This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring bestpractices. Amazon EC2. AWS Lambda.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools.
The methodology and algorithms were designed by Dynatrace with guidance from the Sustainable Digital Infrastructure Alliance (SDIA), expanding on formulas from the open source project Cloud Carbon Footprint. These optimizations might sound similar if you’re acquainted with Application Performance Management (APM) bestpractices.
Protecting IT infrastructure, applications, and data requires that you understand security weaknesses attackers can exploit. Host analysis focuses on operating systems, virtual machines, and containers to understand if there are software components with known vulnerabilities that can be patched. Dynatrace news.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). Query your data with natural language Davis CoPilot is an excellent virtual assistant that helps you create queries using natural language. Looking for something?
Cloud environments are vast and constantly evolving, making manual identification of misconfigurations virtually impossible. Addressing these challenges proactively is critical to maintaining a secure and efficient cloud infrastructure. This delay in discovery significantly increases a business’s risk exposure.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. ITOps is an IT discipline involving actions and decisions made by the operations team responsible for an organization’s IT infrastructure. ITOps vs. AIOps.
Today, DevOps orchestration is necessary to gain a comprehensive view and means of control over infrastructure, services, and software development practices. DevOps orchestration in practice. Automation refers to creating machine-executable processes to perform a task, such as deploying a virtual machine or performing a backup.
Getting precise root cause analysis when dealing with several layers of virtualization in a containerized world. The Framework is built on five pillars of architectural bestpractices: Cost optimization. Figure 2 – Host VM Utilization dashboard to assess for Capacity and Infrastructure Cost Optimization management.
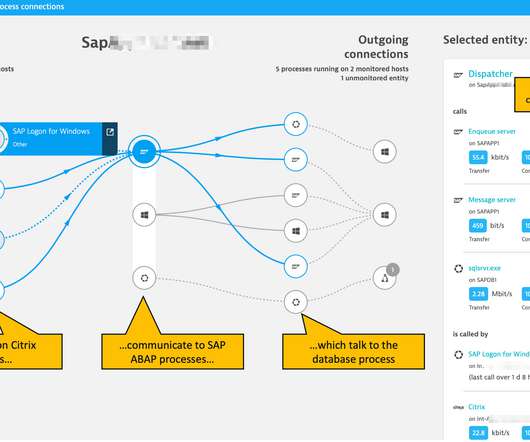
This extends Dynatrace visibility into SAP ABAP performance from the infrastructure and ABAP application platform perspective. The SAP Basis team needs a comprehensive picture of infrastructure performance and dependencies that determine their SAP system’s performance. Why SAP ABAP platform monitoring in Dynatrace?
It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Fitness app : The fitness app should support a concurrent user count of 10,000 during virtual fitness events or live-streaming sessions.
Nevertheless, there are related components and processes, for example, virtualizationinfrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. You haven’t detected that there’s a shortage of disk space on the virtualization host (or its shared storage).
Dynatrace support for AWS Data Firehose includes AWS Lambda logs, Amazon Virtual Private Cloud (VPC) flow logs, Amazon S3 logs, and Amazon CloudWatch. Applying Service Level Objectives (SLO) to track these indicators is a common bestpractice within site reliability engineering. GitHub : Integrate with your GitHub repositories.
And we know as well as anyone: the need for fast transformations drives amazing flexibility and innovation, which is why we took Perform Hands-on Training (HOT) virtual for 2021. Here’s what’s new this year, and how you can get a front-row seat in our virtual classroom. More flexibility, more options. The Dynatrace University Team.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. What is site reliability engineering? Solving for SR.
We’re proud to announce the Early Access Program (EAP) for monitoring of SAP ABAP performance from the infrastructure and ABAP application platform perspective. The SAP Basis team needs a comprehensive picture of infrastructure performance and dependencies that determine their SAP system’s performance. Dynatrace news.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. A major goal of SRE is to reduce duplication or redundancy of effort as much as possible. Solving for SR.
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead.
Real-time monitoring Application security monitoring often includes real-time monitoring of the application’s infrastructure, network traffic, and user activities for any signs of intrusion or suspicious behavior. What are application security monitoring bestpractices?
Before writing a OneAgent plugin, it’s always bestpractice to check that the metric(s) you want to add are not already in Dynatrace. Virtualization can be a key player in your process’ performance, and Dynatrace has built-in integrations to bring metrics about the Cloud Infrastructure into your Dynatrace environment.
Microservices development is intrinsically optimized for continuous integration/continuous deployment ( CI/CD ) processes that apply agile development bestpractices for the rapid delivery of reliable code. For example, a virtual machine (VM) can replace containers to design and architect microservices. Service mesh.
Virtually any application with a user interface can benefit from regular real user monitoring. Bestpractices for RUM. To leverage the greatest benefits of real user monitoring, keep in mind several bestpractices. Examples of real user monitoring. Establish business objectives for how you use RUM. Learn more!
