This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Configuring quorum queues achieves high data safety and reliability in your RabbitMQ setup.
Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency. Here, we’ll tackle the basics, benefits, and bestpractices of IAC, as well as choosing infrastructure-as-code tools for your organization. Exploring IAC bestpractices.
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. Why Black Friday traffic threatens customer experience.
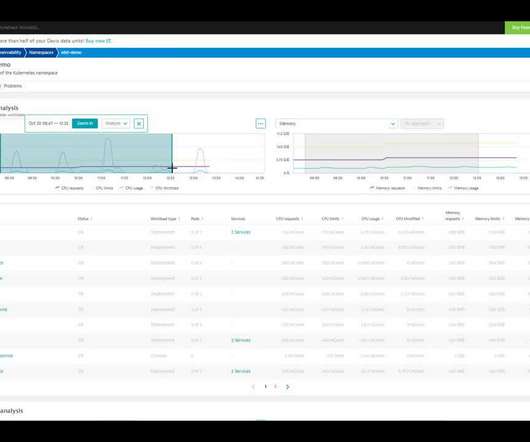
This is done without the need to create custom dashboards and is complemented by efficient analysis capabilities that automatically guide SREs to potential root causes of anomalies, enabling more efficient work and freeing up time for essential workflows. How to prevent this with K8s bestpractices.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. Error budget burn rate = Error Rate / (1 – Target) Bestpractices in SLO configuration To detect if an entity is a good candidate for strong SLO, test your SLO.
Least privilege isnt just bestpractice; it’s your first line of defense. Scheduler and controller manager These components are the conductors of your Kubernetes cluster, ensuring that your applications run smoothly and efficiently. Security principle. Every permission granted should be scrutinized and justified.
Even when the staging environment closely mirrors the production environment, achieving a complete replication of all potential scenarios, such as simulating extremely high traffic volumes to assess software performance, remains challenging. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
In the dynamic world of microservices architecture, efficient service communication is the linchpin that keeps the system running smoothly. In this comprehensive guide, we’ll delve into the world of service meshes and explore bestpractices for their effective management within a microservices environment.
Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Bestpractices to consider. An effective IT infrastructure monitoring strategy includes the following bestpractices: Determine the best cloud tooling and services for your specific cloud environment.
We’ll answer that question and explore cloud migration benefits and bestpractices for how to go through your migration smoothly. In cloud computing environments, infrastructure and services are maintained by the cloud vendor, allowing you to focus on how best to serve your customers. What is cloud migration?
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Employee training in cybersecurity bestpractices and maintaining up-to-date software and systems are also crucial. The unfortunate reality is that software outages are common.
While DORA provides high-level definitions, other regulatory frameworks (such as CIS or DISA-STIG) offer technical specifications used as a basis for technical bestpractices. By combining technical bestpractices with DORA technical specifications, Dynatrace creates technical checks to monitor your organization’s security posture.
In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic. This approach helps you quickly pinpoint potential problems and ensures efficient monitoring of your infrastructure. Add Transmit/Receive (Tx/Rx) bytes using Davis CoPilot.
This SLO highlights the importance of a smooth and efficient checkout experience. Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. Thus, an ApDex score of 0.85 means that 85% of requests met that threshold. The Apdex score of 0.85
Well-Architected Reviews are conducted by AWS customers and AWS Partner Network (APN) Partners to evaluate architectures to understand how well applications align with the multiple Well-Architected Framework design principles and bestpractices. AWS 5-pillars. Seamless monitoring of AWS Services running in AWS Cloud and AWS Outposts.
In the latest enhancements of Dynatrace Log Management and Analytics , Dynatrace extends coverage for Native Syslog support: Use Dynatrace ActiveGate to automatically add context and optimize network traffic to your Syslog messages. Still, an SLO’s quality lies in the significance of the underlying service-level indicator.
However, scaling up software development requires more tools along the software product lifecycle, which must be configured promptly and efficiently. Efficient environment configuration at scale One of software engineers’ most significant challenges is managing the numerous tools and technologies required for the software product lifecycle.
With comprehensive logging support, security, operational efficiency, and application uptime all improve. This enables IT teams to quickly and efficiently find the answers they need. Essentially, log management tools help with organizing logs to ensure log searches and queries are as efficient as possible.
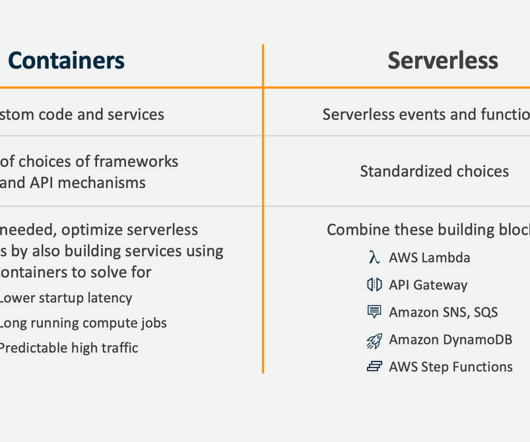
For example, to handle traffic spikes and pay only for what they use. Scale automatically based on the demand and traffic patterns. According to Flexera , serverless functions are the number one technology evaluated by enterprises and one of the top five cloud technologies in use at enterprises.
