This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the last 15+ years, Ive worked on designing APIs that are not only functional but also resilient able to adapt to unexpected failures and maintain performance under pressure. In this article, Ill share practical strategies for designing APIs that scale, handle errors effectively, and remain secure over time.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
These challenges make AWS observability a key practice for building and monitoring cloud-native applications. Let’s take a closer look at what observability in dynamic AWS environments means, why it’s so important, and some AWS monitoring bestpractices. AWS monitoring bestpractices. AWS Lambda.
Here, we’ll tackle the basics, benefits, and bestpractices of IAC, as well as choosing infrastructure-as-code tools for your organization. Infrastructure as code is a practice that automates IT infrastructure provisioning and management by codifying it as software. Exploring IAC bestpractices. Consistency.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
This dedicated infrastructure layer is designed to cater to service-to-service communication, offering essential features like load balancing, security, monitoring, and resilience. It comprises a suite of capabilities, such as managing traffic, enabling service discovery, enhancing security, ensuring observability, and fortifying resilience.
Improving testing by using real traffic from production ( Hacker News). Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & BestPractices). Using MongoDB as a cache store ( Architects Zone – Architectural Design Patterns & BestPractices). Hacker News).
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Employee training in cybersecurity bestpractices and maintaining up-to-date software and systems are also crucial.
As organizations plan, migrate, transform, and operate their workloads on AWS, it’s vital that they follow a consistent approach to evaluating both the on-premises architecture and the upcoming design for cloud-based architecture. AWS 5-pillars. Fully conceptualizing capacity requirements.
We’ll answer that question and explore cloud migration benefits and bestpractices for how to go through your migration smoothly. In case of a spike in traffic, you can automatically spin up more resources, often in a matter of seconds. Likewise, you can scale down when your application experiences decreased traffic.
Monitor your cloud OpenPipeline ™ is the Dynatrace platform data-handling solution designed to seamlessly ingest and process data from any source, regardless of scale or format. Furthermore, OpenPipeline is designed to collect and process data securely and in compliance with industry standards.
Application security monitoring is the practice of monitoring and analyzing applications or software systems to detect vulnerabilities, identify threats, and mitigate attacks. This process may involve behavioral analytics; real-time monitoring of network traffic, user activity, and system logs; and threat intelligence.
Consider a synthetic test designed to evaluate an e-commerce shopping application. When designing synthetic tests, it’s worth using a combination of browser-based, mobile, and desktop tests to assess application performance. This is because each of these traffic vectors comes with unique challenges.
This number was so low because the automatic traffic redirect was so fast it kept the impact so low. As a general bestpractice, Synthetic Tests are great to validate your core use cases are always working as expected. The health-based load balancing of incoming traffic automatically redirects traffic to healthy nodes.
The Dynatrace Site Reliability Guardian is designed for this practice; it allows development teams to define quality objectives in their code, which is validated throughout the delivery process before the code reaches production. We use monitored demo applications to deliver constant load and a defined set of business transactions.
This model is based on deep collaboration with hundreds of customers, all the bestpractices we could find, and a philosophy of transparency and fairness. DPS offers you flexibility to scale-up deployments during peak traffic events or to provide extra observability during high-stakes moments.
Web application security is the process of protecting web applications against various types of threats that are designed to exploit vulnerabilities in an application’s code. Data from Forrester Research provides more detail, finding that 39% of all attacks were designed to exploit vulnerabilities in web applications.
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. Error budget burn rate = Error Rate / (1 – Target) Bestpractices in SLO configuration To detect if an entity is a good candidate for strong SLO, test your SLO.
During a breakout session at Dynatrace’s Perform 2021 event, Senior Product Marketing Manager Logan Franey and Product Manager Dominik Punz shared mobile app monitoring bestpractices to maximize business outcomes. Most organizations have a grab bag of monitoring tools, each designed for a specific use case.
To address these challenges, architects must design robust and scalable MongoDB databases and adopt appropriate sharding strategies that can efficiently handle increasing workloads while ensuring continuous availability. 5) Geo-distributed data It doesn’t matter whether this need comes from application design or legal compliance.
Vitality’s platform is designed to let customers take control of their own wellness by creating insurance and investment frameworks that best meet their needs. As traffic picks up, Real User Monitoring detects HTTP and JavaScript errors, while Session Replay adds experience and error validation to help drive remediation.
These data scientists design and execute tests to support learning agendas and contribute to decision making. The forums where these debates take place are broadly accessible, ensuring a diverse set of viewpoints provide feedback on test designs and results, and weigh in on decisions.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. On the other hand, MongoDB schema design takes a document-oriented approach.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. For services, the gains were even more impressive.
While adequate for low-traffic applications, small databases, and dev/test environments, we recommend against leveraging shared clusters for your MongoDB production deployments. DigitalOcean specialized in SSD-based virtual machines called Droplets that are broken down into four simple categories. MongoDB Replication Strategies.
