This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When handling large amounts of complex data, or bigdata, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Greenplum features a cost-based query optimizer for large-scale, bigdata workloads. Query Optimization.
Efficient data processing is crucial for businesses and organizations that rely on bigdata analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
This article describes 3 different tricks that I used in dealing with bigdata sets (order of 10 million records) and that proved to enhance performance dramatically. Trick 1: CLOB Instead of Result Set.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-source data processing framework, has emerged as a game-changer in this domain.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. Other flows are more sophisticated: one Storm topology can pass the data to another topology via Kafka or Cassandra. Towards Unified BigData Processing. Apache Spark [10].
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support bigdata processing. PySpark is the Python API for Apache Spark , which allows Python developers to write Spark applications using Python instead of Scala or Java.
Google Cloud does offer their own wide column store and bigdata database called Bigtable which is actually ranked #111, one under ScyllaDB at #110 on DB-Engines. Google Cloud Platform (GCP) was the second most popular cloud provider for ScyllaDB, coming in at 30.4% of all cloud deployments.
Back when Jeff Bezos filled orders in his garage and drove packages to the post office himself, crunching the numbers on costs, tracking inventory, and forecasting future demand was relatively simple.
To accomplish this, Uber relies heavily on making data-driven decisions at every level, from forecasting rider demand during high traffic events to identifying and addressing bottlenecks … The post Uber’s BigData Platform: 100+ Petabytes with Minute Latency appeared first on Uber Engineering Blog.
From driver and rider locations and destinations, to restaurant orders and payment transactions, every interaction on Uber’s transportation platform is driven by data.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of bigdata, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing.
Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud. Driving down the cost of Big-Data analytics. Comments ().
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
Discover real-time query analytics and governance with DataCentral: Uber’s bigdata observability powerhouse, tackling millions of queries in petabyte-scale environments.
Introduction With bigdata streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
This is especially the case when it comes to taking advantage of vast amounts of data stored in cloud platforms like Amazon S3 - Simple Storage Service, which has become a central repository of data types ranging from the content of web applications to bigdata analytics.
Bigdata is like the pollution of the information age. The BigData Struggle and Performance Reporting. As the bigdata era brings in multiple options for visualization, it has become apparent that not all solutions are created equal. Conclusion.
Then, bigdata analytics technologies, such as Hadoop, NoSQL, Spark, or Grail, the Dynatrace data lakehouse technology, interpret this information. Here are the six steps of a typical ITOA process : Define the data infrastructure strategy. Why use a data lakehouse for causal AI? Why is ITOA important? Apache Spark.
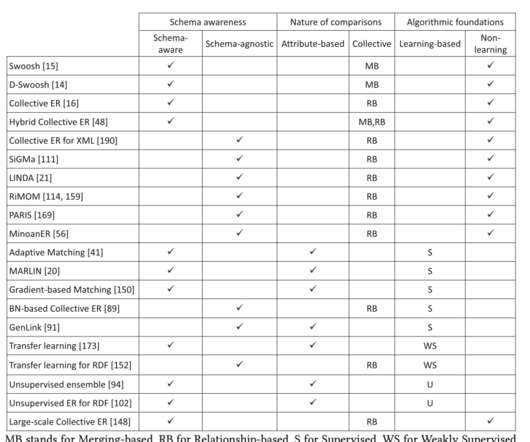
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. ACM Computing Surveys, Dec. 2020, Article No.
This is a guest post by Limor Maayan-Wainstein , a senior technical writer with 10 years of experience writing about cybersecurity, bigdata, cloud computing, web development, and more. High performance computing (HPC) enables you to solve complex problems which cannot be solved by regular computing.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for bigdata analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics.
The reason is straightforward, today, applications generate enormous amounts of data. As we embrace new technologies like cloud computing, bigdata analysis, and the Internet of Things (IoT), there is a noticeable spike in the amount of data generated from different applications.
