This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
API resilience is about creating systems that can recover gracefully from disruptions, such as network outages or sudden traffic spikes, ensuring they remain reliable and secure. This has become critical since APIs serve as the backbone of todays interconnected systems.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Visibility into system activity and behavior has become increasingly critical given organizations’ widespread use of Amazon Web Services (AWS) and other serverless platforms. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring bestpractices.
Here, we’ll tackle the basics, benefits, and bestpractices of IAC, as well as choosing infrastructure-as-code tools for your organization. Infrastructure as code is a practice that automates IT infrastructure provisioning and management by codifying it as software. Exploring IAC bestpractices. Consistency.
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. Why Black Friday traffic threatens customer experience.
Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. Aligning site reliability goals with business objectives Because of this, SRE bestpractices align objectives with business outcomes. Make SLOs realistic.
Self-service content management systems, for instance, allow non-IT staff to make content changes on production systems. For instance, when there isn’t enough traffic (late at night), the AI will not act to avoid alert spamming. The post Bestpractices for alerting appeared first on Dynatrace blog.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. However, not all user monitoring systems are created equal. RUM, however, has some limitations, including the following: RUM requires traffic to be useful. Watch webinar now!
Closed loop” refers to the continuous feedback loop in which the system takes actions — based on monitoring and analysis — and verifies the results to ensure complete problem remediation. The goal is to either improve or restore the system to its optimally functioning state. If successful, the system closes the loop and notifies teams.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. Distributed cloud systems are complex, dynamic, and difficult to manage without the proper tools. What is log management?
All of this puts a lot of pressure on IT systems and applications. In this article, I will share some of the bestpractices to help you understand and survive the current situation — as well as future proof your applications and infrastructure for similar situations that might occur in the months and years to come.
In the dynamic world of microservices architecture, efficient service communication is the linchpin that keeps the system running smoothly. In this comprehensive guide, we’ll delve into the world of service meshes and explore bestpractices for their effective management within a microservices environment.
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Ransomware encrypts essential data, locking users out of systems and halting operations until a ransom is paid. This often occurs during major events, promotions, or unexpected surges in usage.
Technical : Specifies technical requirements for ICT systems within an organization. Automatically and continuously checking systems to see if they meet the latest security standards not only helps organizations pass annual compliance audits but also reduces the risks of cyber security incidents.
Improving testing by using real traffic from production ( Hacker News). Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & BestPractices). Using MongoDB as a cache store ( Architects Zone – Architectural Design Patterns & BestPractices). History of Lisp ( Hacker News).
Application security monitoring is the practice of monitoring and analyzing applications or software systems to detect vulnerabilities, identify threats, and mitigate attacks. Forensics focuses on the systemic investigation and analysis of digital evidence to determine root causes.
We’ll answer that question and explore cloud migration benefits and bestpractices for how to go through your migration smoothly. In case of a spike in traffic, you can automatically spin up more resources, often in a matter of seconds. Likewise, you can scale down when your application experiences decreased traffic.
In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic. For more information on optimizing your prompts and bestpractices, check out the topic Tips for writing better prompts.
In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives. The Dynatrace ACE services team has experience helping customers with defining and implementing SLOs. Reliability.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. Five example SLOs for faster, more reliable apps 1. The Apdex score of 0.85
Tracking changes to automated processes, including auditing impacts to the system, and reverting to the previous environment states seamlessly. Allowing architectures to be nimble and evolve over time, allowing organizations to take advantage of innovations as a standard practice. Fully conceptualizing capacity requirements.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The final status update was at 6:54PM PDT with a very detailed description of the temperature rise that caused the shutdown initially, followed by the fire suppression system dispersing some chemicals which prolonged the full recovery process.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. Siloed teams and multiple tools make it difficult to align on a single version of the truth for overall system health.
