This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages.
Introduction With bigdata streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
Central engineering teams provide paved paths (secure, vetted and supported options) and guard rails to help reduce variance in choices available for tools and technologies to support the development of scalable technical architectures.
Further, business leaders must often determine whether the data is relevant for the business and if they can afford it. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures. Dynatrace Grail unifies data from logs, metrics, traces, and events within a real-time model.
Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors.
Flow Collector consumes two data streams, the IP address change events from Sonar via Kafka and eBPF flow log data from the Flow Exporter sidecars. It performs real time attribution of flow data with application metadata from Sonar. We use Sonar to attribute an IP address to a specific application at a particular time.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
As Bigdata and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Another dimension of scalability to consider is the size of the workflow.
This talk will delve into the creative solutions Netflix deploys to manage this high-volume, real-time data requirement while balancing scalability and cost. Last but not least, thank you to the organizers of the Data Engineering Open Forum: Chris Colburn , Xinran Waibel , Jai Balani , Rashmi Shamprasad , and Patricia Ho.
Using Marathon, its data center operating system (DC/OS) plugin, Mesos becomes a full container orchestration environment that, like Kubernetes and Docker Swarm, discovers services, balances loads, and manages application containers. Mesos also supports other orchestration engines, including Kubernetes and Docker Swarm.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. In this approach, we record the requests and responses for the service that needs to be updated or replaced to an offline event stream asynchronously.
Boris has unique expertise in that area – especially in BigData applications. To facilitate discussions, in addition to Q&A, we have panels, “Meeting of the Minds” sessions, and networking events. How to select appropriate IT Infrastructure to support Digital Transformation by Boris Zibitsker, BEZNext.
With the launch of the AWS Europe (London) Region, AWS can enable many more UK enterprise, public sector and startup customers to reduce IT costs, address data locality needs, and embark on rapid transformations in critical new areas, such as bigdata analysis and Internet of Things. Fraud.net is a good example of this.
NoSQL databases are often compared by various non-functional criteria, such as scalability, performance, and consistency. Besides this, elimination of these features had an extremely important influence on the performance and scalability of the stores. Many techniques that are described below are perfectly applicable to this model.
This reliability also extends to fault tolerance, as RabbitMQ’s mechanisms ensure that even in the event of a node failure, the message delivery system persists without interruption, safeguarding the system’s overall health and functionality. Components can operate independently, confident that messages will be delivered reliably.
These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Both automatic (event-driven) as well as manual (ad-hoc) optimization. It decides what to do and when to do in response to an incoming event. Transparency to end-users.
Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational. Backfill: Backfilling datasets is a common operation in bigdata processing. append, overwrite, etc.).
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
This makes the query service lightweight, scalable, and execution agnostic. We leverage Apache Flink’s internal Planner classes to parse and transform SQL queries without creating a fully-fledged streaming table environment. We plan on gradually expanding the supported capabilities over time.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
After the launch of the AWS APAC (Hong Kong) Region, there will be 19 Availability Zones in Asia Pacific for customers to build flexible, scalable, secure, and highly available applications. In 2010, we opened our first AWS Region in Singapore and since then have opened additional regions: Japan, Australia, China, Korea, and India.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios. Data transfer technology.
Werner Vogels weblog on building scalable and robust distributed systems. It is shaping up to be a great event with many Amazonians, partners and customers presenting in well over 150 sessions. It is shaping up to be a great event with many Amazonians, partners and customers presenting in well over 150 sessions. Comments ().
And it can maintain contextual information about every data source (like the medical history of a device wearer or the maintenance history of a refrigeration system) and keep it immediately at hand to enhance the analysis.
Werner Vogels weblog on building scalable and robust distributed systems. Next to customer visits I will take part in a number of events organized by AWS and by our partners. Next to customer visits I will take part in a number of events organized by AWS and by our partners. Driving down the cost of Big-Data analytics.
Werner Vogels weblog on building scalable and robust distributed systems. The AWS Events team is organizing a number of events where I will present together with a number of AWS customers: AWS Cloud Computing Event in Berlin on October 7 with AWS customers moviepilot , Cellular , Schnee von morgen and Plinga. Comments ().
To a certain extent, such a high diversity of recommendation techniques is attributed to several implementation challenges like a sparsity of customer ratings, computational scalability, and lack of information on new items and customers. Sale events. Problem 5 : Sales Event Planning. Category management and assortment planning.
