This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages.
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support bigdata processing. In addition, pySpark applications can be tuned to optimize performance and achieve better execution time, scalability, and resource utilization.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. The engine should be compact and efficient, so one can deploy it in multiple datacenters on small clusters. High performance and mobility. Pipelining.
In addition to improved IT operational efficiency at a lower cost, ITOA also enhances digital experience monitoring for increased customer engagement and satisfaction. Then, bigdata analytics technologies, such as Hadoop, NoSQL, Spark, or Grail, the Dynatrace data lakehouse technology, interpret this information.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
This is a guest post by Limor Maayan-Wainstein , a senior technical writer with 10 years of experience writing about cybersecurity, bigdata, cloud computing, web development, and more. When coupled with the cloud, HPC is made more affordable, accessible, efficient and shareable. What Is HPC?
Werner Vogels weblog on building scalable and robust distributed systems. Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud.
Boris has unique expertise in that area – especially in BigData applications. Marrying Artificial Intelligence and Automation to Drive Operational Efficiencies by Priyanka Arora, Asha Somayajula, Subarna Gaine, Mastercard. How to select appropriate IT Infrastructure to support Digital Transformation by Boris Zibitsker, BEZNext.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. “The weakness of a data lake is they fail when you need to access them fast,” Pawlowski said.
As cloud and bigdata complexity scales beyond the ability of traditional monitoring tools to handle, next-generation cloud monitoring and observability are becoming necessities for IT teams. Measure cloud resource consumption to ensure resources are scalable and keep up with business requirements. What is cloud monitoring?
Several pain points have made it difficult for organizations to manage their dataefficiently and create actual value. Limited data availability constrains value creation. Traditional solutions and approaches are inefficient given the number of manual tasks that are required for effective log data ingest.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The processed data is typically stored as data warehouse tables in AWS S3. Moving data with Bulldozer at Netflix.
The data is also used by security and other partner teams for insight and incident analysis. Summary Providing network insight into the cloud network infrastructure using eBPF flow logs at scale is made possible with eBPF and a highly scalable and efficient flow collection pipeline.
In the era of bigdata, efficientdata management and query performance are critical for organizations that want to get the best operational performance from their data investments.
To handle errors efficiently, Netflix developed a rule-based classifier for error classification called “Pensive.” To address this, we propose developing an intelligent agent that can automatically discover, map, and query all data within an enterprise.
NoSQL databases are often compared by various non-functional criteria, such as scalability, performance, and consistency. Besides this, elimination of these features had an extremely important influence on the performance and scalability of the stores. Many techniques that are described below are perfectly applicable to this model.
As Bigdata and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Another dimension of scalability to consider is the size of the workflow.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
We will show how we are building a clean and efficient incremental processing solution (IPS) by using Netflix Maestro and Apache Iceberg. IPS provides the incremental processing support with data accuracy, data freshness, and backfill for users and addresses many of the challenges in workflows. past 3 hours or 10 days).
Container technology enables organizations to efficiently develop cloud-native applications or to modernize legacy applications to take advantage of cloud services. Apache Mesos with the Marathon DC/OS is popular for large-scale production clusters running existing workloads on bigdata systems, such as Hadoop, Kafka, and Spark.
Operational Efficiency: The majority of the changes require metadata configuration files and library code changes, usually taking days of testing and service release to adopt the updates. This re-design enabled us to reposition the SKU catalog as an extensible, scalable, and robust rule-based “self-service” platform.
This article will help you understand the core differences in data structure, scalability, and use cases. Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. Choosing the right database often comes down to MongoDB vs MySQL.
Key features of RabbitMQ include message persistence to prevent data loss, flexible routing capabilities, and support for multiple messaging protocols such as AMQP, MQTT, and STOMP, enhancing its adaptability and reliability. Businesses can maintain a reliable and efficient communication system by utilizing message queues.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. They keep the features that developers like but can handle much more data, similar to NoSQL systems.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
With the launch of the AWS Europe (London) Region, AWS can enable many more UK enterprise, public sector and startup customers to reduce IT costs, address data locality needs, and embark on rapid transformations in critical new areas, such as bigdata analysis and Internet of Things. Fraud.net is a good example of this.
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
This approach allows companies to combine the security and control of private clouds with public clouds’ scalability and innovation potential. The public cloud’s ability to scale efficiently enables ‘cloudbursting’ when demand spikes without requiring businesses to overprovision their own infrastructures.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Werner Vogels weblog on building scalable and robust distributed systems. Now that our ability to generate higher and higher clock rates has stalled and CPU architectural improvements have shifted focus towards multiple cores, we see that it is becoming harder to efficiently use these computer systems. All Things Distributed.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Werner Vogels weblog on building scalable and robust distributed systems. AWS also applies the same customer oriented pricing strategy: as the AWS platform grows, our scale enables us to operate more efficiently, and we choose to pass the benefits back to customers in the form of cost savings. All Things Distributed. Comments ().
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
And it can maintain contextual information about every data source (like the medical history of a device wearer or the maintenance history of a refrigeration system) and keep it immediately at hand to enhance the analysis.
It is worth noting that if MapReduce is used for sorting of the original (not intermediate) data, it is often a good idea to continuously maintain data in sorted state using BigTable concepts. In other words, it can be more efficient to sort data once during insertion than sort them for each MapReduce query.
Alongside more traditional sessions such as Real-World Deployed Systems and BigData Programming Frameworks, there were many papers focusing on emerging hardware architectures, including embedded multi-accelerator SoCs, in-network and in-storage computing, FPGAs, GPUs, and low-power devices. ATC ’19 was refreshingly different.
However, the primary goal of traditional testing and cloud-based testing remains the same i.e., to deliver high-quality and efficient software. Data is present on the cloud hence can be accessed from any location. The environment is dynamic and scalable. Scalability is an issue since it needs to be addressed manually.
We’ve seen similar high marshalling overheads in bigdata systems too.) Fetching too much data in a single query (i.e., If you decompose data across multiple keys to avoid this, you then typically run into cross-key atomicity issues. getting the whole value when you supply the key). From RInK to LInK.
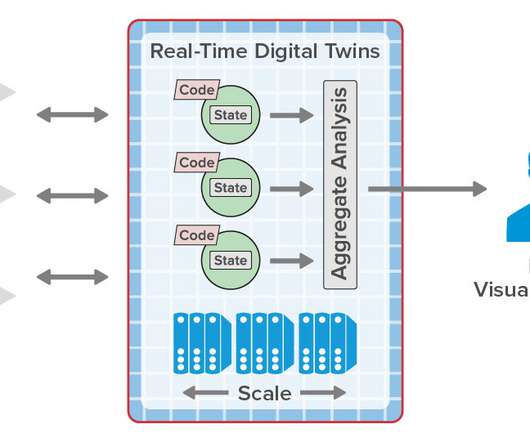
Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks. Rapid advances in the telematics industry have dramatically boosted the efficiency of vehicle fleets and have found wide ranging applications from long haul transport to usage-based insurance.
Werner Vogels weblog on building scalable and robust distributed systems. The broad Amazon EC2 customer base brings such diversity in workload and utilization patterns that it allows us to operate Amazon EC2 with extreme efficiency. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Comments ().
In the era of bigdata and complex data processing, data pipelines have emerged as a popular solution for managing and manipulating data. They provide a systematic approach to extract, transform, and load (ETL) data from various sources, enabling organizations to derive valuable insights.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content