This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While clustering across wide-area networks (WANs) is discouraged due to latency issues, leased links can mitigate some connectivity challenges. Keeping queues short minimizes latency and enhances the overall efficiency of message delivery in RabbitMQ. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
95th Percentile Latency. The 95th percentile latency of queries was also 1.8 The 95th percentile latency of queries was also 1.8 BestPractice for Creating Indexes on your #MySQL Tables Click To Tweet. Workload Throughput (Queries Per Second). Index Creation on Master. Rolling Index Creation.
By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical. Load time and network latency metrics. The following includes bestpractices for optimizing mobile app performance. Performance optimization.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Aligning site reliability goals with business objectives Because of this, SRE bestpractices align objectives with business outcomes. At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems.
Though we are not worried about computing resources, the latency becomes an overhead. With the increase in the size of data, we have activities like serializing, deserializing, and transportation costs added to it. We need to cut down on transportation. A lot of messaging protocols have been developed in the past to address this.
connectivity, access, user count, latency) of geographic regions. The post Real user monitoring vs. synthetic monitoring: Understanding bestpractices appeared first on Dynatrace blog. Geofencing and geographic reachability testing for areas that are more challenging to access. Synthetic monitoring drawbacks.
In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives. Latency is the time that it takes a request to be served. So how can teams start implementing SLOs? Reliability.
The post will provide a comprehensive guide to understanding the key principles and bestpractices for optimizing the performance of APIs. It involves a combination of techniques and bestpractices aimed at reducing latency, improving user experience, and increasing the overall efficiency of the system.
Our new eBook, “ From Planning to Performance: MongoDB Upgrade BestPractices ,” guides you through the entire process to ensure your database’s long-term success. Improved performance : MongoDB continually fine-tunes its database engine, resulting in faster query execution and reduced latency.
Traces are used for performance analysis, latency optimization, and root cause analysis. It evolves continuously through contributions from a vibrant community and support from major tech companies, which ensures that it stays aligned with the latest industry standards, technological advancements, and bestpractices.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
This is where Site Reliability Engineering (SRE) practices are applied. SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems.
In their new dashboard, they added dimensions for load, latency, and open problems for each component. To ensure their global service levels, they fully embraced the bestpractices outlined in Google’s SRE handbook , called the “Four Golden Signals,” to standardize what they show on their SRE dashboards.
Providing insight into the service latency to help developers identify poorly performing code. Bestpractices for RUM. To leverage the greatest benefits of real user monitoring, keep in mind several bestpractices. Want to learn more? This is one area where synthetic monitoring can help to fill the gaps.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Solving for SR.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. can we actually make this work in practice? Since MIPs are NP-hard, some care needs to be taken.
Then, they can apply DevSecOps bestpractices to fully test new code and see what breaks without affecting current operations. Reduced latency. By using cloud providers with multiple server sites, organizations can reduce function latency for end users. Optimizes resources.
These examples can help you define your starting point for establishing DevOps and SRE bestpractices in your organization. In this case, the four golden signals (latency, traffic, errors, and saturation) are derived from span attributes and DQL metric queries via Dynatrace Grail™.
Configuration as Code supports all the mechanisms and bestpractices of Git-based workflows, including pull requests, commit merging, and reviewer approval. GitOps is a best-practice methodology for handling operation-relevant configurations that can be applied across the entire Dynatrace platform.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Solving for SR.
Reduced latency. If you haven’t implemented either, a bestpractice to get started is to develop a strategy that incorporates both DevOps and SRE practices. SRE’s purpose, on the other hand, is to apply DevOps principles to enhance operational processes specifically: Availability. Efficiency.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these bestpractices to innovate at speed without sacrificing quality, reliability, or security. Learn more about DevOps and bestpractices to achieve it at scale.
This is a set of bestpractices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. If you use AWS cloud services to build and run your applications, you may be familiar with the AWS Well-Architected framework.
