This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metrics and Statistics Monitoring the performance of a RabbitMQ cluster is crucial for maintaining its efficiency and reliability. RabbitMQ provides a wealth of metrics and statistics that offer insights into various aspects of the clusters performance. Addressing these issues will help ensure robust performance and reliability. <p>The
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Observability: Elevating Logs, Metrics, and Traces! What is Fluent Bit?
By proactively implementing digital experience monitoring bestpractices and optimizing user experiences , organizations can increase long-term customer satisfaction and loyalty, drive business value , and accelerate innovation. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
As a MISA member, we look forward to collaborating with Microsoft and other members to develop bestpractices, share insights, and drive innovation in cloud-native security. They can automatically identify vulnerabilities, measure risks, and leverage advanced analytics and automation to mitigate issues.
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Proactive cost alerting Proactive cost alerting is the practice of implementing automated systems or processes to monitor financial data, identify potential issues or anomalies, ensure compliance, and alert relevant stakeholders before problems escalate. Dynatrace can help you achieve your FinOps strategy using observability bestpractices.
Let’s take a closer look at what observability in dynamic AWS environments means, why it’s so important, and some AWS monitoring bestpractices. AWS monitoring bestpractices. Here are some bestpractices for maintaining AWS observability in larger, multicloud environments. And why it matters.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools.
Customer experience analytics bestpractices As organizations establish or advance their customer experience analytics strategy and tools, the following five bestpractices can help maximize the benefits of these analytics. The data should cover both quantitative metrics (e.g., surveys and reviews).
As a result, site reliability has emerged as a critical success metric for many organizations. Aligning site reliability goals with business objectives Because of this, SRE bestpractices align objectives with business outcomes. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
To calculate the service-level indicator for the Kubernetes namespace memory efficiency SLO, simply query the memory working set and request the memory metrics that are provided out of the box. The outlined SLOs for Kubernetes clusters guide you in implementing SRE bestpractices in monitoring your Kubernetes environment.
It doesn’t apply to infrastructure metrics such as CPU or memory. When using the default automatic settings, Dynatrace uses industry-standard best practise hardcoded values. The post Bestpractices for alerting appeared first on Dynatrace blog. There is another important thing to know. That’s another big cultural change!
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Real user monitoring limitations.
IT teams have traditionally relied on internal metrics to estimate business impact. More important is how these metrics impact business outcomes: progression through a funnel, conversion rates and value, fulfillment SLOs, and even net promoter scores (NPS). Observability that extends into business metrics.
It is also a key metric for organizations looking to improve their DevOps performance. This metric represents the proportion of system incidents resolved by escalating to a higher level of support. It is bestpractice to trigger actions to notification tools that indicate the success or failure of the remediation action.
With Dynatrace, customers can utilize the full set of Azure capabilities, including metrics and data from the Azure platform, and automatically identify workflow optimization opportunities. We hope to see you there! The post Microsoft Ignite 2024 guide: Cloud observability for AI transformation appeared first on Dynatrace news.
They discussed bestpractices, emerging trends, effective mindsets for establishing service-level objectives (SLOs) , and more. These small wins, such as implementing a blameless root cause analysis process, can take many forms and don’t necessarily involve numerical metrics. Download now!
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
This blog post introduces the new REST API improvements and some bestpractices for streamlining API requests and decreasing load on the API by reducing the number of requests required for reporting and reducing the network bandwidth required for implementing common API use cases.
Many of these projects are under constant development by dedicated teams with their own business goals and development bestpractices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives.
Here are a few common metrics teams should track for every CD pipeline to help you evaluate its efficacy. Bestpractices for adopting continuous delivery. Building a fast and reliable release process requires implementing quality checks, logging practices, and monitoring solutions. Develop Service Level Objectives (SLOs).
This article strips away the complexities, walking you through bestpractices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. Get ready for actionable insights that balance technical depth with practical advice. </p>
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). By tracking these metrics, we can identify any unusual spikes or drops in network activity, which might indicate performance issues or bottlenecks.
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. This type of monitoring tracks metrics and insights on server CPU, memory, and network health, as well as hosts, containers, and serverless functions. Bestpractices to consider.