RTT is designed to replace Effective Connection Type (ECT) with higher resolution timing information. What follows is overall best-practice advice for designing with latency in mind. These intermediates fall outside of the scope of this article, but if you’ve ever run a traceroute , you’re on the right lines.
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. Thus, using Dedicated Log Volumes (DLVs), though new in AWS RDS, has been one of the recommended bestpractices and is a welcome setup improvement for your RDS instance.
Typically, the servers are configured in a primary/replica configuration, with one server designated as the primary server that handles all incoming requests and the others designated as replica servers that monitor the primary and take over its workload if it fails. This flexibility can be crucial in designing a scalable architecture.
and package them in a design (blueprint) of a database infrastructure that’s fit to perform optimally — amid demanding conditions. That design will depict an infrastructure of high availability nodes/clusters that work together (or separately, if necessary) so that if one goes down, another one takes over.
That’s why it’s essential to implement the bestpractices and strategies for MongoDB database backups. Bestpractice tip : It is always advisable to use secondary servers for backups to avoid unnecessary performance degradation on the PRIMARY node. Bestpractice tip : Use PBM to time huge backup sets.
As any seasoned team will know, building the storefront capabilities is one thing, and running it at a production scale that is able to absorb large waves of traffic, driven by flash sales or breakout social campaigns, is a whole other and massive operational challenge. “It Commerce At Shopify Scale: Hydrogen Powered By Oxygen.
They utilize a routing key mechanism that ensures precise navigation paths for message traffic. Task Distribution in Web Servers In web applications experiencing high traffic levels, it is crucial to allocate tasks effectively to avoid overwhelming the servers.
Search engine optimization (SEO) is an essential part of a website’s design, and one all too often overlooked. Implementing SEO bestpractice doesn’t just give you the best chance possible of ranking well in search engines; it makes your websites better by scrutinizing quality, design, accessibility, and speed, among other things.
Using responsive images is a key part of delivering fully responsive web design. For sites with large traffic and a global reach, basic optimizations at build time are usually not enough. Addy is the author of the book Learning JavaScript Design Patterns. Responsive Images. +. Progressive Rendering Techniques. +. Get the eBook.
BestPractices for Access Control In RabbitMQ, it is essential to implement authentication and authorization with the principle of least privilege as a guiding force. Configuring Firewalls for RabbitMQ Implementing a firewall for RabbitMQ is crucial in controlling network traffic and safeguarding the system against unauthorized entry.
You’ve spent months putting together a great website design, crowd-pleasing content, and a business plan to bring it all together. You’ve focused on making the web design responsive to ensure that the widest audience of visitors can access your content. You’ve agonized over design patterns and usability. Ken Harker.
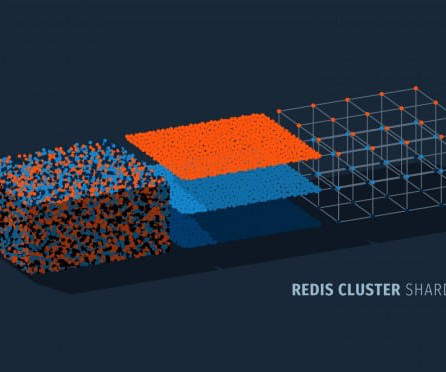
It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot. Redis Sharding: An Overview Consider Redis Cluster as a multi-lane highway where the lanes represent hash slots, and traffic symbolizes data.
MySQL, as well as other RDBMS, are designed to work respecting the model and cannot scale in any way by fragmenting and distributing a schema, so what can be done to scale? As illustrated above, ProxySQL allows us to set up a common entry point for the application and then redirect the traffic on the base of identified sharding keys.
Using responsive images is a key part of delivering fully responsive web design. For sites with large traffic and a global reach, basic optimizations at build time are usually not enough. Designed by Espen Brunborg and Nadia Snopek. Addy is the author of the book Learning JavaScript Design Patterns. Responsive Images. +.
High availability storage options within the context of cloud computing involve highly adaptable storage solutions specifically designed for storing vast amounts of data while providing easy access to it. Storage is a critical aspect to consider when working with cloud workloads.
A trip to the supermarket can teach you a lot about designing software systems and shaping teams to build them… I was recently in need of some chocolate sauce. The Chocolate Sauce Heuristic for Software Design There are a few lessons about software development we can learn from this story, but I want to focus on design.
For example, if the device is a firewall, it might be configured to block all traffic containing (unknown) extensions. In practice, it turns out that an enormous number of active middleboxes make certain assumptions about TCP that no longer hold for the new extensions. We will discuss these features in more depth later in this article.
Traffic refers to the amount of user demand, or load, is on the system. Release engineers are typically tasked with defining bestpractices as it relates to developing software services, deploying updates, continuous testing, and addressing software issues, in addition to many other responsibilities.
Understanding Redis Performance Indicators Redis is designed to handle high traffic and low latency with its in-memory data store and efficient data structures. offers the Software Watchdog specifically designed for this purpose. It can achieve impressive performance, handling up to 50 million operations per second.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content