This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Observability: Elevating Logs, Metrics, and Traces! What is Fluent Bit?
By proactively implementing digital experience monitoring bestpractices and optimizing user experiences , organizations can increase long-term customer satisfaction and loyalty, drive business value , and accelerate innovation. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools.
These development and testingpractices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. RUM gathers information on a variety of performance metrics. RUM is ideally suited to provide real metrics from real users navigating a site or application.
This blog post introduces the new REST API improvements and some bestpractices for streamlining API requests and decreasing load on the API by reducing the number of requests required for reporting and reducing the network bandwidth required for implementing common API use cases.
Many of these projects are under constant development by dedicated teams with their own business goals and development bestpractices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent. ' # settings.configuration.EXP_01.yaml
Synthetic testing simulates real-user behaviors within an application or service to pinpoint potential problems. Here’s a look at why this testing matters, how it works, and what companies need to get the most from this approach. What is synthetic testing? RUM, meanwhile, requires actual users.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. Bestpractices for implementing service-level objectives.
Credits on content go to him and the work he has been doing around performance & resiliency testing automation. Our Application Performance Management (APM) and load test team at T-Systems MMS helps our customers reduce the risk of failed releases. Automation : Single load test executions can be repeated and tracked.
CD is the next step in the process that automates the delivery of applications to selected infrastructure environments, such as a development environment for a related feature, or testing environments to verify feature functionality and proper integration with other parts of the software. Testing quality improves. Test pass rate.
After a new build gets deployed and automated tests executed, SLIs are evaluated against their SLOs and, depending on that result, a build is considered good (promoted) or bad (rolled back). “ The app description and supporting files such as load testing scripts are on the Keptn Example GitHub. This is what this blog is all about.
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Bestpractices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern.
One way to apply improvements is transforming the way application performance engineering and testing is done. This involves new software delivery models, adapting to complex software architectures, and embracing automation for analysis and testing. Check out Dynatrace’s Load testing tool integration. Get started today! .
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
While DORA provides high-level definitions, other regulatory frameworks (such as CIS or DISA-STIG) offer technical specifications used as a basis for technical bestpractices. By combining technical bestpractices with DORA technical specifications, Dynatrace creates technical checks to monitor your organization’s security posture.
This is a potential cause for concern for anyone who cares about metrics like Largest Contentful Paint, which measures the largest visual element on a page – including videos. Review some CSS optimization tips and bestpractices. You can dive deeper into bestpractices for image optimization.)
This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Platform as a service (PaaS) is a development and deployment environment geared toward building and testing cloud-based applications. Increased testing complexity. Limited visibility.
A central element of platform engineering teams is a robust Internal Developer Platform (IDP), which encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications. These phases must be aligned with security bestpractices, as discussed in A Beginner`s Guide to DevOps.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. The ability to scale testing as part of the software development lifecycle (SDLC) has proven difficult.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these bestpractices to innovate at speed without sacrificing quality, reliability, or security. Learn more about DevOps and bestpractices to achieve it at scale.
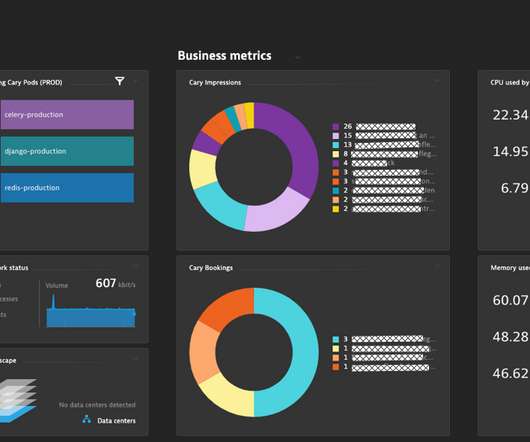
We introduced Digital Business Analytics in part one as a way for our customers to tie business metrics to application performance and user experience, delivering unified insights into how these metrics influence business milestones and KPIs. Technical: production vs. canary release, or A/B testing. Dynatrace news.
These are all metrics Dynatrace collects directly out of the box. All of this data can be bubbled up to a unified dashboard.” Users can then connect this dashboard data with underlying technical data, such as service-level agreement metrics. “This lets you jump right into triage.
Real user monitoring collects data on a variety of metrics. For example, data collected on load actions can include navigation start, request start, and speed index metrics. Real user monitoring works by injecting code into an application to capture metrics while the application is in use. Bestpractices for RUM.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. The Framework is built on five pillars of architectural bestpractices: Cost optimization. Operational excellence. Performance efficiency. Reliability.
