This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering. Load generators simulate traffic. This allows dynamic techniques like binary search to pinpoint the exact line of problematic code, facilitating more precise performance benchmarking.
However, performance can decline under high traffic conditions. Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role. Low-Latency Messaging Both Kafka and RabbitMQ are capable of low-latency messaging but use different approaches.
Instead, they can ensure that services comport with the pre-established benchmarks. First, it helps to understand that applications and all the services and infrastructure that support them generate telemetry data based on traffic from real users. SLOs improve software quality. So how can teams start implementing SLOs?
Google has a pretty tight grip on the tech industry: it makes by far the most popular browser with the best DevTools, and the most popular search engine, which means that web developers spend most of their time in Chrome, most of their visitors are in Chrome, and a lot of their search traffic will be coming from Google. Why This Is a Problem.
WAFs protect the network perimeter and monitor, filter, or block HTTP traffic. Compared to intrusion detection systems (IDS/IPS), WAFs are focused on the application traffic. RASP solutions sit in or near applications and analyze application behavior and traffic.
Typically, organizations might experience abnormal scanning activity or an unexpected traffic influx that is coming from one specific client. Zero-day attacks can manifest in various subtle forms and are often difficult to detect. Log4Shell became public , Dynatrace Application Security customers had an advantage: Within minutes?
What was once an onslaught of consumer traffic between Black Friday and Cyber Monday has turned into a weeklong event, with most retailers offering deals well ahead of Black Friday. Social media was relatively quiet, and as always, the Dynatrace Insights team was benchmarking key retailer home pages from mobile and desktop perspectives.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. Five-nines availability: The ultimate benchmark of system availability. The nirvana state of system uptime at peak loads is known as “five-nines availability.”
RUM, however, has some limitations, including the following: RUM requires traffic to be useful. In some cases, you will lack benchmarking capabilities. Because RUM relies on user-generated traffic, it’s hard to indicate persistent issues across the board. Real user monitoring limitations. RUM generates a lot of data.
How Dynatrace RUM helped one company identify the business impacts of the CrowdStrike outage For example, during the CrowdStrike crisis, a North American mortgage provider received an alert for unexpected low traffic. Dynatrace AI continuously monitors these benchmarks, allowing teams to identify and address potential issues proactively.
We performed a standard benchmarking test using the sysbench tool to compare the performance of a DLV instance vs a standard RDS MySQL instance, as shared in the following section. Benchmarking AWS RDS DLV setup Setup 2 RDS Single DB instances 1 EC2 Instance Regular DLV Enabled Sysbench db.m6i.2xlarge 2xlarge c5.2xlarge MySQL 8.0.31
First, the company uses synthetic monitoring to develop user experience benchmarks and determine if applications are performing within expected thresholds. As traffic picks up, Real User Monitoring detects HTTP and JavaScript errors, while Session Replay adds experience and error validation to help drive remediation. DEM in action.
Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. Telltale provides Edgar with latency benchmarks that indicate if the individual trace’s latency is abnormal for this given service. Is this an anomaly or are we dealing with a pattern?
During the holiday season, an e-commerce platform anticipating a traffic surge could use preventive observability to predict slowdowns or overloads, proactively scale resources, optimize performance, and balance cloud costs. The resurgence of AIOps will redefine industry benchmarks for efficiency and resilience.
With Dynatrace Synthetic you can deliver clean-room performance benchmark and availability monitoring for your business. Some organizations require adding IP addresses to security configurations to allow traffic from and to them. your website or application) needs to accept traffic from the IP addresses of our synthetic locations.
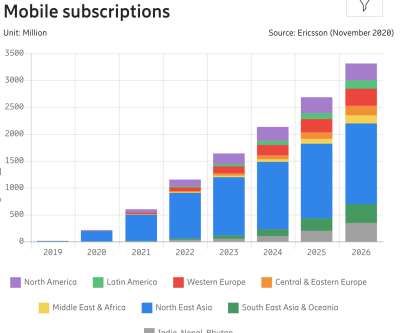
These days, with mobile traffic accounting for over 50% of web traffic , it’s fair to assume that the very first encounter of your prospect customers with your brand will happen on a mobile device. A performance benchmark Lighthouse is well-known. billion by 2026. Its CI counterpart not so much. Large preview ).
We took a hybrid head-based sampling approach that allows for recording 100% of traces for a specific and configurable set of requests, while continuing to randomly sample traffic per the policy set at ingestion point. This allowed us to increase total storage capacity without adding a new Cassandra node to the existing cluster.
JavaScript benchmark. . $2 billion : Pokémon GO revenue since launch; 10 : say happy birthday to StackOverflow; $148 million : Uber data breach fine; 75% : streaming music industry revenue in the US; 5.2 billion increase in pure-play foundry market; Quotable Quotes: WhatsApp cofounder : I am a sellout. How does Apple do it?!
