This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Aligning site reliability goals with business objectives Because of this, SRE bestpractices align objectives with business outcomes. At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
RUM, however, has some limitations, including the following: RUM requires traffic to be useful. RUM works best only when people actively visit the application, website, or services. Because RUM relies on user-generated traffic, it’s hard to indicate persistent issues across the board. Real user monitoring limitations.
In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives. Latency is the time that it takes a request to be served. So how can teams start implementing SLOs? Reliability.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
While DORA provides high-level definitions, other regulatory frameworks (such as CIS or DISA-STIG) offer technical specifications used as a basis for technical bestpractices. By combining technical bestpractices with DORA technical specifications, Dynatrace creates technical checks to monitor your organization’s security posture.
These examples can help you define your starting point for establishing DevOps and SRE bestpractices in your organization. While the first guardian validates the traffic, the second guardian checks the business transactions generated during the observation period. The functionality is implemented via an automated workflow.
This is where Site Reliability Engineering (SRE) practices are applied. SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems.
We’ll answer that question and explore cloud migration benefits and bestpractices for how to go through your migration smoothly. In case of a spike in traffic, you can automatically spin up more resources, often in a matter of seconds. Likewise, you can scale down when your application experiences decreased traffic.
In their new dashboard, they added dimensions for load, latency, and open problems for each component. To ensure their global service levels, they fully embraced the bestpractices outlined in Google’s SRE handbook , called the “Four Golden Signals,” to standardize what they show on their SRE dashboards.
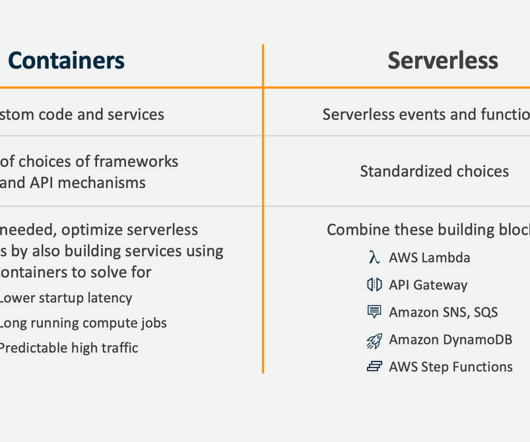
For example, to handle traffic spikes and pay only for what they use. Scale automatically based on the demand and traffic patterns. Higher latency and cold start issues due to the initialization time of the functions. The elasticity of serverless services helps organizations scale as needed.
Configuration as Code supports all the mechanisms and bestpractices of Git-based workflows, including pull requests, commit merging, and reviewer approval. GitOps is a best-practice methodology for handling operation-relevant configurations that can be applied across the entire Dynatrace platform.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. can we actually make this work in practice? Since MIPs are NP-hard, some care needs to be taken.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
Then they tried to scale it to cope with high traffic and discovered that some of the state transitions in their step functions were too frequent, and they had some overly chatty calls between AWS lambda functions and S3. They state in the blog that this was quick to build, which is the point.
Azure and found that DigitalOcean performance was in line with, if not better, on both high throughput and low latency in the deployment. While adequate for low-traffic applications, small databases, and dev/test environments, we recommend against leveraging shared clusters for your MongoDB production deployments.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously.
They utilize a routing key mechanism that ensures precise navigation paths for message traffic. RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. Within RabbitMQ’s ecosystem, bindings function as connectors between exchanges and queues.
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. Overall, adopting this practice promotes a structured and efficient storage strategy, fostering better performance, manageability, and, ultimately, a more robust database environment.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. With 100s of real-life examples , guidelines and bestpractices that you can apply right away. Ilya Grigorik. More after jump!
Number of slow queries recorded Select types, sorts, locks, and total questions against a database Command counters and handlers used by queries give an overall traffic summary Along with this, PMM also comes with Query Analytics giving much detailed information about queries getting executed.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. Similarly, an increased throughput signifies an intensive workload on a server and a larger latency.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. The CFQ works well for many general use cases but lacks latency guarantees.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously.
That’s why it’s essential to implement the bestpractices and strategies for MongoDB database backups. Bestpractice tip : It is always advisable to use secondary servers for backups to avoid unnecessary performance degradation on the PRIMARY node. Bestpractice tip : Use PBM to time huge backup sets.
Just because everything works perfectly during production testing doesn’t mean that will be the case when your website is flooded with traffic. Bottlenecks can occur, for example, if you have a sudden surge in traffic that your servers are not equipped to handle. What Are the Benefits of Performance Testing?
Kubernetes can be complex, which is why we offer comprehensive training that equips you and your team with the expertise and skills to manage database configurations, implement industry bestpractices, and carry out efficient backup and recovery procedures.
As defined by the Google SRE initiative, the four golden signals of monitoring include the following metrics: Latency. Latency is the amount of time, or delay, a service takes to respond to a request. Traffic refers to the amount of user demand, or load, is on the system. Monitoring can provide a way to differentiate between.
The fundamental principles at play include evenly distributing the workload among servers for better application performance and redirecting client requests to nearby servers to reduce latency. This includes zero-day vulnerabilities and software weaknesses that are not yet known and can be exploited without warning.
As illustrated above, ProxySQL allows us to set up a common entry point for the application and then redirect the traffic on the base of identified sharding keys. It will also allow us to redirect read/write traffic to the primary and read-only traffic to all secondaries. I will eventually increase them if I see the need.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side.
It increases our visibility and enables us to draw a steady stream of organic (or “free”) traffic to our site. While paid marketing strategies like Google Ads play a part in our approach as well, enhancing our organic traffic remains a major priority. The higher our organic traffic, the more profitable we become as a company.
Rather than buying racks and racks of servers that need to handle the maximum potential traffic and be idle most of the time, it seems that serverless’ method of paying by compute is proving to be beneficial to the bottom lines of organizations. latency, startup, mocking, etc.) Reduction of operational costs” was the No.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. We will discuss these features in more depth later in this article.
You would, however, be hard-pressed even today to find a good article that details the nuanced bestpractices. This is because, as I stated in the introduction to part 1 , much of the early HTTP/2 content was overly optimistic about how well it would work in practice, and some of it, quite frankly, had major mistakes and bad advice.
The stakes are even higher during high-traffic periods such as Black Friday or Cyber Monday. The impact of outages can be reduced by dispersing traffic across numerous CDNs, resulting in a more smooth user experience.Adopting an Active-Active policy is a critical component of a successful Multi-CDN approach.
The stakes are even higher during high-traffic periods such as Black Friday or Cyber Monday. The impact of outages can be reduced by dispersing traffic across numerous CDNs, resulting in a more smooth user experience.Adopting an Active-Active policy is a critical component of a successful Multi-CDN approach.
Testing helps in finding latency time of an application: Users prefer to use mobile phones over desktop when they are looking for any query, booking flight/movie ticket. Thus, a responsive mobile view of the website will help you rank higher in the search engines and divert more traffic to grow your business.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side.
This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. To maximize indexing benefits, be sure to follow bestpractices. This does not apply to read (SELECT) traffic. To tune these values, it is best to know how many iops your system can perform.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side.
Existing data got updated to be backward compatible without impacting the existing running production traffic. Data Sharding strategy in elasticsearch is updated to provide low search latency (as described in blog post) Design of new Cassandra reverse indices to support different sets of queries.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content