We’ve seen similar high marshalling overheads in bigdata systems too.) Fetching too much data in a single query (i.e., If you decompose data across multiple keys to avoid this, you then typically run into cross-key atomicity issues. getting the whole value when you supply the key). From RInK to LInK.
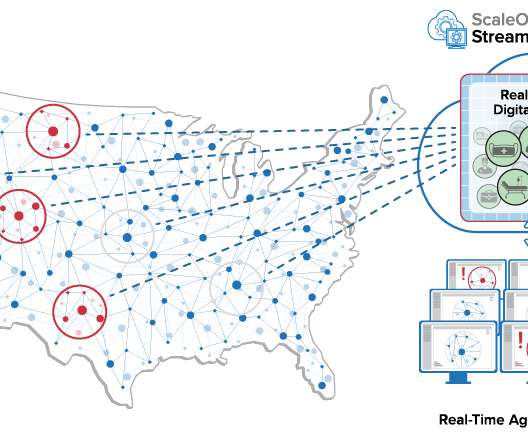
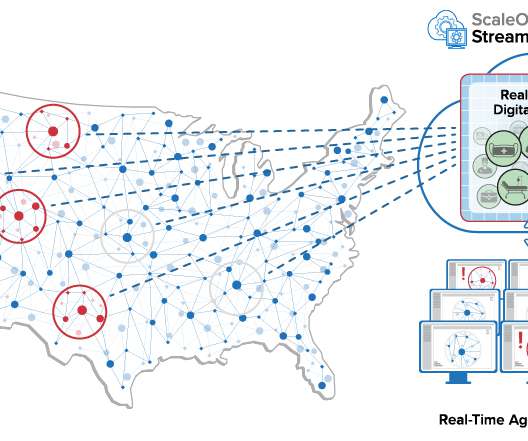
An innovative new software approach called “real-time digital twins” running on a cloud-hosted, highly scalable, in-memory computing platform can help address this challenge. The computing system also has the ability to perform aggregate analytics in seconds on the continuously evolving data held in the twins.
An innovative new software approach called “real-time digital twins” running on a cloud-hosted, highly scalable, in-memory computing platform can help address this challenge. The computing system also has the ability to perform aggregate analytics in seconds on the continuously evolving data held in the twins.
Solution II: The second solution requires only one MapReduce job, but it is not really scalable and its applicability is limited. It worth noting that Combiners can be used in this schema to exclude duplicates from category lists before data will be transmitted to Reducer.
It taught us how just an easy monthly subscription can give us access to thousands of movies, games, and live events such as the Tokyo Olympics via streaming. AppPerfect is one among the tools list that is a versatile tool – it is of great use for not only testers but developers and bigdata operations. Signup now.
Jake is a frequent speaker at many popular conferences and events, such as 100 Days of Google Dev , JAMstakConf , JSConf , SmashingConf , and dozens of others. Sergey is a principal engineer at Meetup and a well-known performance educator who regularly runs monthly hands-on Meet4SPEED events in New York City. Sergey Chernyshev.
USENIX’s LISA conference is the premier event for topics in production system engineering. LISA is a vendor-neutral event known for technical depth and rigor, and continues to attract an audience of seasoned professionals. Join us for 3 days in Nashville at LISA'18. Post by Brendan Gregg and Rikki Endsley. Hope to see you in Nashville!
In the era of bigdata and complex data processing, data pipelines have emerged as a popular solution for managing and manipulating data. They provide a systematic approach to extract, transform, and load (ETL) data from various sources, enabling organizations to derive valuable insights.
USENIX’s LISA conference is the premier event for topics in production system engineering. LISA is a vendor-neutral event known for technical depth and rigor, and continues to attract an audience of seasoned professionals. Join us for 3 days in Nashville at LISA'18. Post by Brendan Gregg and Rikki Endsley. Hope to see you in Nashville!
Hyper Dimension Shuffle describes how Microsoft improved the cost of data shuffling, one of the most costly operations, in their petabyte-scale internal bigdata analytics platform, SCOPE. DASH introduces Database Shadowing , a new crash recovery technique for SQLite. speedup over the best performing existing method.
Respond to disruptions: Supply chain disruptions, such as natural disasters or geopolitical events, can have a significant impact on production. BigData Analytics Handling and analyzing large volumes of data in real-time is critical for effective decision-making.
Discover how their solution saves customers hours of manual effort by automating the analysis of tens of thousands of documents to better manage investor events, report internally to executive teams, and find new investors to target. After re:Invent, I will update this post with the videos from the event, as I did last year.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content