This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Proactive cost alerting Proactive cost alerting is the practice of implementing automated systems or processes to monitor financial data, identify potential issues or anomalies, ensure compliance, and alert relevant stakeholders before problems escalate. Dynatrace can help you achieve your FinOps strategy using observability bestpractices.
As a result, site reliability has emerged as a critical success metric for many organizations. Aligning site reliability goals with business objectives Because of this, SRE bestpractices align objectives with business outcomes. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
Google has released a new book: The Site Reliability Workbook — Practical Ways to Implement SRE. David Rensin, a SRE at Google, says : It's a whole new book. It's designed to sit next to the original on the bookshelf and for folks to bounce between them -- moving between principle and practice. Incident Response.
This is a potential cause for concern for anyone who cares about metrics like Largest Contentful Paint, which measures the largest visual element on a page – including videos. Review some CSS optimization tips and bestpractices. Core Web Vitals are a Google search ranking factor. Learn how to optimize images.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives.
These functions are executed by a serverless platform or provider (such as AWS Lambda, Azure Functions or Google Cloud Functions) that manages the underlying infrastructure, scaling and billing. Observability is typically achieved by collecting three types of data from a system, metrics, logs and traces.
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Functional FaaS bestpractices. In-depth, AI-driven metrics can help to manage this simplicity. How does function as a service work?
Perform serves yearly as the marquis Dynatrace event to unveil new announcements, learn about new uses and bestpractices, and meet with peers and partners alike. Learn more about Dynatrace and GCP from the ebook 5 Key Considerations for Monitoring Google Cloud.
However, such observation periods come with a disadvantage: incidents can pile up and there is a delay between those incidents and the corresponding health metrics ultimately dropping low enough to trigger a warning. Most monitoring tools offer only a single SLO metric. Get up and running in under a minute with SLO templates.
This is a set of bestpractices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business?
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these bestpractices to innovate at speed without sacrificing quality, reliability, or security. Learn more about DevOps and bestpractices to achieve it at scale.
This greatly reduced the number of metrics to manage and provided a more comprehensive picture of what was behind their primary reliability service-level objective. The metrics behind the four signals vary by row. In this case, the customer offers a managed service that runs on Amazon Web Services, Microsoft Azure, and Google.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. A few bestpractices. Microservices benefits.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. A few bestpractices. Microservices benefits.
Keptn: A reference implementation of Google’s SRE principles. Software engineer Taras Tsugrii of Meta (formerly Facebook) paid Keptn a high compliment, saying it feels like a reference implementation of Google’s SRE principles , which are the search giant’s techniques for ensuring the integrity of its sites and services.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
How To Benchmark And Improve Web Vitals With Real User Metrics. How To Benchmark And Improve Web Vitals With Real User Metrics. Different products will have different benchmarks and two apps may perform differently against the same metrics, but still rank quite similarly to our subjective “good” and “bad” verdicts.
In fact, giants like Google and Microsoft once employed monolithic architectures almost exclusively. Smaller teams can launch services much faster using flexible containerized environments, such as Kubernetes, or serverless functions, such as AWS Lambda, Google Cloud Functions, and Azure Functions. Serverless platforms. Service mesh.
Organizations are constantly being measured against the best available digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Bestpractices for delivering excellent digital experiences. The window of opportunity to save this customer is now very small and closing fast. Break down silos.
Commonly, teams create SLOs because they are simply following what others in the industry are doing, or because they are common bestpractices. However, another of the common SLO pitfalls is that many organizations assemble these metrics manually using disparate tools, which can take time from innovation.
Bestpractices for optimizing images They say a picture is worth a thousand words. Here's a detailed checklist of bestpractices and how-tos to make sure your beautiful images aren't hurting your page speed. According to Google, a 'good' INP time is faster that 200 milliseconds. Find out here. Looking ahead.
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. With this objective, the app ensures that users experience real-time feedback and immediate updates when logging workouts, recording sets and reps, or tracking performance metrics.
A decent solution is the W3C Trace context standard , created by Dynatrace, Google, Microsoft, and others. It automatically sends JMeter metrics to the Dynatrace cluster via the Metrics Ingest API. These metrics can be used to validate the load test plan or target load and to correlate between different application metrics.
Additionally, include benchmarks for stakeholders and bestpractices that support the anticipated growth of the organization as a whole. Establish a FinOps culture that supports buy-in from all stakeholders, as well as metrics that all teams understand and use. FinOps company culture.
In the free ebook “ A Beginner’s Guide to DevOps ,” DevOps is defined as a set of software development and delivery bestpractices to close the gap between software development and IT operations. The three pillars of observability at the time were metrics, logs, and traces,” Wilson said.
