This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads. Monitoring the cluster nodes preemptively addresses potential issues, ensuring the system operates smoothly.
By automating OneAgent deployment at the image creation stage, organizations can immediately equip every EC2 instance with real-time monitoring and AI-powered analytics. This integration allows organizations to correlate AWS events with Dynatrace automatic dependency mapping, real-time performance monitoring, and root-cause analysis.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. In a talent-constrained market, the best strategy could be to develop expertise from within the organization.
Old School monitoring. Basically, what we call “first-generation” monitoring software. Typically, applications owners who have little or no experience in monitoring, give requirements such as: “If there are more than 2 HTTP errors code (4xx and 5xx) report it immediately” or report any errors in the logs etc.
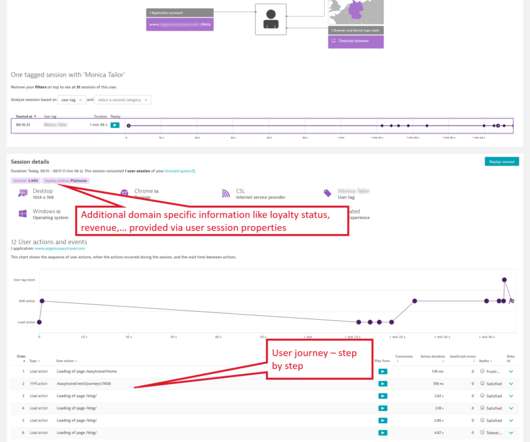
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Follow along to create this host monitoring dashboard We will create a basic Host Monitoring dashboard in just a few minutes. Create a new dashboard.
We address this requirement in Dynatrace by proudly announcing key user actions for mobile app monitoring—a great new feature for you to monitor your most important mobile app KPIs, providing you with a good foundation to drive lasting customer loyalty and grow your business.
Cloud security monitoring is key—identifying threats in real-time and mitigating risks before they escalate. This article strips away the complexities, walking you through bestpractices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. What does it take to secure your cloud assets effectively?
Building services that adhere to software bestpractices, such as Object-Oriented Programming (OOP), the SOLID principles, and modularization, is crucial to have success at this stage. Implement proactive monitoring for each of these endpoints. Track real-time title impressions from the NetflixUI. there is a dedicated collector.
Cost optimization: Immediate responses to tag changes lead to informed decisions about scaling, shutting down unused instances, or fine-tuning resource efficiency. Proactive site reliability: Automated guardians can monitor the four golden signals , enabling proactive reliability measures. Now, let’s get started with the setup!
Most performance engineers have spent years submitting RFPs, developing scripts, executions, analysis, monitoring and tuning, and researching their specific projects/product domains and have gained a very high level of expertise in it. and must have extensive experience in specialized skills.
Configuring monitoring and observability is no stranger to that paradigm and it was also highlighted in the latest State of DevOps 2020 report. Defining what to monitor and what to be alerted on must be as easy for developers as checking in a monitoring configuration file into version control along with the applications source code.
This blog post focuses on pipeline observability as a method for monitoring the software delivery capabilities of an organization’s IDP. These phases must be aligned with security bestpractices, as discussed in A Beginner`s Guide to DevOps. Synthetic HTTP monitors are executed in the hardening stage.
Our new eBook, “ From Planning to Performance: MongoDB Upgrade BestPractices ,” guides you through the entire process to ensure your database’s long-term success. Improved performance : MongoDB continually fine-tunes its database engine, resulting in faster query execution and reduced latency.
Operations refers to the processes of managing software functionality throughout its delivery and use life cycle, including monitoring system performance, repairing defects, testing after updates and changes, and tuning the software release system. Operations. The same holds true of DevSecOps initiatives. Challenge accepted.
CD depends on automated testing, and test pass rate helps you fine tune testing methods and improve the effectiveness of your developer feedback loop. Bestpractices for adopting continuous delivery. Building a fast and reliable release process requires implementing quality checks, logging practices, and monitoring solutions.
Well-Architected Reviews are conducted by AWS customers and AWS Partner Network (APN) Partners to evaluate architectures to understand how well applications align with the multiple Well-Architected Framework design principles and bestpractices. through our AWS integrations and monitoring support.
Unlike traditional monitoring, which focuses on watching individual metrics for system health indicators with no overall context, observability goes deeper , analyzing telemetry data for a comprehensive view of the system’s internal state in context of the wider system. There are three main types of telemetry data: Metrics.
In this two-part blog series you’ll learn how to easily handle the monitoring challenges posed by Content Delivery Networks (CDNs) and 3rd-party integrations. How to analyze issues with enhanced Dynatrace HTTP error monitoring and troubleshooting. Analyze issues with enhanced HTTP error monitoring and troubleshooting.
A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Embracing cloud native bestpractices to increase automation. Monitoring such an application is easy. Along with selected namespaces, Dynatrace automatically monitors Kubernetes nodes.
