This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream. Towards Unified BigData Processing.
Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. Additionally, for mismatches, we record the normalized and unnormalized responses from both sides to another bigdata table along with other relevant parameters, such as the diff.
Werner Vogels weblog on building scalable and robust distributed systems. Today AWS has launched Amazon ElastiCache , a new service that makes it easy to add distributed in-memory caching to any application. Systems that make extensive use of caching almost all report a significant reduction in the cost of their database tier.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. They keep the features that developers like but can handle much more data, similar to NoSQL systems.
Werner Vogels weblog on building scalable and robust distributed systems. Often these namespaces are hierarchical in nature such that it becomes easier to manage them and to decentralize control, which makes the system more scalable. There are two main types of DNS servers: authoritative servers and caching resolvers.
After the launch of the AWS APAC (Hong Kong) Region, there will be 19 Availability Zones in Asia Pacific for customers to build flexible, scalable, secure, and highly available applications. In 2010, we opened our first AWS Region in Singapore and since then have opened additional regions: Japan, Australia, China, Korea, and India.
Werner Vogels weblog on building scalable and robust distributed systems. The storage systems weve pioneered demonstrate extreme scalability while maintaining tight control over performance, availability, and cost. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. All Things Distributed.
Werner Vogels weblog on building scalable and robust distributed systems. If you have a largely static site you can rely on the enormous power of S3 to make serving your content highly scalable and storing it extremely durable. My templates and blog posts are now located in DropBox and thus locally cached at each machine I use.
Generally to cachedata (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. If you want to store time-expiring data that should be shared across application processes, used Memcached or Redis. Fetching too much data in a single query (i.e.,
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
Alongside more traditional sessions such as Real-World Deployed Systems and BigData Programming Frameworks, there were many papers focusing on emerging hardware architectures, including embedded multi-accelerator SoCs, in-network and in-storage computing, FPGAs, GPUs, and low-power devices. ATC ’19 was refreshingly different.
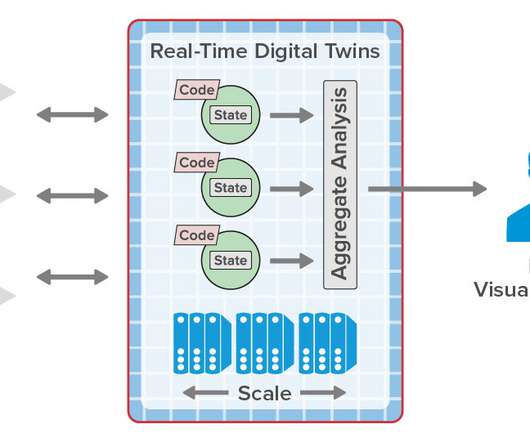
Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks. At the same time, telemetry snapshots are stored in a data lake, such as HDFS , for offline batch analysis and visualization using bigdata tools like Spark.
Heterogeneous and Composable Memory (HCM) offers a feasible solution for terabyte- or petabyte-scale systems, addressing the performance and efficiency demands of emerging big-data applications. The memory bandwidth will be a key player because the traditional method to add memory bandwidth by adding memory channels is not scalable.
Hyper Dimension Shuffle describes how Microsoft improved the cost of data shuffling, one of the most costly operations, in their petabyte-scale internal bigdata analytics platform, SCOPE. BlockchainDB – it’s a blockchain underneath, and a database on top.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content