Because AI observability monitors resource utilization during all phases of AI operations—from model training and inference to tracking model performance—it enables organizations to best balance between accuracy and resource efficiency and to optimize operational costs. Use containerization.
We’ll answer that question and explore cloud migration benefits and bestpractices for how to go through your migration smoothly. This can dramatically decrease network latency and its effect on the end-user experience. Bestpractices for a successful cloud migration. What is cloud migration?
By having appropriate indexes on your MySQL tables, you can greatly enhance the performance of SELECT queries. But, did you know that adding indexes to your tables in itself is an expensive operation, and may take a long time to complete depending on the size of your tables?
With topics ranging from bestpractices to cloud cost management and success stories, the conference will be a valuable resource for understanding observability and getting started. Dynatrace enables teams to specify SLOs, such as latency, uptime, availability, and more. KubeCon North America is this week.
Before writing a OneAgent plugin, it’s always bestpractice to check that the metric(s) you want to add are not already in Dynatrace. With insights from Dynatrace into network latency and utilization of your cloud resources, you can design your scaling mechanisms and save on costly CPU hours.
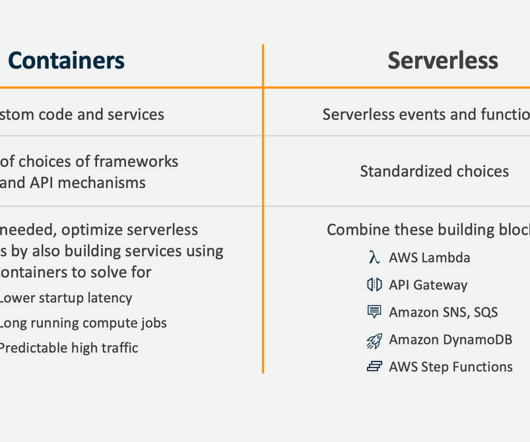
Higher latency and cold start issues due to the initialization time of the functions. Enable faster development and deployment cycles by abstracting away the infrastructure complexity. More complex dependencies and interactions among different services and components. Less visibility into the internal state and behavior of the functions.
This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. As workloads shift to public, private, and hybrid cloud environments, CloudOps teams help IT and DevOps manage increasing complexity by defining and managing bestpractices for cloud-based operations. Performance. ITOps vs. AIOps.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. But to get the best performance, like any technology stack, you need to follow the bestpractices. Alluxio is leveraged as compute-side virtual storage to improve performance.
You can set SLOs based on individual indicators, such as batch throughput, request latency, and failures-per-second. SLO bestpractices. Here are some bestpractices to help you achieve the goals set out in your SLOs: Less is more. These trends also help you adjust business objectives and SLAs.
I don’t advocate “Serverless Only”, and I recommended that if you need sustained high traffic, low latency and higher efficiency, then you should re-implement your rapid prototype as a continuously running autoscaled container, as part of a larger serverless event driven architecture, which is what they did.
service availability with <50ms latency for an application with no revenue impact. Commonly, teams create SLOs because they are simply following what others in the industry are doing, or because they are common bestpractices. This can create an unnecessary distraction and steal time away from critical tasks.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. The CFQ works well for many general use cases but lacks latency guarantees.
Data Sharding strategy in elasticsearch is updated to provide low search latency (as described in blog post) Design of new Cassandra reverse indices to support different sets of queries. BestPractices Depending on existing data size and use case, processing may impact the production flow.
That’s why it’s essential to implement the bestpractices and strategies for MongoDB database backups. Bestpractice tip : It is always advisable to use secondary servers for backups to avoid unnecessary performance degradation on the PRIMARY node. Bestpractice tip : Use PBM to time huge backup sets.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. Similarly, an increased throughput signifies an intensive workload on a server and a larger latency.
RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. By prioritizing such messages, RabbitMQ delivers notifications with minimal latency, thus improving the user experience while sustaining the efficacy of communication systems.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. With 100s of real-life examples , guidelines and bestpractices that you can apply right away. Ilya Grigorik. More after jump!
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content