For Carbon Impact, these business events come from an automation workflow that translates host utilization metrics into energy consumption in watt hours (Wh) and into greenhouse gas emissions in carbon dioxide equivalent (CO2e). In other words, APM bestpractices are close to Green Coding bestpractices.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
Before we get into the specifics, let’s first recap the benefits OpenTelemetry offers and why using collectors is a bestpractice. Understanding OpenTelemetry OpenTelemetry is an open, vendor-neutral standard for creating, collecting, and transferring telemetry data, like traces, metrics, and logs.
In Dynatrace, tagging also allows you to control access rights (via Management Zones), filter data on dashboards or via the API as well as allowing you to control calculation of custom service metrics or extraction of request attributes. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
While DORA provides high-level definitions, other regulatory frameworks (such as CIS or DISA-STIG) offer technical specifications used as a basis for technical bestpractices. By combining technical bestpractices with DORA technical specifications, Dynatrace creates technical checks to monitor your organization’s security posture.
By leveraging the power of the Dynatrace ® platform and the new Kubernetes experience, platform engineers are empowered to implement the following bestpractices, thereby enabling their dev teams to deliver best-in-class applications and services to their customers. Monitoring-as-code can also be configured in GitOps fashion.
However, such observation periods come with a disadvantage: incidents can pile up and there is a delay between those incidents and the corresponding health metrics ultimately dropping low enough to trigger a warning. Most monitoring tools offer only a single SLO metric. Get up and running in under a minute with SLO templates.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these bestpractices to innovate at speed without sacrificing quality, reliability, or security. Learn more about DevOps and bestpractices to achieve it at scale.
How To Benchmark And Improve Web Vitals With Real User Metrics. How To Benchmark And Improve Web Vitals With Real User Metrics. Different products will have different benchmarks and two apps may perform differently against the same metrics, but still rank quite similarly to our subjective “good” and “bad” verdicts.
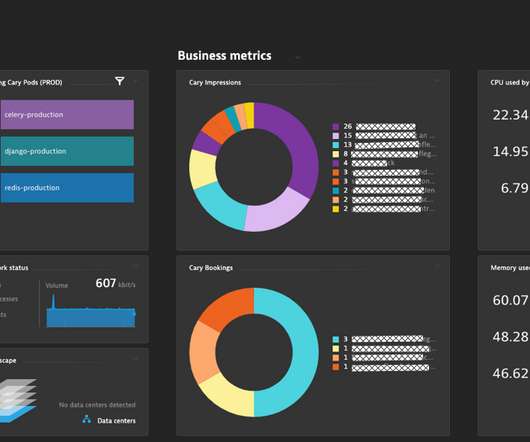
The image below is of a Dynatrace dashboard Stephan created for the CARY team, showing key business metrics as well as infrastructure health metrics in a single place. Relevant infrastructure, operations and business metrics on a single Dynatrace dashboard for CARY. All of this without any Python code modifications.
Cumulative Layout Shift … Continue reading Cumulative Layout Shift, The Layout Instability Metric → This happens to me a lot, mostly because of ads loading around the content I’m reading.This kind of user experience can be frustrating, but until now we’ve had trouble measuring it quantitatively.
My goal is always to deliver tangible bestpractices that can be implemented today, and that can help teams transform their organization to true software-centric, digital cloud-native businesses. We’ll cover Request Attributes , calculated Service Metrics , and using Dynatrace Events API to deliver notifications on test cycles.
Install the Dynatrace OneAgent to gather metrics and feed the Dynatrace AI-powered problem causation engine that automatically shows impacted users, system, and root cause during testing. A look at Panera Bread’s role and responsibilities for the app dev team and performance engineering. Here is a shortlist to get you started.
Receive alerts for any metric event in your Azure Automation account. The Dynatrace Software Intelligence Platform provides a simple one-click setup and integration for ingestion of metrics from Azure Monitor, which facilitates data consolidation. Receive alerts for any metric event in your Azure Automation account.
Applying Service Level Objectives (SLO) to track these indicators is a common bestpractice within site reliability engineering. Still, an SLO’s quality lies in the significance of the underlying service-level indicator.
Dynatrace applies these techniques to the broadest set of modalities in the market, including the data types of metrics, traces, logs, behavior, topology, dependencies, events, and more, with unmatched precision for precise predictions, accurate determinations, and meaningful insights.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content