This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Proactive cost alerting Proactive cost alerting is the practice of implementing automated systems or processes to monitor financial data, identify potential issues or anomalies, ensure compliance, and alert relevant stakeholders before problems escalate. This awareness is important when the goal is to drive cost-conscious engineering.
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
By automating and accelerating the service-level objective (SLO) validation process and quickly reacting to regressions in service-level indicators (SLIs), SREs can speed up software delivery and innovation. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity.
Google has released a new book: The Site Reliability Workbook — Practical Ways to Implement SRE. David Rensin, a SRE at Google, says : It's a whole new book. It's designed to sit next to the original on the bookshelf and for folks to bounce between them -- moving between principle and practice. Simplicity.
Here’s why: Complex configuration management 30% of all cloud environment attacks during the first half of 2024 used misconfigurations as the initial access vector” – Google Cloud Threat Horizons report. Addressing these challenges proactively is critical to maintaining a secure and efficient cloud infrastructure.
When organizations implement SLOs, they can improve software development processes and application performance. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. Bestpractices for implementing service-level objectives.
Review some CSS optimization tips and bestpractices. Core Web Vitals are a Google search ranking factor. Given that Google continues to dominate search usage, you should care about Vitals alongside the other metrics you should be tracking. You can dive deeper into bestpractices for image optimization.)
Perform serves yearly as the marquis Dynatrace event to unveil new announcements, learn about new uses and bestpractices, and meet with peers and partners alike. What can we move? What will the new architecture be? How can we ensure we see performance gains once migrated?
DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. Both practices live by the same overarching tenets. Teams can get entrenched and siloed in familiar manual processes and piecemeal solutions as they roll out new applications. DevOps as a philosophy. SRE vs DevOps?
Among his insights, Dr. Magill offers the following four bestpractices that organizations can keep in mind to better secure their organizations: Scan dependencies. First, set up a process to capture, report, and act on results following regular dependency scans. Choose projects carefully. Stay up to date.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. A few bestpractices.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. A few bestpractices.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
These functions are executed by a serverless platform or provider (such as AWS Lambda, Azure Functions or Google Cloud Functions) that manages the underlying infrastructure, scaling and billing. Data analysis : how to process, aggregate and query observability data from serverless functions effectively, accurately, and comprehensively?
This is a set of bestpractices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business?
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. SRE applies software engineering principles to operations and infrastructure processes. Learn more about DevOps and bestpractices to achieve it at scale.
However, many teams struggle with knowing which ones to use and how to incorporate them into the processes. Below, several Dynatrace customers shared their SLO management journey and discussed the resulting dashboards they rely on daily to manage their mission-critical business processes and applications. What are SLOs?
Keptn: A reference implementation of Google’s SRE principles. Software engineer Taras Tsugrii of Meta (formerly Facebook) paid Keptn a high compliment, saying it feels like a reference implementation of Google’s SRE principles , which are the search giant’s techniques for ensuring the integrity of its sites and services.
However, because organizations typically use multiple mobile monitoring tools, this process is often far more difficult than it should be. App developers and digital teams typically rely on separate analytics tools, such as Adobe and Google Analytics, that may aggregate user behavior and try to understand anomalies in traffic.
Bestpractices for optimizing images They say a picture is worth a thousand words. Here's a detailed checklist of bestpractices and how-tos to make sure your beautiful images aren't hurting your page speed. According to Google, a 'good' INP time is faster that 200 milliseconds. Find out here. Looking ahead.
In fact, giants like Google and Microsoft once employed monolithic architectures almost exclusively. These teams typically use standardized tools and follow a sequential process to build, review, test, deliver, and deploy code. With monolithic architecture, components all coexist in a single deployment. Serverless platforms.
Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This ensures that customers can quickly navigate through product listings, add items to their cart, and complete the checkout process without experiencing noticeable delays. or above for the checkout process.
Google Cloud Distinguished Engineer Kelsey Hightower hopes to solve the many problems facing IT culture by equipping people with the mental and computational software they need to succeed in the competitive world of technology. Hightower shared his beliefs on operational bestpractices. This is an impossible task.”
A broken SLO with no owner can take longer to remediate and is more likely to recur compared to an SLO with an owner and a well-defined remediation process. Establish the relevant service level indicators (SLIs) that need to be monitored, the process for remediating any issues, the relevant tools required, and timeframes for resolution.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions.
The Recovery Point Objective (RPO) is the duration of time and service level within which a business process must be stored after a disaster in order to avoid unacceptable consequences associated with a break in continuity. This is good as well to validate that the replication process has no errors.
