This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. In a talent-constrained market, the best strategy could be to develop expertise from within the organization.
Visibility into system activity and behavior has become increasingly critical given organizations’ widespread use of Amazon Web Services (AWS) and other serverless platforms. These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor.
With over 80% of workloads worldwide virtualized, virtualization security is a concern for organizations regardless of size, goal, and industry. Proper protection systems for a particular organization's workloads and data are necessary to support production and service availability. In this post, we explain:
For enterprises managing complex systems and vast datasets using traditional log management tools, finding specific log entries quickly and efficiently can feel like searching for a needle in a haystack. Fast and efficient log analysis is critical in todays data-driven IT environments.
PayPal, a popular online payment systems organization, implemented a full performance as a self-service model for developers to get their code performance tests. Read more details about PayPal in this blog who is an early practitioner for performance as a self-service. #2 2 New roles and responsibilities at Panera Bread .
Query your data with natural language Davis CoPilot is an excellent virtual assistant that helps you create queries using natural language. For more information on optimizing your prompts and bestpractices, check out the topic Tips for writing better prompts. Looking for something?
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
Manually managing and securing multi-cloud environments is no longer practical. Monitoring and logging tools that once worked well with earlier IT architectures no longer provide sufficient context and integration to understand the state of complex systems or diagnose and correct security issues. Get started with DevOps orchestration.
Vulnerability assessment is the process of identifying, quantifying, and prioritizing the cybersecurity vulnerabilities in a given IT system. The goal of an assessment is to locate weaknesses that can be exploited to compromise systems. Changing system configurations. Identify vulnerabilities. Analyze findings. Assess risk.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Five example SLOs for faster, more reliable apps 1.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Because a third party manages part of the infrastructure, IT teams give up a measure of control over system architecture. Functional FaaS bestpractices. These include the following: Reduced control. Limited visibility.
Perform serves yearly as the marquis Dynatrace event to unveil new announcements, learn about new uses and bestpractices, and meet with peers and partners alike. If you’re unable to join us in Las Vegas, be sure to register to attend virtually —or view sessions on-demand afterward—so you don’t miss out!
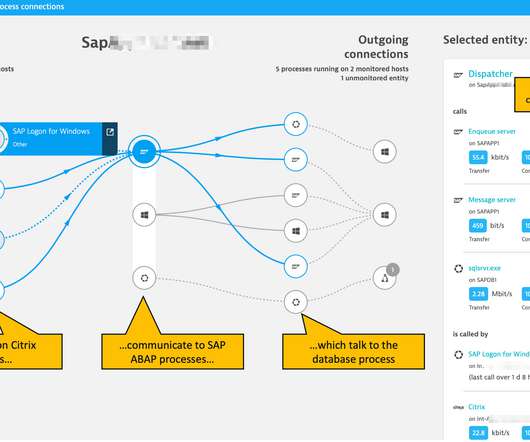
SAP estimates that 80% of all worldwide business transactions touch SAP systems in some form. The SAP Basis team needs a comprehensive picture of infrastructure performance and dependencies that determine their SAP system’s performance. Why SAP ABAP platform monitoring in Dynatrace? What is ABAP platform monitoring?
Application security monitoring is the practice of monitoring and analyzing applications or software systems to detect vulnerabilities, identify threats, and mitigate attacks. Forensics focuses on the systemic investigation and analysis of digital evidence to determine root causes.
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. However, to be secure, containers must be properly isolated from each other and from the host system itself. Bestpractices for container security.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Getting precise root cause analysis when dealing with several layers of virtualization in a containerized world. The Framework is built on five pillars of architectural bestpractices: Cost optimization. Analyzing user experience to ensure uniform performance after migration. Operational excellence. Performance efficiency.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. Kelsey Hightower via Twitter, 2020).
What Dynatrace deployment is the best fit for your technology stack, and is the OneAgent compatible with your system? Before writing a OneAgent plugin, it’s always bestpractice to check that the metric(s) you want to add are not already in Dynatrace. OneAgent & application metrics. OneAgent & cloud metrics.
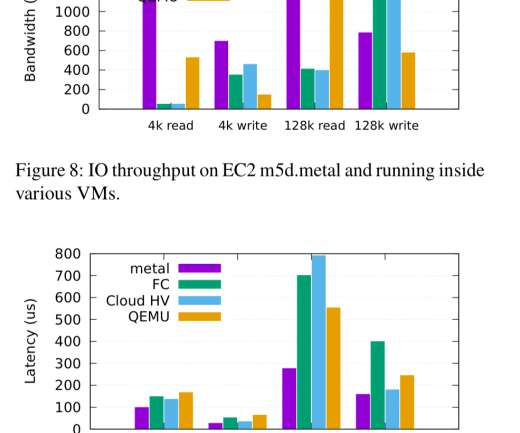
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead.
