This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. Other flows are more sophisticated: one Storm topology can pass the data to another topology via Kafka or Cassandra. Towards Unified BigData Processing. Apache Spark [10].
Amazon's worldwide financial operations team has the incredible task of tracking all of that data (think petabytes). At Amazon's scale, a miscalculated metric, like cost per unit, or delayed data can have a huge impact (think millions of dollars). The team is constantly looking for ways to get more accurate data, faster.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
The data platform is built on top of several distributed systems, and due to the inherent nature of these systems, it is inevitable that these workloads run into failures periodically. This blog will explore these two systems and how they perform auto-diagnosis and remediation across our BigData Platform and Real-time infrastructure.
Then, bigdata analytics technologies, such as Hadoop, NoSQL, Spark, or Grail, the Dynatrace data lakehouse technology, interpret this information. Here are the six steps of a typical ITOA process : Define the data infrastructure strategy. Choose a repository to collect data and define where to store data.
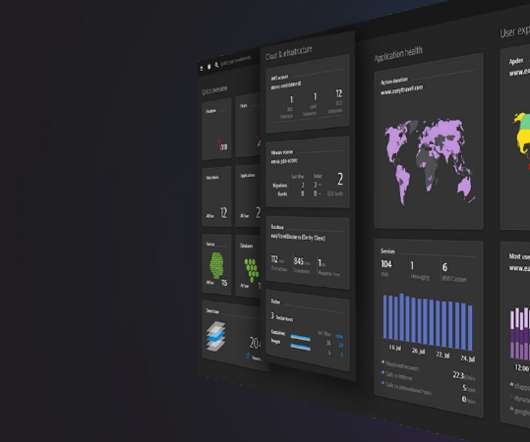
As cloud and bigdata complexity scales beyond the ability of traditional monitoring tools to handle, next-generation cloud monitoring and observability are becoming necessities for IT teams. These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards.
JavaScript errors are emotionless with simple data points of metrics. And it’s easy to ignore or argue metrics because they can’t argue back. I still love data, but I am starting to love emotion-filled data. Big” data helps us make the right decisions and focus on the right things.
Bigdata is like the pollution of the information age. The BigData Struggle and Performance Reporting. Alternatively, a number of organizations have created their own internal home-grown systems for managing and distilling web performance and monitoring data. No fuss, no muss.
Our customers have frequently requested support for this first new batch of services, which cover databases, bigdata, networks, and computing. Database-service views provide all the metrics you need to set up high-performance database services. See the health of your bigdata resources at a glance.
In February 2021, Dynatrace announced full support for Google’s Core Web Vitals metrics , which will help site owners as they start optimizing Core Web Vitals performance for SEO. To do this effectively, you need a bigdata processing approach. Segregation of data by mobile and desktop. Dynatrace news. 28-day lookbacks.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. The batch job creates a high-level summary that captures some key comparison metrics.
Even in cases where all data is available, new challenges can arise. When one tool monitors logs, but traces, metrics, security, audit, observability, and business data sources are siloed elsewhere or monitored using other tools, teams can struggle to align or deliver a single version of the truth.
Grafana is an open-source tool to visualize the metrics and logs from different data sources. It can query those metrics, send alerts, and can be actively used for monitoring and observability, making it a popular tool for gaining insights. What Is Grafana?
One example is the Spectator Python client library, a library for instrumenting code to record dimensional time series metrics. Orchestration The BigData Orchestration team is responsible for providing all of the services and tooling to schedule and execute ETL and Adhoc pipelines.
The integration with Dynatrace has two sides: first, it pulls metrics from Dynatrace while Akamas is executing an experiment. This data then flows into their AI and Machine Learning Engine to decide which configurations to change next: Akamas pulls in full stack Dynatrace data to make configuration change decisions for upcoming experiments.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
The Flow Exporter also publishes various operational metrics to Atlas. These metrics are visualized using Lumen , a self-service dashboarding infrastructure. The runtime behavior of the Flow Exporter can be dynamically managed by configuration changes via Fast Properties. So how do we ingest and enrich these flows at scale ?
Spark-Radiant will help optimize performance and cost considering catalyst optimizer rules, enhance auto-scaling in Spark, collect important metrics related to a Spark job, Bloom filter index in Spark, etc. Spark-Radiant is Apache Spark Performance and Cost Optimizer. Spark-Radiant is now available and ready to use.
AIOps combines bigdata and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. But AIOps also improves metrics that matter to the bottom line. What is AIOps, and how does it work? For example: Greater IT staff efficiency.
In general, metrics collectors and providers are most common, followed by log and tracing projects. Bigdata : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch. Across all categories in the Kubernetes survey, open source projects rank among the most frequently used solutions.
Using Grail to heal observability pains Grail logs not only store bigdata, but also map out dependencies to enable fast analytics and data reasoning. Business leaders can decide which logs they want to use and tune storage to their data needs. Seamless integration. Fast, precise answers. ” Watch session now!