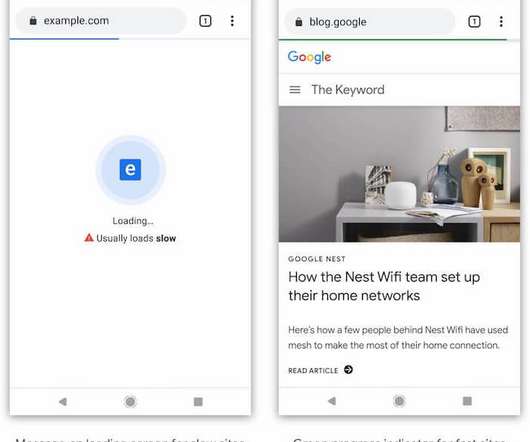
Google has announced plans for a new badging system that would let users know whether a website typically loads slowly. In a post detailing the thought process behind the planned feature, the Chrome team explains that “In the future, Chrome may identify sites that typically load fast or slow for users with clear badging ”.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. DevOps bestpractices include testing within the CI/CD pipeline, also known as shift-left testing.
Additionally, include benchmarks for stakeholders and bestpractices that support the anticipated growth of the organization as a whole. Public, private, and hybrid cloud computing platforms such as Microsoft Azure and Google Cloud provide access, development, and management of cloud applications and services.
In the free ebook “ A Beginner’s Guide to DevOps ,” DevOps is defined as a set of software development and delivery bestpractices to close the gap between software development and IT operations. As a result, developers can address operational concerns earlier in the software delivery process and streamline efforts.
This is an amazing movement providing numerous opportunities for product innovation, but managing this growth has introduced a support burden of ensuring proper security authentication & authorization, cloud hygiene, and scalable processes. This process is manual, time-consuming, inconsistent, and often a game of trial and error.
To address these issues, organizations that want to digitally transform are adopting cloud observability technology as a bestpractice. With AIOps , practitioners can apply automation to IT operations processes to get to the heart of problems in their infrastructure, applications and code.
While speeding up development processes and reducing complexity does make the lives of Kubernetes operators easier, the inherent abstraction and automation can lead to new types of errors that are difficult to find, troubleshoot, and prevent. The best new feature can be unsuccessful if the customer is unable to use it or does not like it.
Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This ensures that customers can quickly navigate through product listings, add items to their cart, and complete the checkout process without experiencing noticeable delays. or above for the checkout process.
The round trip also measures intermediate steps on that journey such as propagation delay, transmission delay, processing delay, etc. What follows is overall best-practice advice for designing with latency in mind. Where Does CrUX’s RTT Data Come From? Bonus points for deploying preconnect as an HTTP header or Early Hint!
The most beautiful, spectacular site in the world won’t do anyone much good if people can’t find it on Google (or Bing, or DuckDuckGo). Following bestpractice usually means a better website, more organic traffic, and happier visitors. Where Does SEO Belong In Your Web Design Process? ” Google Keyword Planner.
2020, a new game called FAU-G was released on the Google play store. Android UI Testing is the process of testing an android application for UI issues. Android’s official application store, the Google play store, hosts 2.87 Then again the same process repeats. Android UI Testing and Its Types. Perform Usability Testing.
One free tool has become prominent in the space – Google Lighthouse – and one question often bubbles up: “I use Google Lighthouse for one-off snapshots of my site’s performance, so why do I need a performance monitoring solution?” Where Google Lighthouse Shines Bright.
A decent solution is the W3C Trace context standard , created by Dynatrace, Google, Microsoft, and others. As switching or integrating new tools in an automation process is always a lot of work, we expect Keptn to help us lower the automation efforts in our current Jenkins pipelines.
Measurements refer to specific data points, such as the number of seconds it takes to process a request. Wait time: Sometimes called average latency, wait time refers the amount of time a request spends in a queue before it gets processed. Memory utilization: The amount of memory required to process a request.
to run Google Lighthouse audits via the command line, save the reports they generate in JSON format and then compare them so web performance can be monitored as the website grows and develops. I’m hopeful this can serve as a good introduction for any developer interested in learning about how to work with Google Lighthouse programmatically.
Whether you’re just starting out with Figma or have been using it for a good while now, this post will give you just enough pointers to make your design process faster and smoother. Google Fonts. Google Sheets sync. Your design process just got a bit less stressful. Table of Contents. Also, take a look at the other.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content