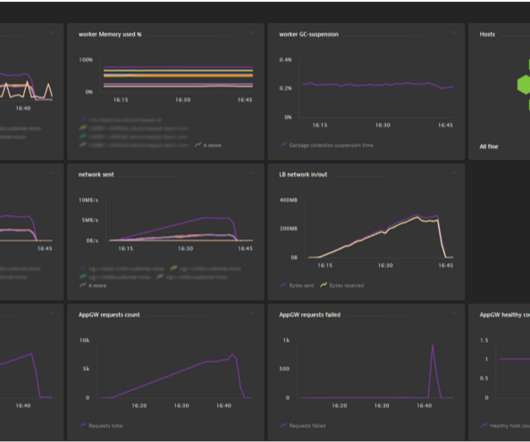
The image below is of a Dynatrace dashboard Stephan created for the CARY team, showing key business metrics as well as infrastructure health metrics in a single place. Relevant infrastructure, operations and business metrics on a single Dynatrace dashboard for CARY. Step 1: Install OneAgent. Step 3: Analyze your data.
As defined by Gartner , service-level objectives are an agreed-upon target within an SLA that must be achieved for each activity, function, and process to provide the best opportunity for customer success. SLIs provide the actual metrics and measurements that indicate whether you are meeting your SLO. SLO bestpractices.
How To Benchmark And Improve Web Vitals With Real User Metrics. How To Benchmark And Improve Web Vitals With Real User Metrics. Different products will have different benchmarks and two apps may perform differently against the same metrics, but still rank quite similarly to our subjective “good” and “bad” verdicts.
One particular use case for Austrian banking software developer Raiffeisen involves using Keptn to automate the production release and readiness validation of all its products using scoring metrics. SREs can then use SLOs for release quality checks, such as big bang, blue/green , and canary testing. There are two configuration options.
While many have been and continue to load test their applications and infrastructure to ensure stability, others are readying their sites for holiday promotions and new offers. Wait, what does this have to do with Dynatrace? For most retail customers, this weekend marks one of the busiest times of the year.
As for HDR, our team is currently developing an HDR extension to VMAF, Netflix’s video quality metric , which will then be used to optimize the HDR streams. ¹ As for VMAF score computation, for encoding resolutions less than 4K, we follow the VMAF bestpractice to upscale to 4K assuming bicubic upsampling.
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. With this objective, the app ensures that users experience real-time feedback and immediate updates when logging workouts, recording sets and reps, or tracking performance metrics.
The challenge with ASP.NET Web Service Observability, Diagnostics and Performance Optimization is that most monitoring & diagnostic tools only provide global Service Level Indicators metrics (SLIs) such as response time, failure rate, and throughput, but not metrics for each individual service endpoint.
Automating tasks throughout the SDLC helps software development and operations teams collaborate while continuously improving how they design, build, test, deploy, release, and monitor software applications. Defect escape rate is the rate of issues and bugs that escape testing and arise after a software application is in production.
Four types of tools are commonly used to detect software vulnerabilities: Source-code tests that are used in development environments. Source code tests. Products that scan source code before the container is built are known as Software Composition Analysis (SCA) tools and Static Application Security Test (SAST) tools.
When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics. With topics ranging from bestpractices to cloud cost management and success stories, the conference will be a valuable resource for understanding observability and getting started.
These teams generally use standardized tools and follow a sequential process to build, review, test, deliver, and deploy code. The architecture is optimized for continuous integration and continuous deployment (CI/CD) — processes that define operating principles, development bestpractices, and rapid delivery of reliable code.
These teams generally use standardized tools and follow a sequential process to build, review, test, deliver, and deploy code. The architecture is optimized for continuous integration and continuous deployment (CI/CD) — processes that define operating principles, development bestpractices, and rapid delivery of reliable code.
This is a set of bestpractices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. If so, test against the response time objective under the same Site Reliability Guardian. If both objectives pass, you have achieved your cost reduction on CPU size.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
Validation tasks are then extended left to cover performance testing and release validation in a pre-production environment. These examples can help you define your starting point for establishing DevOps and SRE bestpractices in your organization. The queries are depicted below (sensitive data has been removed).
That's where a test plan and test strategy can help. If you don't measure quality, you don't have any control over the testing process or any ability to anticipate the results. However, the value and purpose of the quality assurance process are not transparent without documentation.
Given the momentum of DevOps and SRE, digital transformation goals can be achieved when automation enables organizations to apply bestpractices rapidly and to keep pace with the scale of the organization and applications. Additionally, you can easily use any previously defined metrics and SLOs from your environments.
But, manual steps — such as reviewing test results and addressing production issues resulting from performance, resiliency, security, or functional issues — often hinder these efforts. We refer to this culture and practice as observability-driven DevOps and SRE automation. The collected set of metrics are queries for some timeframe.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content