Because with the advent of cloud providers, we are less worried about managing data centers. This leads to an increase in the size of data as well. Bigdata is generated and transported using various mediums in single requests. Everything is available within seconds on-demand.
This blog will explore these two systems and how they perform auto-diagnosis and remediation across our BigData Platform and Real-time infrastructure. The streaming platform recently added Data Mesh , and we need to expand Streaming Pensive to cover that.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves bigdata analytics and applying advanced AI and machine learning techniques, such as causal AI.
Bigdata is at the center of all business decisions these days. It refers to large volumes of data generated through different sources, and this data then provides the foundation for business decisions. There are different ways through which we can process data.
I was later hired into my first purely data gig where I was able to deepen my knowledge of bigdata. After that, I joined MySpace back at its peak as a data engineer and got my first taste of data warehousing at internet-scale. In the data engineering space, very little of the same technology remains.
Netflix’s unique work culture and petabyte-scale data problems are what drew me to Netflix. During earlier years of my career, I primarily worked as a backend software engineer, designing and building the backend systems that enable bigdata analytics.
Our customers have frequently requested support for this first new batch of services, which cover databases, bigdata, networks, and computing. See the health of your bigdata resources at a glance. Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics.
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., Microsoft’s bigdata clusters have 10s of thousands of machines, and are used by thousands of users to run some pretty complex queries. VLDB’19. For the larger more production-like query analysed in §4.2.1,
I still love data, but I am starting to love emotion-filled data. Big” data helps us make the right decisions and focus on the right things. It takes data back to its human roots and brings human data to our bigdata world. The post Giving data a heartbeat appeared first on Dynatrace blog.
In today's world, data is generated in high volumes and to make something out of it, extracted data is needed to be transformed, stored, maintained, governed and analyzed. These processes are only possible with a distributed architecture and parallel processing mechanisms that BigData tools are based on.
Netflix’s diverse data landscape made it challenging to capture all the right data and conforming it to a common data model. Spark is the primary big-data compute engine at Netflix and with pretty much every upgrade in Spark, the spark plan changed as well springing continuous and unexpected surprises for us.
“AIOps platforms address IT leaders’ need for operations support by combining bigdata and machine learning functionality to analyze the ever-increasing volume, variety and velocity of data generated by IT in response to digital transformation.” – Gartner Market Guide for AIOps platforms.
This kind of automation can support key IT operations, such as infrastructure, digital processes, business processes, and big-data automation. Bigdata automation tools. These tools provide the means to collect, transfer, and process large volumes of data that are increasingly common in analytics applications.
Setting up a data warehouse is the first step towards fully utilizing bigdata analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Honestly, these two terms have recently been doing rounds in the bigdata world. These technologies specialize in transmitting large amounts of data across different trading partners and companies.
Nowadays, BigData tests mainly include data testing, paving the way for the Internet of Things to become the center point. Digital transformation is yet another significant focus point for the sectors and the enterprises that are ranking top on cloud and business analytics. Besides, AI and ML seem to reach a new level.
Applications used in the field of BigData process huge amounts of information, and this often happens in real time. Naturally, such applications must be highly reliable so that no error in the code can interfere with data processing. It is an open-source framework for distributed processing of large amounts of data.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our bigdata platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
While data lakehouses combine the flexibility and cost-efficiency of data lakes with the querying capabilities of data warehouses, it’s important to understand how these storage environments differ. Data warehouses. Data warehouses were the original bigdata storage option.
Orchestration The BigData Orchestration team is responsible for providing all of the services and tooling to schedule and execute ETL and Adhoc pipelines. These libraries are the primary way users interface programmatically with work in the BigData platform.
She dispelled the myth that more bigdata equals better decisions, higher profits, or more customers. Investing in data is easy but using it is really hard”. The fact is, data on its own isn’t meaningful. Tricia quoted the statistic that companies typically use 3% of their data to inform decisions.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content