To address these challenges, architects must design robust and scalable MongoDB databases and adopt appropriate sharding strategies that can efficiently handle increasing workloads while ensuring continuous availability. It’s essential to select an appropriate shard key to ensure even data distribution and efficient querying.
Kubernetes can be complex, which is why we offer comprehensive training that equips you and your team with the expertise and skills to manage database configurations, implement industry bestpractices, and carry out efficient backup and recovery procedures.
This SLO example highlights the importance of a smooth and efficient checkout experience. Traffic The traffic SLO example measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. or above for the checkout process. The Apdex score of 0.85
Log auditing is a cybersecurity practice that involves examining logs generated by various applications, computer systems, and network devices to identify and analyze security-related events. Efficient and effective log audit and forensics practices can require specialized understanding of cloud environments, applications, and log formats.
Then they tried to scale it to cope with high traffic and discovered that some of the state transitions in their step functions were too frequent, and they had some overly chatty calls between AWS lambda functions and S3. They state in the blog that this was quick to build, which is the point.
As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. In the Efficiency space, our data teams focus on transparency and optimization.
The second example was around web-server threads, which turned out that the team ran with default settings for Apache (200 worker threads) which was too low for the traffic the government agencies are receiving during business hours. A reduced resource footprint also makes migrating to a public cloud more cost-efficient.
Many of our customers also run their.NET, ASP.NET,NET Core, SQL Server, CRM, SharePoint … applications on AWS and have reached out to us in the past to ask about bestpractices around optimizing these workloads in order to run more efficiently and more cost effective. Are they receiving traffic? #3:
Learn how RabbitMQ can boost your system’s efficiency and reliability in these practical scenarios. Understanding RabbitMQ as a Message Broker RabbitMQ is a powerful message broker that enables applications to communicate by efficiently directing messages from producers to their intended consumers.
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
The idea CFS operates by very frequently (every few microseconds) applying a set of heuristics which encapsulate a general concept of bestpractices around CPU hardware use. The second placement looks better as each CPU is given its own L1/L2 caches, and we make better use of the two L3 caches available.
This separation aims to streamline transaction write logging, improving efficiency and consistency. Implementing dedicated mounts for components such as binlogs and datadir is a recommended standard practice. It becomes more manageable and efficient by isolating logs and data to a dedicated mount. Who can benefit from DLV?
Getting fast initial render with streaming server-side rendering, efficient component-level updates and state transitions, while also setting up a performant loading and bundling strategy for all the assets is hard and time-consuming technical work. With 100s of real-life examples , guidelines and bestpractices that you can apply right away.
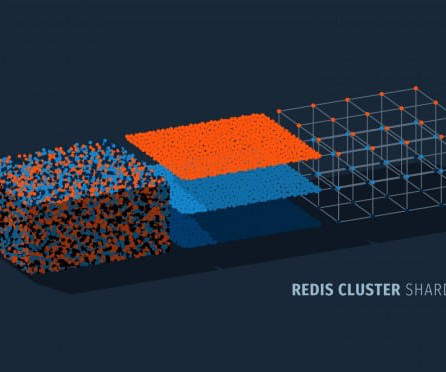
This method involves splitting data over various nodes to improve the database’s efficiency. It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot. These are allocated across multiple Redis cluster nodes. Visualize it as a relay race.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. The public cloud provides flexibility and cost efficiency through utilizing a provider’s resources. These include on-premises data centers which offer specific business benefits.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. For example: $ /opt/mongodb/4.0.6/bin/mongos
Just because everything works perfectly during production testing doesn’t mean that will be the case when your website is flooded with traffic. Bottlenecks can occur, for example, if you have a sudden surge in traffic that your servers are not equipped to handle. What Are the Benefits of Performance Testing?
The bestpractices that we are collecting in the AWS Economics Center are there to help our customers get a total view on their IT cost such that they can accurately compare on-premise and cloud. Making predictions about web traffic is a very difficult endeavor. s a summary chart of the TCO analysis. t need them.
BestPractices for Access Control In RabbitMQ, it is essential to implement authentication and authorization with the principle of least privilege as a guiding force. Configuring Firewalls for RabbitMQ Implementing a firewall for RabbitMQ is crucial in controlling network traffic and safeguarding the system against unauthorized entry.
Load balancing : Traffic is distributed across multiple servers to prevent any one component from becoming overloaded. Load balancers can detect when a component is not responding and put traffic redirection in motion. Please note that these are presented as general bestpractices.
Understanding Redis Performance Indicators Redis is designed to handle high traffic and low latency with its in-memory data store and efficient data structures. These essential data points heavily influence both stability and efficiency within the system. All these contribute significantly towards ensuring smooth functioning.
To be effective, all these images need to be carefully orchestrated to appear on the screen fast — but as it turns out, loading images efficiently at scale isn’t a project for a quiet afternoon. Keeping this efficient helps ensure a good user experience. Image Decoding Performance. +. Measuring Image Performance. +. ePUB, Kindle, PDF.
This level of distribution will seriously affect the efficiency of the operation, which will increase the response time significantly. As illustrated above, ProxySQL allows us to set up a common entry point for the application and then redirect the traffic on the base of identified sharding keys. This is it.
To be effective, all these images need to be carefully orchestrated to appear on the screen fast — but as it turns out, loading images efficiently at scale isn’t a project for a quiet afternoon. Keeping this efficient helps ensure a good user experience. Just think about landing pages and product photos, feature panels and hero areas.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content