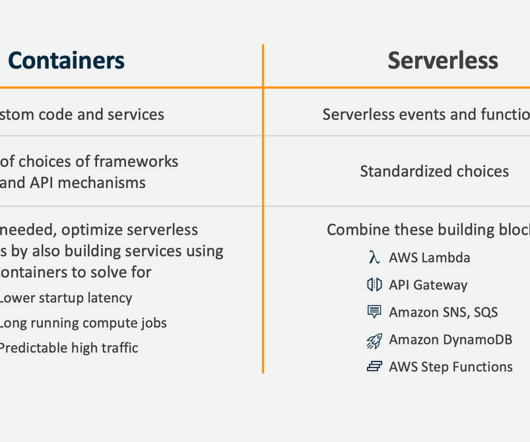
For example, to handle traffic spikes and pay only for what they use. Observability is essential to ensure the reliability, security and quality of any software system. Scale automatically based on the demand and traffic patterns. The elasticity of serverless services helps organizations scale as needed.
Every organization’s goal is to keep its systems available and resilient to support business demands. Lastly, error budgets, as the difference between a current state and the target, represent the maximum amount of time a system can fail per the contractual agreement without repercussions. Dynatrace news. A world of misunderstandings.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success.
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. Error budget burn rate = Error Rate / (1 – Target) Bestpractices in SLO configuration To detect if an entity is a good candidate for strong SLO, test your SLO.
Database architects working with MongoDB encounter specific challenges related to database systems and system growth. Sharding is a preferred approach for database systems facing substantial growth and needing high availability. If one of these situations becomes a bottleneck in your system, you start a cluster.
The Marriott data breach, in which one of its reservation systems had been compromised and hundreds of millions of customer records, including credit card and passport numbers, were stolen. SAST tools identify problematic coding patterns that go against bestpractices. million Americans, 15.2
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. Availability is typically expressed in 9’s, such as 99.9%. The Apdex score of 0.85
DevOps bestpractices include testing within the CI/CD pipeline, also known as shift-left testing. Synthetic CI/CD testing simulates traffic to add an outside-in view to the analysis. SREs visualize the state of the system they’re responsible for with powerful Dynatrace dashboards.
Log auditing is a cybersecurity practice that involves examining logs generated by various applications, computer systems, and network devices to identify and analyze security-related events. It requires an understanding of cloud architecture and distributed systems, with the goal of automating processes.
Then they tried to scale it to cope with high traffic and discovered that some of the state transitions in their step functions were too frequent, and they had some overly chatty calls between AWS lambda functions and S3. They state in the blog that this was quick to build, which is the point.
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. A big factor in good Digital Performance is the back-end system that powers your digitally offered use-cases. Impressive results I have to say!
We were able to meaningfully improve both the predictability and performance of these containers by taking some of the CPU isolation responsibility away from the operating system and moving towards a data driven solution involving combinatorial optimization and machine learning. can we actually make this work in practice?
We’ll also cover how to instrument the services using OpenTelemetry, and some bestpractices for how to define spans and traces manually. By *instrumenting* a system (for example, an application), you enhance its capabilities to be able to send the desired telemetry data. heapUsed); }); What to trace?
This operational component places some cognitive load on our engineers, requiring them to develop deep understanding of telemetry and alerting systems, capacity provisioning process, security and reliability bestpractices, and a vast amount of informal knowledge about the cloud infrastructure.
Key features of RabbitMQ, such as message acknowledgments, complex routing, and asynchronous processing, contribute to system reliability and performance. They utilize a routing key mechanism that ensures precise navigation paths for message traffic. This non-blocking nature improves the system’s responsiveness and efficiency.
Number of slow queries recorded Select types, sorts, locks, and total questions against a database Command counters and handlers used by queries give an overall traffic summary Along with this, PMM also comes with Query Analytics giving much detailed information about queries getting executed.
As a MongoDB user, it’s crucial to ensure that your data is safe and secure in the event of a disaster or system failure. That’s why it’s essential to implement the bestpractices and strategies for MongoDB database backups. Why are MongoDB database backups important? mongorestore --host=mongodb1.example.net
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. Without further ado, let’s start with the OS settings. 25.84 - Total 21.04
Watch Now : Using Open Source Software to Secure Your MongoDB Database MongoDB Security Features and BestPractices Authentication in MongoDB Most breaches involving MongoDB occur because of a deadly combination of authentication disabled and MongoDB opened to the internet. Thankfully, LDAP can fill many of these gaps.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content