Let me walk you through how I have built my Dynatrace Performance Insights Dashboard showing SLIs split by Test Name as well as SLIs for the specific technology and infrastructure: Enriching your load testing scripts with meta data allows building test context specific SLI-dashboards in Dynatrace.
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. Bestpractices for container security. Here is a checklist of bestpractices for how to approach container security. Pretty neat, isn’t it?
It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Fitness app : The fitness app should support a concurrent user count of 10,000 during virtual fitness events or live-streaming sessions.
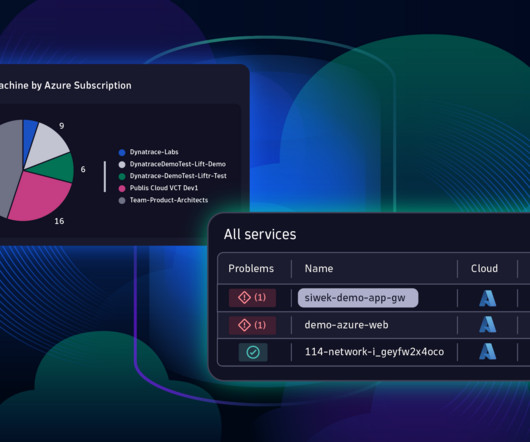
There’s no need for configuration or setup of any infrastructure. Integrate multiple Azure subscriptions under a single Dynatrace environment If you have multiple Azure subscriptions in your Azure tenant, it’s bestpractice to integrate the Azure subscriptions with a single Dynatrace environment.
We’re currently in a technological era where we have a large variety of computing endpoints at our disposal like containers, Platform as a Service (PaaS), serverless, virtual machines, APIs, etc. And, this is even more apparent due to the ever-increasing infrastructure complexity enterprises are dealing with.
Although we can tweak the number of tickets available in WiredTiger, there is a virtual limit – which means that changing the available tickets might generate processor overload instead of increasing performance. 6) Infrastructure limitations Infrastructure and hardware limitations are very similar.
This approach was presented virtually in the on-demand observability clinic, Getting Started with Observability-Driven DevOps and SRE Automation. With visibility into releases, the next step is to define SLOs with app, infrastructure, and business owners. Check out the full webinar here! Gain visibility into your existing releases.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. This applies to both virtual machines and container-based deployments. Hybrid cloud environments that integrate on-premises infrastructure with cloud services.
When using a single CDN, the organization is dependent on the CDN provider’s geographical coverage and server infrastructure. This coverage may not align with the organization's needs at all times.Distributing content across multiple CDNs allows switching to the CDN with the best coverage and lowest latency for each user at any given time.
Authorization and Access Control In RabbitMQ, authorization dictates the operations a user may execute on given virtual hosts. Virtual Hosts and Resource Permissions In RabbitMQ, virtual hosts craft distinct isolated environments that upgrade security and resource segregation by restricting inter-vhost communication.
Platform engineering improves developer productivity by providing self-service capabilities with automated infrastructure operations. Join us at Dynatrace Perform 2024 , either on-site or virtuall y, to explore these themes further. In what follows, we explore these key cloud observability trends in 2024. What is platform engineering?
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. Without further ado, let’s start with the OS settings.
As such, fault tolerance is more expensive to implement because it requires dedicated infrastructure that completely mirrors the primary system. Components of high availability infrastructure Multiple copies of data Data redundancy helps prevent data loss due to hardware or software failures.
When using a single CDN, the organization is dependent on the CDN provider’s geographical coverage and server infrastructure. This coverage may not align with the organization's needs at all times.Distributing content across multiple CDNs allows switching to the CDN with the best coverage and lowest latency for each user at any given time.
and package them in a design (blueprint) of a database infrastructure that’s fit to perform optimally — amid demanding conditions. That design will depict an infrastructure of high availability nodes/clusters that work together (or separately, if necessary) so that if one goes down, another one takes over.
As cloud-based frameworks require no expertise, installation time or effort and do not depend on a robust internal infrastructure, your tests can be up and running in just a matter of a few minutes. With SaaS, you don’t need to invest in internal infrastructure. BestPractices for Controlling Cloud Access in Your Organization.
Designed with simplicity and scalability in mind, ACI allows developers and IT professionals to swiftly deploy containers without the complexity of managing virtual machines or higher-level services like Kubernetes.
HA in PostgreSQL databases delivers virtually continuous availability, fault tolerance, and disaster recovery. No single point of failure (SPOF): If the failure of a database infrastructure component could cause downtime, that component is considered an SPOF. It can be done by building the HA infrastructure within a single data center.
We must make our software infrastructure more secure against the rise in cyberattacks (such as on power grids, hospitals, and banks), and safer against accidental failures with the increased use of software in life-critical systems (such as autonomous vehicles and autonomous weapons). Terminology (see ISO/IEC 23643:2020 ). Let’s dig in.
Here are the three big directional bets that align with the three main areas cited by the authors: We will train in the cloud , where its possible to take advantage of managed infrastructure well suited to large amounts of data, spiky resource usage, and access to the latest hardware. It was a surprise to me too when that penny dropped.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content