Configuration files allow for the automatic creation, update, and management of configurations for dashboards, synthetic monitors, alerts, SLOs, and security settings across multiple environments. GitOps is a best-practice methodology for handling operation-relevant configurations that can be applied across the entire Dynatrace platform.
Dynatrace provides the most comprehensive support for observability, including serverless technologies such as AWS Lambda, Azure Functions and Google Cloud Functions: A simple and unified integration to capture platform metrics from AWS CloudWatch, Azure Monitor and Google Operations Suite.
More recently, teams have begun to apply DevOps bestpractices to infrastructure automation, giving developers a more active role with GitOps as an operational framework. Because of these issues, developers often still lack control over the behavior of their monitoring platform.
This approach helps you quickly integrate bestpractices within your organization and provides cloneable artifacts for rapid product development. Ensure governance across your organization While Golden Paths are key to bringing DevOps bestpractices to development teams, distributing them is challenging.
Part 1 of this series starts will cover the key ingredients needed for successful DevOps use to deliver better software faster, followed by a short overview of GitHub Actions and example use cases related to deployment and release monitoring. Key ingredients required to deliver better software faster. Kubernetes pod attributes.
By following these bestpractices, you can ensure efficient and safe data management, allowing you to focus on extracting value from Dynatrace while maintaining smooth and compliant business operations. Check our Privacy Rights documentation to stay tuned to our continuous improvements.
For instance, consider how fine-tuned failure rate detection can provide insights for comprehensive understanding. Please refer to How to fine-tune failure detection (dynatrace.com) for further information. Let’s assume we created a service-availability SLO, monitoring the request failure count against the overall request counts.
These examples can help you define your starting point for establishing DevOps and SRE bestpractices in your organization. We use monitored demo applications to deliver constant load and a defined set of business transactions.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
SAST tools identify problematic coding patterns that go against bestpractices. Positive filters are highly effective at blocking attacks but require constant tuning. Teams need to verify and potentially adjust this tuning every time the application changes. Transforms add layers of protection to the web application.
First of all, it is MongoDB and Atlas documentation: Performance , Monitoring , and Query Optimization. Atlas Performance Overview and Monitor Your Cluster documentation. There are many great blog posts: Performance BestPractices 7-parts series. We do have a lot of great resources that can help with MongoDB performance.
As you probably know, Dynatrace is the leading Software Intelligence Platform, focused on web-scale cloud monitoring. Stay tuned for further updates! In an upcoming blog post I will dig deeper into how to deploy Dynatrace in hardened environments and bestpractices for these types of deployments. Dynatrace Managed.
You work with the DevSecOps teams on one hand, guiding them through the bestpractices of secure development and deployment. For any of the tiles in the notebook, you can also create automation to continuously monitor the findings, based on the underlying query and orchestrate them.
With reliable SLOs, you can set up automation to monitor and measure SLIs and set alerts if certain indicators are trending toward violation. Gathering and analyzing metrics over time will help you determine the overall effectiveness of your SLOs so you can tune them as your processes mature and improve. SLO bestpractices.
This article will cover many areas that database administrators need to be aware of in order to properly license, recover, and tune a Reporting Services installation. Bestpractice for DBAs is really to just treat ReportServer and ReportServerTempDB like any other user database. Tuning Options. General Tuning.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. The bestpractices in those fields have always centered around rigorous evaluation cycles.
It involves careful monitoring to determine when to add nodes and how to distribute data and load across the system without causing disruptions or bottlenecks. It requires implementing scalable architecture from the outset and continuously monitoring performance data to predict when to scale.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. Spoiler alert: This post focuses on MongoDB 3.6.X tcp_fin_timeout = 30 net.ipv4.tcp_keepalive_intvl
My last talk for 2017 was at AWS re:Invent, on "How Netflix Tunes EC2 Instances for Performance," an updated version of my [2014] talk. Our team looks after the BaseAMI, kernel tuning, OS performance tools and profilers, and self-service tools like Vector. We help where we can. html [Introducing Nitro]: [link]
My last talk for 2017 was at AWS re:Invent, on "How Netflix Tunes EC2 Instances for Performance," an updated version of my [2014] talk. Our team looks after the BaseAMI, kernel tuning, OS performance tools and profilers, and self-service tools like Vector. We help where we can. html [Introducing Nitro]: [link]
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
Regular monitoring, logging, and compliance with industry regulations such as PCI-DSS, HIPAA, and GDPR increase RabbitMQ security by enabling audit trails and timely incident response. The continuous security of your messaging system hinges on persistent monitoring and routine updates.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
An approach to improve a query which cannot be avoided will be: Monitor slow query log and use pt-query-digest to generate a summary report for slow queries. Additional read Mike’s blog on How to Find and Tune a Slow SQL Query Q: What is your disaster recovery (DR) strategy? A: Well, it is our delayed disaster recovery.
These guidelines are based on my experience with many IT companies over the years and in-depth research using real-life bestpractices and expertise from many sources, including. Performance Architects. Many customer testing organizations. Performance CoE Managers. Performance Engineers. QA Managers. Development Managers.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content