This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for bigdata analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics.
By Vikram Srivastava and Marcelo Mayworm Netflix has one of the most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads. As our subscribers grow worldwide and Netflix enters the world of gaming , the number of batch workflows and real-time data pipelines increases rapidly.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
This aspect of NoSQL is well-studied both in practice and theory because specific non-functional properties are often the main justification for NoSQL usage and fundamental results on distributed systems like the CAP theorem apply well to NoSQL systems. Many techniques that are described below are perfectly applicable to this model.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy.
I love data. I have spent virtually my entire career looking at data. Synthetic data, network data, systemdata, and the list goes on. As much as I love data, data is cold, it lacks emotion. As much as I love data, data is cold, it lacks emotion. Often, 4s is too slow.
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer on the Product Data Science and Engineering team.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
This year’s conference agenda was packed full of choices, including: Keynotes : Topics included accelerating digital transformation, with Dynatrace CIO Mike Maciag, and Spatial Collapse: The Great Acceleration of Turning Data Into an Asset, with Tricia Wang from Sudden Compass. We’ve all heard it: data is one of your biggest assets.
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. Analysis of such large data sets often requires powerful distributed data stores like Hadoop and heavy data processing with techniques like MapReduce.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Werner Vogels weblog on building scalable and robust distributed systems. Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This technique facilitates validation on multiple fronts.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
Bigdata is at the center of all business decisions these days. It refers to large volumes of data generated through different sources, and this data then provides the foundation for business decisions. There are different ways through which we can process data. The size of data in batch processing is known.
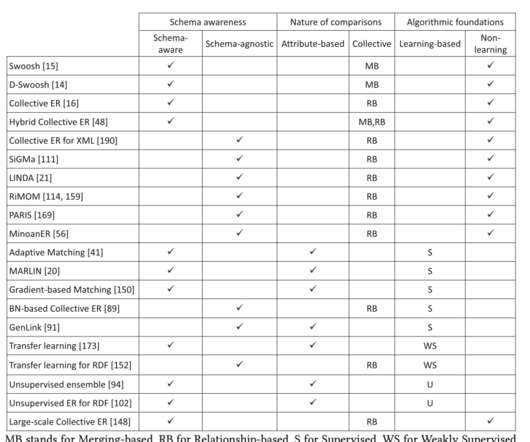
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. Open source ER systems. ACM Computing Surveys, Dec. 2020, Article No. All of the discussed approaches require schemas.
This can include the use of cloud computing, artificial intelligence, bigdata analytics, the Internet of Things (IoT), and other digital tools. One of the significant challenges that come with digital transformation is ensuring that software systems remain reliable and secure. This is where software testing comes in.
Bigdata is like the pollution of the information age. The BigData Struggle and Performance Reporting. Alternatively, a number of organizations have created their own internal home-grown systems for managing and distilling web performance and monitoring data. Insights At Any Level. Automatic Updates.
Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. The configuration of these devices is controlled by several other systems including source of truth, application of configurations to devices, and back up.
AIOps combines bigdata and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. Aggregation.
” I’ve called out the data field’s rebranding efforts before; but even then, I acknowledged that these weren’t just new coats of paint. Each time, the underlying implementation changed a bit while still staying true to the larger phenomenon of “Analyzing Data for Fun and Profit.” Goodbye, Hadoop.
Scripts and procedures usually focus on a particular task, such as deploying a new microservice to a Kubernetes cluster, implementing data retention policies on archived files in the cloud, or running a vulnerability scanner over code before it’s deployed. The range of use cases for automating IT is as broad as IT itself.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our bigdata platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
Retail is one of the most important business domains for data science and data mining applications because of its prolific data and numerous optimization problems such as optimal prices, discounts, recommendations, and stock levels that can be solved using data analysis methods.
Complex cloud computing environments are increasingly replacing traditional data centers. In fact, Gartner estimates that 80% of enterprises will shut down their on-premises data centers by 2025. The IT help desk creates a ticketing system and resolves service request issues. So, what is ITOps? Why is IT operations important?
Early implementations of NoOps were just ‘lift and shift’ efforts that replicated existing systems to the cloud. AIOps , a term coined by Gartner in 2016, combines bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection and causality determination. Evolution of NoOps.
Honestly, these two terms have recently been doing rounds in the bigdata world. Over the years, EDI has become a standard document exchange system, whereas API is on its way to becoming a popular alternative to EDI. API and EDI essentially fulfill the same function: getting data to and from two or more partners or recipients.
Several pain points have made it difficult for organizations to manage their data efficiently and create actual value. Limited data availability constrains value creation. Modern IT environments — whether multicloud, on-premises, or hybrid-cloud architectures — generate exponentially increasing data volumes.
At much less than 1% of CPU and memory on the instance, this highly performant sidecar provides flow data at scale for network insight. Flow Collector consumes two data streams, the IP address change events from Sonar via Kafka and eBPF flow log data from the Flow Exporter sidecars.
After every experiment run Akamas changes application, runtime, database or cloud configuration based on monitoring data it captured during the previous experiment run. Supported technologies include cloud services, bigdata, databases, OS, containers, and application runtimes like the JVM. or do you pull different percentiles?
Artificial intelligence for IT operations, or AIOps, combines bigdata and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. The four stages of data processing. There are four stages of data processing: Collect raw data. Analyze the data.
Containers enable developers to package microservices or applications with the libraries, configuration files, and dependencies needed to run on any infrastructure, regardless of the target system environment. This means organizations are increasingly using Kubernetes not just for running applications, but also as an operating system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content