This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Proper setup involves creating a configuration process that accounts for hostname changes, which could prevent nodes from rejoining the cluster. Message load balancing guarantees that messages are processed evenly across different queues and nodes within the RabbitMQ system. Erlang is the backbone of RabbitMQ clustering.
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Observability: Elevating Logs, Metrics, and Traces!
By proactively implementing digital experience monitoring bestpractices and optimizing user experiences , organizations can increase long-term customer satisfaction and loyalty, drive business value , and accelerate innovation. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Proactive cost alerting Proactive cost alerting is the practice of implementing automated systems or processes to monitor financial data, identify potential issues or anomalies, ensure compliance, and alert relevant stakeholders before problems escalate.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools.
Let’s take a closer look at what observability in dynamic AWS environments means, why it’s so important, and some AWS monitoring bestpractices. AWS monitoring bestpractices. These frameworks can include break-points/debuggers and logging instrumentation, or processes, such as manually reading log files.
However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals. By recognizing the insights provided, you can optimize processes and improve overall efficiency.
Customer experience analytics bestpractices As organizations establish or advance their customer experience analytics strategy and tools, the following five bestpractices can help maximize the benefits of these analytics. The data should cover both quantitative metrics (e.g., surveys and reviews).
As a result, site reliability has emerged as a critical success metric for many organizations. By automating and accelerating the service-level objective (SLO) validation process and quickly reacting to regressions in service-level indicators (SLIs), SREs can speed up software delivery and innovation. Service-level objectives (SLOs).
Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. RUM gathers information on a variety of performance metrics. RUM is ideally suited to provide real metrics from real users navigating a site or application. What is real user monitoring?
Dynatrace automatically detects processes and services and will observe their behaviour. A frequent issue, in simple terms, would detect that a machine reaches 100% CPU each time a batch process runs at midnight and won’t alert once it learnt this pattern. It doesn’t apply to infrastructure metrics such as CPU or memory.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. Through Azure Native Dynatrace Service, customers can seamlessly adopt these technologies to modernize and enhance their cloud operations.
Closed-loop remediation is an IT operations process that detects issues or incidents, takes corrective actions, and verifies that the remediation action was successful. How closed-loop remediation works Closed-loop remediation uses a multi-step process that goes beyond simple problem remediation.
They discussed bestpractices, emerging trends, effective mindsets for establishing service-level objectives (SLOs) , and more. These small wins, such as implementing a blameless root cause analysis process, can take many forms and don’t necessarily involve numerical metrics.
Many Dynatrace monitoring environments now include well beyond 10,000 monitored hosts—and the number of processes and services has multiplied to millions of monitored entities. Bestpractice: Filter results with management zones or tag filters. Bestpractice: Increase result set limits by reducing details.
Many of these projects are under constant development by dedicated teams with their own business goals and development bestpractices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. When organizations implement SLOs, they can improve software development processes and application performance. Bestpractices for implementing service-level objectives. SLOs promote automation.
In this article, I take a deeper look into continuous delivery (CD), and describe how this phase of the process is the key to achieving greater efficiency in your software development life cycle. Where continuous delivery fits into the development process. This process of frequent check-ins is called continuous integration (CI).
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Bestpractices to consider. Cloud-server monitoring.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics.
This article strips away the complexities, walking you through bestpractices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. Get ready for actionable insights that balance technical depth with practical advice. This includes servers, applications, software platforms, and websites.
For example, look for vendors that use a secure development lifecycle process to develop software and have achieved certain security standards. Integration with existing processes. This can require process re-engineering to fill gaps and ensuring clear communication and collaboration across security, operations, and development teams.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. SRE applies software engineering principles to operations and infrastructure processes. Learn more about DevOps and bestpractices to achieve it at scale.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
This is a potential cause for concern for anyone who cares about metrics like Largest Contentful Paint, which measures the largest visual element on a page – including videos. Review some CSS optimization tips and bestpractices. You can dive deeper into bestpractices for image optimization.)
By leveraging the power of the Dynatrace ® platform and the new Kubernetes experience, platform engineers are empowered to implement the following bestpractices, thereby enabling their dev teams to deliver best-in-class applications and services to their customers. Monitoring-as-code can also be configured in GitOps fashion.
