This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
Efficient data processing is crucial for businesses and organizations that rely on bigdata analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
This article describes 3 different tricks that I used in dealing with bigdata sets (order of 10 million records) and that proved to enhance performance dramatically. Trick 1: CLOB Instead of Result Set.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-source data processing framework, has emerged as a game-changer in this domain.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support bigdata processing. Broadcast variables can be used to efficiently distribute large read-only data structures, such as lookup tables, to worker nodes.
ScyllaDB is an open-source distributed NoSQL data store, reimplemented from the popular Apache Cassandra database. ScyllaDB offers significantly lower latency which allows you to process a high volume of data with minimal delay. So what are some of the reasons why users would pick ScyllaDB vs. Cassandra? Google Cloud.
Amazon's worldwide financial operations team has the incredible task of tracking all of that data (think petabytes). At Amazon's scale, a miscalculated metric, like cost per unit, or delayed data can have a huge impact (think millions of dollars). The team is constantly looking for ways to get more accurate data, faster.
In an era where data is the new oil, effectively utilizing data is crucial for the growth of every organization. It is not enough to store these data durably, but also to effectively query and analyze them. Without a querying capability, the data stored in S3 would not be of any benefit.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for bigdata analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics.
By Vikram Srivastava and Marcelo Mayworm Netflix has one of the most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads. As our subscribers grow worldwide and Netflix enters the world of gaming , the number of batch workflows and real-time data pipelines increases rapidly.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
To accomplish this, Uber relies heavily on making data-driven decisions at every level, from forecasting rider demand during high traffic events to identifying and addressing bottlenecks … The post Uber’s BigData Platform: 100+ Petabytes with Minute Latency appeared first on Uber Engineering Blog.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. What is a data lakehouse? How does a data lakehouse work?
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
I love data. I have spent virtually my entire career looking at data. Synthetic data, network data, system data, and the list goes on. As much as I love data, data is cold, it lacks emotion. As much as I love data, data is cold, it lacks emotion. Often, 4s is too slow.
At the same time, NoSQL data modeling is not so well studied and lacks the systematic theory found in relational databases. In this article I provide a short comparison of NoSQL system families from the data modeling point of view and digest several common modeling techniques.
From driver and rider locations and destinations, to restaurant orders and payment transactions, every interaction on Uber’s transportation platform is driven by data.
Data Engineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “Data Engineers of Netflix” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Kevin Wylie is a Data Engineer on the Content Data Science and Engineering team.
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer on the Product Data Science and Engineering team.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
This year’s conference agenda was packed full of choices, including: Keynotes : Topics included accelerating digital transformation, with Dynatrace CIO Mike Maciag, and Spatial Collapse: The Great Acceleration of Turning Data Into an Asset, with Tricia Wang from Sudden Compass. We’ve all heard it: data is one of your biggest assets.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. What was your path to working in data? There’s us to the right!
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. Analysis of such large data sets often requires powerful distributed data stores like Hadoop and heavy data processing with techniques like MapReduce.
Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud. However, this cannot be done without efficient, scalable data analytics.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
Introduction With bigdata streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
Discover real-time query analytics and governance with DataCentral: Uber’s bigdata observability powerhouse, tackling millions of queries in petabyte-scale environments.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
Applications used in the field of BigData process huge amounts of information, and this often happens in real time. Naturally, such applications must be highly reliable so that no error in the code can interfere with data processing. It is an open-source framework for distributed processing of large amounts of data.
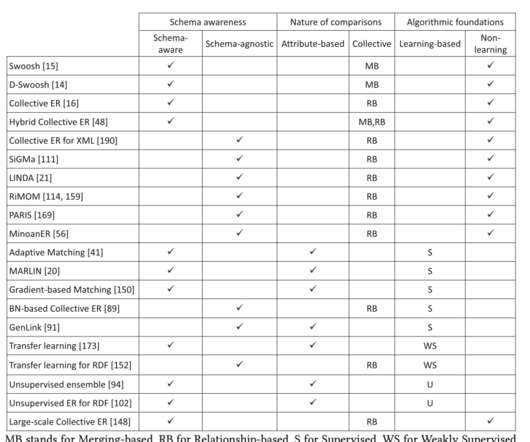
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. ACM Computing Surveys, Dec. 2020, Article No.
Bigdata is like the pollution of the information age. The BigData Struggle and Performance Reporting. Alternatively, a number of organizations have created their own internal home-grown systems for managing and distilling web performance and monitoring data. Insights At Any Level. Automatic Updates.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
In short, it is the ability to handle more data, more users, and more demand without sacrificing performance, reliability, or security. The reason is straightforward, today, applications generate enormous amounts of data. It is not uncommon to question why scalability has grabbed the attention of the masses these days.
Because with the advent of cloud providers, we are less worried about managing data centers. This leads to an increase in the size of data as well. Bigdata is generated and transported using various mediums in single requests. Everything is available within seconds on-demand.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI.
This is a guest post by Limor Maayan-Wainstein , a senior technical writer with 10 years of experience writing about cybersecurity, bigdata, cloud computing, web development, and more. High performance computing (HPC) enables you to solve complex problems which cannot be solved by regular computing.
The same applies to InfluxDB for time series data analysis. As NetEase expands its business horizons, the logs and time series data it receives explode, and problems like surging storage costs and declining stability come. These were exactly the choices of NetEase, one of the world's highest-yielding game companies but more than that.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content