This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When handling large amounts of complex data, or bigdata, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Greenplum features a cost-based query optimizer for large-scale, bigdata workloads. Query Optimization.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. The design of the in-stream processing engine itself was driven by the following requirements: SQL-like functionality. Strict fault-tolerance is a principal requirement for the engine.
ScyllaDB is an open-source distributed NoSQL data store, reimplemented from the popular Apache Cassandra database. Released just four years ago in 2015, Scylla has averaged over 220% year-over-year growth in popularity according to DB-Engines. Wondering which wide-column store to use for your deployments? of all cloud deployments.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
To accomplish this, Uber relies heavily on making data-driven decisions at every level, from forecasting rider demand during high traffic events to identifying and addressing bottlenecks … The post Uber’s BigData Platform: 100+ Petabytes with Minute Latency appeared first on Uber Engineering Blog.
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning BigData into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
Then, bigdata analytics technologies, such as Hadoop, NoSQL, Spark, or Grail, the Dynatrace data lakehouse technology, interpret this information. Here are the six steps of a typical ITOA process : Define the data infrastructure strategy. Why use a data lakehouse for causal AI? Why is ITOA important? Apache Spark.
It is no surprise that Site Reliability Engineers have risen to prominence in the last decade. Modern IT infrastructure requires robust systems thinking and reliability engineering to keep the show on the road. Downtime is not an option. 88% showed that 60 minutes of downtime costs their business more than $300,000.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
By Vikram Srivastava and Marcelo Mayworm Netflix has one of the most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads. Pensive collects logs for the failed jobs launched by the step from the relevant data platform components and then extracts the stack traces.
Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud. Driving down the cost of Big-Data analytics. Comments ().
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges.
Uber leverages real-time analytics on aggregate data to improve the user experience across our products, from fighting fraudulent behavior on Uber Eats to forecasting demand on our platform. .
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
Python has long been a popular programming language in the networking space because it’s an intuitive language that allows engineers to quickly solve networking problems. Demand Engineering Demand Engineering is responsible for Regional Failovers , Traffic Distribution, Capacity Operations and Fleet Efficiency of the Netflix cloud.
Discover real-time query analytics and governance with DataCentral: Uber’s bigdata observability powerhouse, tackling millions of queries in petabyte-scale environments.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our bigdata platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. ACM Computing Surveys, Dec. 2020, Article No.
As organizations continue to adopt multicloud strategies, the complexity of these environments grows, increasing the need to automate cloud engineering operations to ensure organizations can enforce their policies and architecture principles. This requires significant dataengineering efforts, as well as work to build machine-learning models.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy.
These processes are only possible with a distributed architecture and parallel processing mechanisms that BigData tools are based on. One of the top trending open-source data storage that responds to most of the use cases is Elasticsearch.
Applications used in the field of BigData process huge amounts of information, and this often happens in real time. Naturally, such applications must be highly reliable so that no error in the code can interfere with data processing. It is an open-source framework for distributed processing of large amounts of data.
Our customers have frequently requested support for this first new batch of services, which cover databases, bigdata, networks, and computing. See the health of your bigdata resources at a glance. Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics.
Docker Swarm First introduced in 2014 by Docker, Docker Swarm is an orchestration engine that popularized the use of containers with developers. The Docker file format is used broadly for orchestration engines, and Docker Engine ships with Docker Swarm and Kubernetes frameworks included.
“AIOps platforms address IT leaders’ need for operations support by combining bigdata and machine learning functionality to analyze the ever-increasing volume, variety and velocity of data generated by IT in response to digital transformation.” – Gartner Market Guide for AIOps platforms.
Vikash Chhaganlal , GM of Engineering and Infrastructure at Kiwibank said it. She dispelled the myth that more bigdata equals better decisions, higher profits, or more customers. Investing in data is easy but using it is really hard”. The fact is, data on its own isn’t meaningful. And they were. That speaks to me.
Without automation, Performance engineers and developers can no longer ensure that applications perform as planned, and costs are minimized.”. Supported technologies include cloud services, bigdata, databases, OS, containers, and application runtimes like the JVM.
With our AI engine, Davis, at the core Dynatrace provides precise answers in real-time. Trying to manually keep up, configure, script and source data is beyond human capabilities and today everything must be automated and continuous. Some customers even say, having Davis is like having a whole team of engineers on their side.
Once identified, … The post Less is More: EngineeringData Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility?
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. “It’s quite a big scale,” said an engineer at the financial services group.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. Rule Execution Engine is responsible for matching the collected logs against a set of predefined rules.
—?and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. Photo from a team curling offsite?—?There’s There’s us to the right!
Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Bigdata : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
Membership Engineering at Netflix is responsible for the plan and pricing configurations for every market worldwide. To solve the challenges mentioned above and meet our rapidly evolving business needs, we re-architected the legacy SKU catalog from the ground up and partnered with the Growth Engineering team to build a scalable SKU platform.
To do this effectively, you need a bigdata processing approach. The three challenges to optimizing Core Web Vitals is exactly why the Dynatrace Business Insights team have built the Insights Analytics Engine. How do you know where to focus first with failing pages? How Dynatrace Business Insights can help.
Additionally, Grail delivers unrivaled performance without losing the precision of unsampled, gapless data. Dynatrace built and optimized it for Davis® AI, the game-changing Dynatrace artificial intelligence engine that processes billions of dependencies in the blink of an eye.
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. For example, a job would reprocess aggregates for the past 3 days because it assumes that there would be late arriving data, but data prior to 3 days isn’t worth the cost of reprocessing. past 3 hours or 10 days).
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and data processing engines like Hive and Spark. Working together, they form the backbone of many modern dataengineering solutions.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















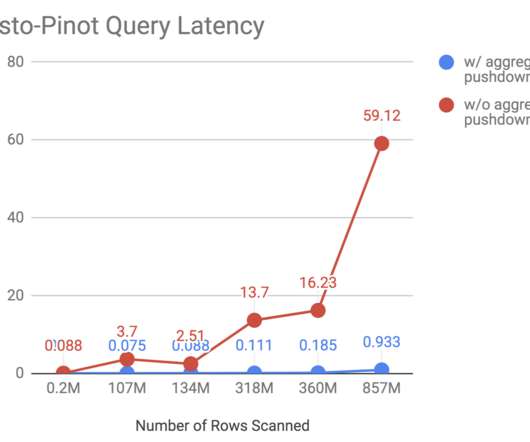





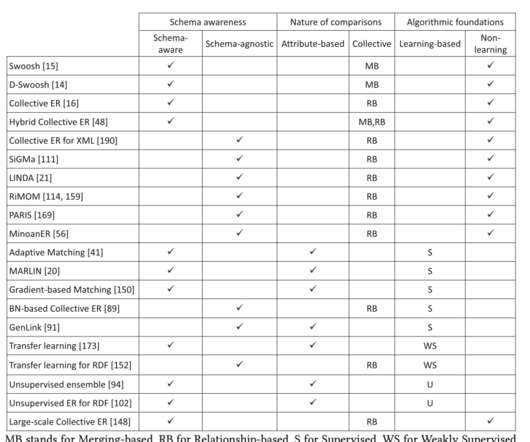

























Let's personalize your content