This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
The shortcomings and drawbacks of batch-oriented dataprocessing were widely recognized by the BigData community quite a long time ago. It became clear that real-time query processing and in-stream processing is the immediate need in many practical applications. Modularity and flexibility.
ScyllaDB is an open-source distributed NoSQL data store, reimplemented from the popular Apache Cassandra database. Released just four years ago in 2015, Scylla has averaged over 220% year-over-year growth in popularity according to DB-Engines. So what are some of the reasons why users would pick ScyllaDB vs. Cassandra?
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processesdata that are newly added or updated to a dataset, instead of re-processing the complete dataset.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA automates repetitive cloud operations tasks and streamlines the flow of analytics into decision-making processes.
By Vikram Srivastava and Marcelo Mayworm Netflix has one of the most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads. Pensive collects logs for the failed jobs launched by the step from the relevant data platform components and then extracts the stack traces.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. Adding AIOps to automation processes makes the volume of data that applications and multicloud environments generate much less overwhelming.
This, in turn, accelerates the need for businesses to implement the practice of software automation to improve and streamline processes. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI. Automate DevSecOps processes at scale.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The processeddata is typically stored as data warehouse tables in AWS S3.
Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud. However, this cannot be done without efficient, scalable data analytics.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for bigdataprocessing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges.
NoOps is a concept in software development that seeks to automate processes and eliminate the need for an extensive IT operations team. But it might also result in the entire software development process falling apart. Can organizations really function without an operations team? What is NoOps? Evolution of NoOps.
In today's world, data is generated in high volumes and to make something out of it, extracted data is needed to be transformed, stored, maintained, governed and analyzed. These processes are only possible with a distributed architecture and parallel processing mechanisms that BigData tools are based on.
Applications used in the field of BigDataprocess huge amounts of information, and this often happens in real time. Naturally, such applications must be highly reliable so that no error in the code can interfere with dataprocessing. This engine is written in Java and Scala. So, what is Apache Flink?
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. “The weakness of a data lake is they fail when you need to access them fast,” Pawlowski said.
Our customers have frequently requested support for this first new batch of services, which cover databases, bigdata, networks, and computing. See the health of your bigdata resources at a glance. Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our bigdata platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
Container orchestration is a process that automates the deployment and management of containerized applications and services at scale. Container orchestration enables organizations to manage and automate the many processes and services that comprise workflows.
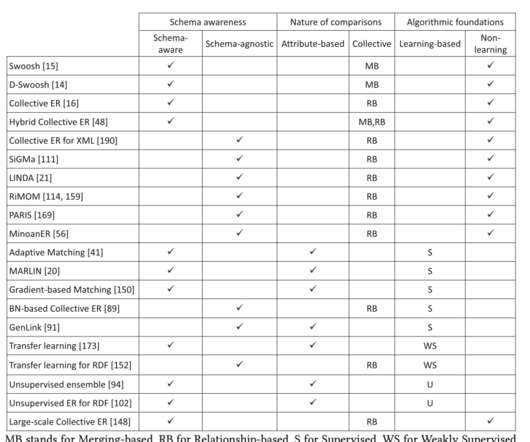
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. The processing mode – traditional batch (with or without budget constraints), or incremental. Block processing.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course, end-users that access these applications – including your customers and employees. With our AI engine, Davis, at the core Dynatrace provides precise answers in real-time. AI-Assistance.
The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases: NoSQL Data Models. Data duplication and denormalization are first-class citizens. Conceptual Techniques.
Stop worrying about log data ingest and storage — start creating value instead. Dynatrace® Grail , an additional core technology for the Dynatrace® Software Intelligence platform , is the world’s first data lakehouse with massively parallel processing (MPP) for context-rich observability, business, and security analytics.
Setting up a data warehouse is the first step towards fully utilizing bigdata analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Vikash Chhaganlal , GM of Engineering and Infrastructure at Kiwibank said it. Dynatrace CMO Mike Maciag talked about the dangers of “status quo” and failing to get where you need to go because of loyalty to legacy APM software, or hanging onto outdated processes. Investing in data is easy but using it is really hard”.
In fact, Gartner estimates that 80% of enterprises will shut down their on-premises data centers by 2025. This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. So, what is ITOps? What is ITOps? ITOps vs. AIOps.
Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Bigdata : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
To do this effectively, you need a bigdataprocessing approach. The three challenges to optimizing Core Web Vitals is exactly why the Dynatrace Business Insights team have built the Insights Analytics Engine. How do you know where to focus first with failing pages? How Dynatrace Business Insights can help.
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and dataprocessingengines like Hive and Spark. Working together, they form the backbone of many modern dataengineering solutions.
Apache Spark is a leading platform in the field of bigdataprocessing, known for its speed, versatility, and ease of use. Understanding Apache Spark Apache Spark is a unified computing engine designed for large-scale dataprocessing.
Gartner defines AIOps as the combination of “bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” But what is AIOps, exactly? And how can it support your organization? What is AIOps? Two approaches to AIOps.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. In this way, no human intervention is required in the remediation process. Multi-objective optimizations.
Membership Engineering at Netflix is responsible for the plan and pricing configurations for every market worldwide. To solve the challenges mentioned above and meet our rapidly evolving business needs, we re-architected the legacy SKU catalog from the ground up and partnered with the Growth Engineering team to build a scalable SKU platform.
Artificial intelligence for IT operations, or AIOps, combines bigdata and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. CloudOps includes processes such as incident management and event management. The four stages of dataprocessing.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
A hybrid cloud, however, combines public infrastructure and services with on-premises resources or a private data center to create a flexible, interconnected IT environment. Hybrid environments provide more options for storing and analyzing ever-growing volumes of bigdata and for deploying digital services.
Berkeley Packet Filter (BPF) is an in-kernel execution engine that processes a virtual instruction set, and has been extended as eBPF for providing a safe way to extend kernel functionality. What is BPF? In some ways, eBPF does to the kernel what JavaScript does to websites: it allows all sorts of new applications to be created.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course end-users that access these applications – including your customers and employees. With our AI engine, Davis, at the core Dynatrace provides precise answers in real-time. AI-Assistance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content