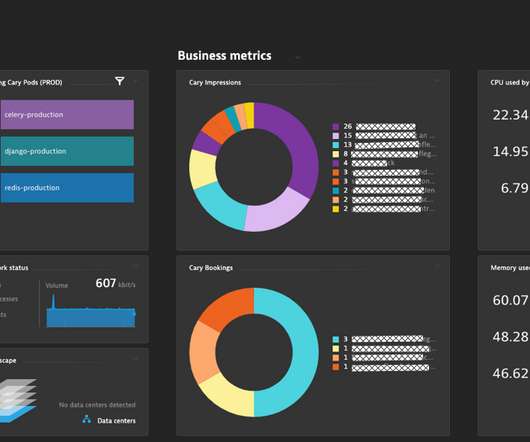
The image below is of a Dynatrace dashboard Stephan created for the CARY team, showing key business metrics as well as infrastructure health metrics in a single place. Relevant infrastructure, operations and business metrics on a single Dynatrace dashboard for CARY. All of this without any Python code modifications.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
And why have SLOs and SLIs become so important as teams automate processes to consistently meet SLAs and error budgets? SLOs are best understood as part of a framework for tracking service levels that also includes service level agreements (SLAs), service-level indicators (SLIs), and error budgets. SLO bestpractices.
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Bestpractices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
In this visual, you can see the whole processing of Keptn deploying, testing, and evaluating performance tests against defined SLIs is automated. Install the Dynatrace OneAgent to gather metrics and feed the Dynatrace AI-powered problem causation engine that automatically shows impacted users, system, and root cause during testing.
However, they can also be used to monitor optimization processes effectively. It’s important to choose the right metrics to track based on your objective. The outlined SLOs serve as a guide for implementing SRE bestpractices in monitoring your Kubernetes environment.
Dynatrace monitors your full stack and offers you thousands of metrics with almost zero configuration. This article we help distinguish between processmetrics, external metrics and PurePaths (traces). What Dynatrace deployment is the best fit for your technology stack, and is the OneAgent compatible with your system?
And while these examples were resolved by just asking a few questions, in many cases, the answers are more elusive, requiring real-time and historical drill-downs into the processes and dependencies specific to each host. Reduce inter-process communications overhead. Implement intelligent retry and failover processes.
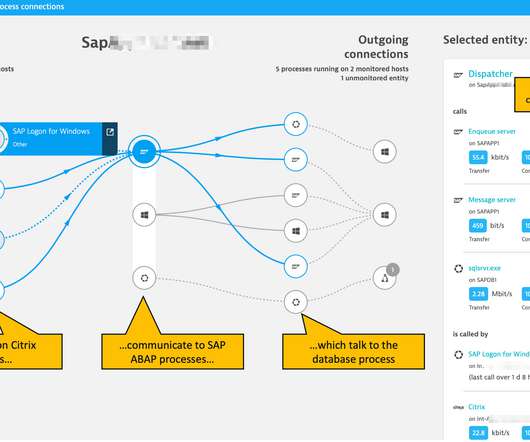
Collected metrics are analyzed in Dynatrace, using the SAP expert community’s established best-practice advice on ABAP platform health indicators, including response time breakdowns of the response times between ABAP-specific application server activities, tasks, and database interaction.
Metrics, logs , and traces make up three vital prongs of modern observability. Together with metrics, three sources of data help IT pros identify the presence and causes of performance problems, user experience issues, and potential security threats. These two processes feed into one another.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. While this connection might sound simple, finding the right metrics to measure the needed SLIs takes time and effort. This article explores SLOs for service performance.
Dynatrace applies these techniques to the broadest set of modalities in the market, including the data types of metrics, traces, logs, behavior, topology, dependencies, events, and more, with unmatched precision for precise predictions, accurate determinations, and meaningful insights.
Tracking changes to automated processes, including auditing impacts to the system, and reverting to the previous environment states seamlessly. Allowing architectures to be nimble and evolve over time, allowing organizations to take advantage of innovations as a standard practice. Fully conceptualizing capacity requirements.
However, many teams struggle with knowing which ones to use and how to incorporate them into the processes. Below, several Dynatrace customers shared their SLO management journey and discussed the resulting dashboards they rely on daily to manage their mission-critical business processes and applications. What are SLOs?
More recently, teams have begun to apply DevOps bestpractices to infrastructure automation, giving developers a more active role with GitOps as an operational framework. But setting up the required tooling requires in-depth knowledge and causes massive effort if done manually. Dynatrace enables software intelligence as code.
These are all metrics Dynatrace collects directly out of the box. All of this data can be bubbled up to a unified dashboard.” Users can then connect this dashboard data with underlying technical data, such as service-level agreement metrics. We can connect the root cause to the process owner.”
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content