A hybrid cloud strategy could be your answer.
Werner Vogels weblog on building scalable and robust distributed systems. Japanese companies and consumers have become used to low latency and high-speed networking available between their businesses, residences, and mobile devices. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Comments ().
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios. Data transfer technology.
After the launch of the AWS EU (Stockholm) Region, there will be 13 Availability Zones in Europe for customers to build flexible, scalable, secure, and highly available applications. It will also give customers another region where they can store their data with the knowledge that it will not leave the EU unless they move it.
Werner Vogels weblog on building scalable and robust distributed systems. Often these namespaces are hierarchical in nature such that it becomes easier to manage them and to decentralize control, which makes the system more scalable. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. No lock-in.
Werner Vogels weblog on building scalable and robust distributed systems. The storage systems weve pioneered demonstrate extreme scalability while maintaining tight control over performance, availability, and cost. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. All Things Distributed.
Werner Vogels weblog on building scalable and robust distributed systems. During my academic career, I spent many years working on HPC technologies such as user-level networking interfaces, large scale high-speed interconnects, HPC software stacks, etc. Driving down the cost of Big-Data analytics. All Things Distributed.
Werner Vogels weblog on building scalable and robust distributed systems. If you have a largely static site you can rely on the enormous power of S3 to make serving your content highly scalable and storing it extremely durable. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. Government and BigData. One particular early use case for AWS GovCloud (US) will be massive data processing and analytics. The scalability, flexibility and the elasticity of AWS makes it an ideal environment for the agencies to run their analytics.
Using local SSDs inside of the GPU node delivers fast access to data during training, but introduces challenges that impact the overall solution in terms of scalability, data access, and data protection.
Shell leverages AWS for bigdata analytics to help achieve these goals. Due to the exponential growth of the biology and informatics fields, Unilever needs to maintain this new program within a highly-scalable environment that supports parallel computation and heavy data storage demands.
If a cyber network agent has observed an unusual pattern of failed login attempts, it needs to alert downstream network nodes (servers and routers) to block the kill chain in a potential attack. The list goes on. The Limitations of Today’s Streaming Analytics. A New Approach: Real-Time Device Tracking.
AutoOptimize relies on some of the Iceberg specific features such as snapshot and atomic operations to perform the optimizations in an accurate and scalable manner. AutoOptimize reduces end to end lag in data processing by optimizing as we go. Other Components Iceberg We use Apache Iceberg as the table format.
Werner Vogels weblog on building scalable and robust distributed systems. AWS Import/Export transfers data off of storage devices using Amazons high-speed internal network and bypassing the Internet. With this new functionality AWS Import/Export now supports importing data directly into Amazon EBS snapshots. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. With Amazon Glacier any organization now has access to the same data archiving capabilities as the worldâ??s for those datasets that are too large to transmit via the network AWS offers the ability to up- and download data from disks that can be shipped.
Werner Vogels weblog on building scalable and robust distributed systems. Elastic Beanstalk makes it easy for developers to deploy and manage scalable and fault-tolerant applications on the AWS cloud. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. All Things Distributed. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. There are sessions in many different categories: Architecture, BigData, HPC, Computer & Networking, Storage, Databases, Security, Tools & Languages, Media Sharing & Content Delivery, Managing AWS Resources, Enterprise IT, Mobile, Start-up, and more.
Werner Vogels weblog on building scalable and robust distributed systems. Big Just Got Bigger - 5 Terabyte Object Support in Amazon S3. Amazon S3 has always been a scalable, durable and available data repository for almost any customer workload. Driving down the cost of Big-Data analytics. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. Starting today Amazon EMR can take advantage of the Cluster Compute and Cluster GPU instances, giving customers ever more powerful components to base the large scale data processing and analysis on. Driving down the cost of Big-Data analytics.
In other words, it can be more efficient to sort data once during insertion than sort them for each MapReduce query. Applications: ETL, Data Analysis. Problem Statement: There is a network of entities and relationships between them. Not-So-Basic MapReduce Patterns. Iterative Message Passing (Graph Processing).
We’ve seen similar high marshalling overheads in bigdata systems too.) Fetching too much data in a single query (i.e., If you decompose data across multiple keys to avoid this, you then typically run into cross-key atomicity issues. Over and above RTT times, the size of the data to be transferred also matters.
Alongside more traditional sessions such as Real-World Deployed Systems and BigData Programming Frameworks, there were many papers focusing on emerging hardware architectures, including embedded multi-accelerator SoCs, in-network and in-storage computing, FPGAs, GPUs, and low-power devices. Heterogeneous ISA. Final words.
Werner Vogels weblog on building scalable and robust distributed systems. This new storage option enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. All Things Distributed.
Werner Vogels weblog on building scalable and robust distributed systems. There are many factors that come into play when you need to meet stringent availability and performance requirements under ultra-scalable conditions. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Choosing Consistency.
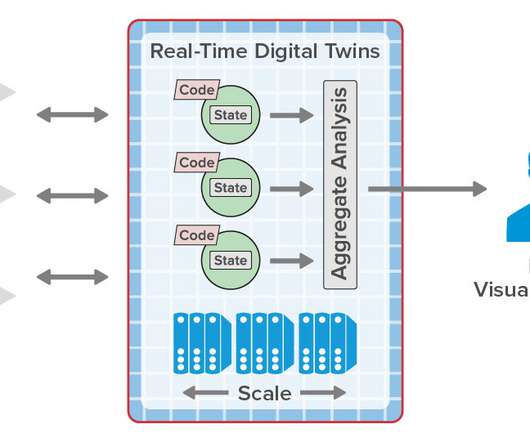
Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks. At the same time, telemetry snapshots are stored in a data lake, such as HDFS , for offline batch analysis and visualization using bigdata tools like Spark.
I don’t think so in this case, but this paper will take you down into the nitty-gritty of getting the best out of modern processors and networks, with up to two orders of magnitude single node throughput gains to be had. What if the network was no longer the bottleneck? Maybe we should be switching to active-memory replication ?
Apart from networking, attending conferences like LISA in person is an effective way to upgrade your skills: you can block out work interruptions and absorb new knowledge that's been neatly summarized into sessions. We first met each other at LISA, in addition to making many other important industry connections over the years.
Apart from networking, attending conferences like LISA in person is an effective way to upgrade your skills: you can block out work interruptions and absorb new knowledge that's been neatly summarized into sessions. We first met each other at LISA, in addition to making many other important industry connections over the years.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content