SAP estimates that 80% of all worldwide business transactions touch SAP systems in some form. The SAP Basis team needs a comprehensive picture of infrastructure performance and dependencies that determine their SAP system’s performance. Why SAP ABAP platform monitoring in Dynatrace? What is ABAP platform monitoring?
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Monolithic software systems employ one large codebase, which includes collections of tools, software development kits, and associated development dependencies. Because monolithic software systems employ one large codebase repository, the service becomes a massive piece of software that is labor-intensive to manage.
Process Improvements (50%) The allocation for process improvements is devoted to automation and continuous improvement SREs help to ensure that systems are scalable, reliable, and efficient. Reality In practice, while both these categories have equal attention, project improvements hold paramount importance for business outcomes.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Operations teams want to make sure the system doesn’t break. Keptn includes bestpractices that help developers choose which sequences to use.
Observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. Comprehensive observability eliminates siloed views of the system and establishes a common means to observe, measure, and act on insights. Check out the full webinar here! Want to learn more?
Virtually any application with a user interface can benefit from regular real user monitoring. Analyzing a clinician’s clickstream when using an electronic medical record system to better improve the efficiency of data entry. Bestpractices for RUM. Examples of real user monitoring.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Latency primarily focuses on the time spent in transit.
Database architects working with MongoDB encounter specific challenges related to database systems and system growth. Sharding is a preferred approach for database systems facing substantial growth and needing high availability. If one of these situations becomes a bottleneck in your system, you start a cluster.
Combining the power of automation with version-controlled configurations lands us at GitOps – you describe the configuration of your system as a set of files that you process and apply in an environment. Support all the mechanisms and best-practices of git-based workflows such as pull requests, merging and approvals.
Our Cloud Automation Roadshow brings the latest cloud-native automation practices to our attendees. Last week we kicked it off with a three-hour virtual hands-on workshop. The initial plan was to do it onsite in Ohio, but – I guess I don’t have to tell you why – we decided to start virtual first.
Follow fundamental procedures in authentication, encryption, and commitment to RabbitMQ security protocols to protect your RabbitMQ system and secure messages. The continuous security of your messaging system hinges on persistent monitoring and routine updates. This article provides instructions on how to fortify your RabbitMQ setup.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. Without further ado, let’s start with the OS settings. 25.84 - Total 21.04
Simply put, it’s the set of computational tasks that cloud systems perform, such as hosting databases, enabling collaboration tools, or running compute-intensive algorithms. Such demanding use cases place a great value on systems capable of fast and reliable execution, a need that spans across various industry segments.
We’re currently in a technological era where we have a large variety of computing endpoints at our disposal like containers, Platform as a Service (PaaS), serverless, virtual machines, APIs, etc. Treating these different processes as code will ensure that bestpractices are followed. with more being added continually.
On April 24, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. I held out hope that tweaking my system prompt would improve performance.
Enter AI observability, which uses AI to understand the performance and cost-effectiveness details of various systems in an IT environment. Join us at Dynatrace Perform 2024 , either on-site or virtuall y, to explore these themes further. As organizations adopt more AI technologies, the associated costs are skyrocketing.
Watch Now : Using Open Source Software to Secure Your MongoDB Database MongoDB Security Features and BestPractices Authentication in MongoDB Most breaches involving MongoDB occur because of a deadly combination of authentication disabled and MongoDB opened to the internet. Thankfully, LDAP can fill many of these gaps.
Virtually every business relies on outside service providers for anything from web servers to third-party APIs enabling their app functionality for the end user. Together they demonstrate our commitment to information security bestpractices and delivering the best value for customers. ISO 27001 Certification.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Some disruption might occur, but it will be minimal. Fault tolerance aims for zero downtime and data loss.
Let’s review the bestpractices we usually follow in Managed Services before using your MySQL server in production and stage env, even for home play purposes. Changing the value directly influences the performance of the Linux system. It’s a nice thing to do, but first things first. 1 Let’s quickly fix it.
What follows is overall best-practice advice for designing with latency in mind. If you are, you probably get some or all of the next sections for free anyway… Use a Fast DNS Provider One of the first things a new visitor will have to do to access your site is resolve the IP address using the Domain Name System (DNS).
The VictoriaMetrics team has also published some bestpractices , which can also be referred to while planning for resources for setting up PMM2. Virtual Memory utilization was averaging 48 GB of RAM. We have tested PMM version 2.33.0 The CPU usage averaged 24% utilization, as you can see in the above picture.
This post complements the previous bestpractice guides this time with the focus on MySQL and MariaDB and achieving top levels of performance with the HammerDB MySQL TPC-C test. As is exactly the same with PostgreSQL for system choice a 2 socket system is optimal for MySQL OLTP performance. perf special. monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content