Artificial intelligence for IT operations, or AIOps, combines bigdata and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. The deviating metric is response time. Let’s say, for example, an application is experiencing a slowdown in receiving its search requests.
Gartner defines AIOps as the combination of “bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” This means data sources typically come from disparate infrastructure monitoring tools and second-generation APM solutions.
ITOps teams use more technical IT incident metrics, such as mean time to repair, mean time to acknowledge, mean time between failures, mean time to detect, and mean time to failure, to ensure long-term network stability. In general, you can measure the business value of ITOps by evaluating the following: Usability. ITOps vs. AIOps.
.” Accelerating maturity with Business Insights Partnering with Dynatrace Business Insights has resulted in on-demand, automated real user monitoring (RUM) and end-to-end observability of their high-value, big-money players, including key metrics, session replay , and monthly reporting.
Dynatrace provides out-of-the box complete observability for dynamic cloud environment, at scale and in-context, including metrics, logs, traces, entity relationships, UX and behavior in a single platform. With our AI engine, Davis, at the core Dynatrace provides precise answers in real-time. Advanced Cloud Observability.
A daily process ranks the records by timestamp to generate a data frame of compacted records. Old data files are overwritten with a set of new data files that contain only the compacted data. Data Quality Data Mesh provides metrics and dashboards at both the processor and pipeline level for operational observability.
A hybrid cloud, however, combines public infrastructure and services with on-premises resources or a private data center to create a flexible, interconnected IT environment. Hybrid environments provide more options for storing and analyzing ever-growing volumes of bigdata and for deploying digital services.
Metrics like the net promoter score (NPS) or customer satisfaction (CSAT) score encapsulate this kind of customer feedback into measurable analytics. Dynatrace enables organizations to understand user behavior with bigdata analytics based on gap-free data, eliminating the guesswork involved in understanding the user experience.
I bring my breadth of bigdata tools and technologies while Julie has been building statistical models for the past decade. Writing memos is a big part of Netflix culture, which I’ve found has been helpful for sharing ideas, soliciting feedback, and documenting project details.
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. what is the cardinality of the data set)? Heavy Hitters: Stream-Summary.
For example, a job would reprocess aggregates for the past 3 days because it assumes that there would be late arriving data, but data prior to 3 days isn’t worth the cost of reprocessing. Backfill: Backfilling datasets is a common operation in bigdata processing. append, overwrite, etc.).
Dynatrace provides out-of-the box complete observability for dynamic cloud environment, at scale and in-context, including metrics, logs, traces, entity relationships, UX and behavior in a single platform. With our AI engine, Davis, at the core Dynatrace provides precise answers in real-time. Advanced Cloud Observability.
This includes collecting metrics, logs, and traces from all applications and infrastructure components. One key to augmenting DevSecOps collaboration is to take a platform approach that converges observability and security with bigdata analytics that can scale without compromising data fidelity.
I started working at a local payment processing company after graduation, where I built survival models to calculate lifetime value and experimented with them on our brand new bigdata stack. I was doing data science without realizing it. Data scientists can take on any aspect of an experimentation project.
Amazon Cloudwatch can be used to get detailed metrics about the performance of the Cache Nodes. Driving down the cost of Big-Data analytics. Scaling the total memory in the Cache Cluster is under complete control of the customers as Caching Nodes can be added and deleted on demand. No Server Required - Jekyll & Amazon S3.
Although these problems are very different, we are trying to establish a common framework that helps to design optimization and data mining tasks required for solutions. Moreover, gross margin is not the only performance metric that is important for retailers. The gross margin metric, in the sense it is used in the equations (1.2)
Workloads from web content, bigdata analytics, and artificial intelligence stand out as particularly well-suited for hybrid cloud infrastructure owing to their fluctuating computational needs and scalability demands.
Take, for example, The Web Almanac , the golden collection of BigData combined with the collective intelligence from most of the authors listed below, brilliantly spearheaded by Google’s @rick_viscomi. How to pioneer new metrics and create a culture of performance. Time is Money. High Performance Websites.
The metrics collection showed the ~5 hour gap and the more troubleshooting I did the more it was clear that every pod on the same node encountered the same paused behavior. Bob Dorr.
This metric is a little difficult to comprehend, so here’s an example: if the average cost of broadband packages in a country is $22, and the average download speed offered by the packages is 10 Mbps, then the cost ‘per megabit per month’ would be $2.20. For reference, the metric is $1.19 in the UK and $1.26 in the USA.
Operating Delta applications is made simple for users as the framework provides resilience and failure tolerance out of the box and collects many granular metrics that can be used for alerts. Optimization can be made in a way that is transparent to users, and bugs can be fixed without requiring any changes to user code (UDFs).
Developers representing hundreds of companies work together at these meetups to become masters in performance metrics and the latest trends in measuring site speed.) And, of course, you should follow him on Twitter @ igrigorik for in-depth insights on web performance metrics, user experience, and industry news. Maximiliano Firtman.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content