RTT data should be seen as an insight and not a metric. Note some of the counties in these URLs: this client has a truly international audience, and latency metrics are of great interest to me. Interestingly, latency only accounts for a small proportion of my overall TTFB metric. RTT isn’t a you-thing, it’s a them-thing.
Let’s explore this concept as we look at the bestpractices and solutions you should keep in mind to overcome the wall and keep up with today’s fast-paced and intricate cloud landscape. Modern operating systems provide capabilities to observe and report various metrics about the applications running.
When using managed environments like Google Kubernetes Engine (GKE) , Amazon Elastic Kubernetes (EKS) , or Azure Kubernetes Service it’s easy to spin up a new cluster. metrics, traces, and logs) to gain a better understanding of the behavior of their code during runtime. Metrics are a numeric representation of intervals over time.
MySQL Backup and Recovery BestPractices In this section, we’ll explore essential MySQL backup and recovery bestpractices to safeguard your data and ensure smooth database operations. This action validates your backups are not corrupted and it provides critical metrics on recovery time. ” Great advice.
If you’re not a developer/designer, you may not be familiar with the Chrome DevTools and the extremely powerful Google Lighthouse Audits that can be found inside. However, you have likely used the Web UI that Google uses to allow you to test websites for speed – Google PageSpeed Insights. BestPractices.
To address these issues, organizations that want to digitally transform are adopting cloud observability technology as a bestpractice. Not just logs, metrics and traces. 9 key DevOps metrics for success. What are the typical use cases for AWS Lambda? What are the challenges related to operating Lambda functions?
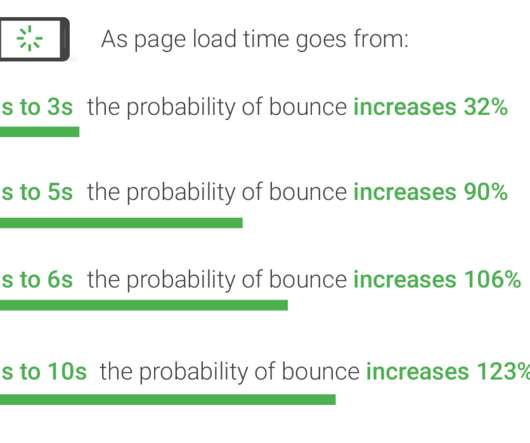
Similar to our article Average Page Load Times for 2018 , we’ll go over the averages for metrics and help you determine if your site is faster or slower than average. As you know, there are many metrics that determine a website’s page speed, and we can’t look at just one of them to determine how performant our site is.
After Google's announcement about Lighthouse 8 this past month, we have updated our test agents. We've gotten a lot of questions about what has changed and the impact on your performance metrics, so here's a summary. In case you missed it, Lighthouse is a speed tool created by the Chrome Developer team at Google. Learn more.
Additionally, teams are measuring and tracking key business metrics – conversion rates, cart abandonment rates, customer lifetime value, revenue by traffic source, and so on. Why Are User-centric Metrics Essential for Ecommerce? Which Metrics Matter for Ecommerce? At this point, you’re probably saying, “Great.
The most beautiful, spectacular site in the world won’t do anyone much good if people can’t find it on Google (or Bing, or DuckDuckGo). Following bestpractice usually means a better website, more organic traffic, and happier visitors. Prioritizing Metrics Online metrics are almost limitless. Google Trends.
The Web Performance Guide is – as its name suggests – a collection of articles we've been writing over the years to answer the most common questions we field about performance topics like site speed, why it matters, how it's measured, website monitoring tools, metrics, analytics, and optimization techniques.
How does page bloat affect other metrics, such as Google's Core Web Vitals? A Google machine-learning study I participated in a few years ago found that the total number of page elements was the single greatest predictor of conversions. This falls short of Google's threshold of 2.5 How does page bloat hurt your business?
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. With this objective, the app ensures that users experience real-time feedback and immediate updates when logging workouts, recording sets and reps, or tracking performance metrics.
to run Google Lighthouse audits via the command line, save the reports they generate in JSON format and then compare them so web performance can be monitored as the website grows and develops. I’m hopeful this can serve as a good introduction for any developer interested in learning about how to work with Google Lighthouse programmatically.
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. MongoDB Replication Strategies.
Reading time 11 min As companies become more aware of the importance of web performance, internal teams begin to research tools they can use to use to track their metrics and improve the user experience of their websites and applications. Where Google Lighthouse Shines Bright. Google Lighthouse has a lot going for it.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content