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures.
Back in the day I wrote a lot of benchmarks in order to look for places where the actual performance of the CPU didn’t match what we expected. I wrote a lot of benchmarks. One benchmark I wrote measured the L2 cache latency. So, anyway.
Number of slow queries recorded Select types, sorts, locks, and total questions against a database Command counters and handlers used by queries give an overall traffic summary Along with this, PMM also comes with Query Analytics giving much detailed information about queries getting executed.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
I suggest it’s long past time to move beyond C and SPEC benchmarks and our exclusive focus on “metal” languages. There are already standard benchmark suites for JavaScript performance in the browser, and we can include applications written in node.js (server-side JavaScript), Python web servers, and more.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. It depends upon your application workload and its business logic.
Load balancing : Traffic is distributed across multiple servers to prevent any one component from becoming overloaded. Load balancers can detect when a component is not responding and put traffic redirection in motion. If a server fails, the load balancer redirects traffic to a replicated server in another cluster.
As an ad publisher, your revenue depends on two main factors: traffic to your site and ad optimization. A lot of the focus goes into the practice and processes of driving traffic to your site from an SEO perspective, but what if when visitors get to your site, they have a less than ideal experience? Dotcom-Monitor Website Monitoring.
Compute optimized – High CPU-to-memory ration, medium traffic web servers and application servers. The common trend is to choose a VM based exclusively on vCPU, memory, and storage capacity without benchmarking the current IO and throughput requirements. Benchmark Test. Storage optimized – High disk throughput and IO.
Looking across a set of eight Java benchmarks, we find that only two of them are array dominated, the rest having between 40% to 75% of the heap footprint allocated to objects, the vast majority of which are small. Consider a B-Tree node from the B-tree Java benchmark: Uncompressed, it’s memory layout looks like (a) below. Evaluation.
In this case, we have a quite well-defined scenario that can resemble the image below: In this scenario, the proxies must sit inside Pods, balancing the incoming traffic from the Service LoadBalancer connecting with the active data nodes.
When I think of network speeds, I tend to rely on WebPageTest ’s traffic profiles: Traffic profiles to keep in mind on WebPageTest : ranging from Cable and DSL to 3G Slow and 2G. The table below is showing the total amount of traffic used. Large preview ). Another thing to keep in mind is Constant Rate Factor.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
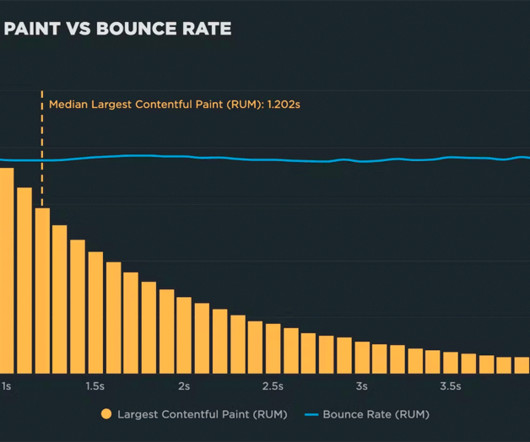
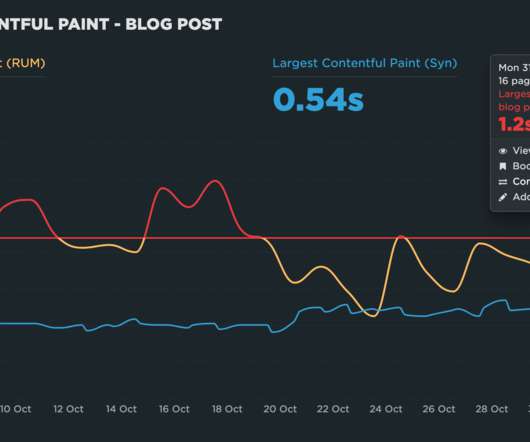
Background For this new investigation, I selected four sites that experience a significant amount of user traffic. Related: Web performance for retailers How to create correlation charts How to benchmark your site against your competitors How to set up real user monitoring (RUM)
Page labels give you the ability to: Compare and benchmark similar pages across different sites. Compare and benchmark similar pages across different sites. Benchmark key pages against those of your competitors. Benchmark Dashboard from SpeedCurve. Why should I care about page labels? How do page labels help me?
Benchmark your site against your competitors Our public-facing Industry Benchmarks dashboard gets a lot of visits, but did you know you can create your own custom competitive benchmarking dashboard in SpeedCurve? READ : How to create a competitive benchmark dashboard ––––– 4.
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. CPU profile Understanding a CPU time should be easy by comparing [CPU flame graphs]. The CentOS flame graph: The Ubuntu flame graph: Darn, they didn't work.
Your current competitive benchmarks status. Evaluate CDN performance by exploring the impact of time-of-day traffic patterns. Fixing high-traffic but poor-performing areas of your site will help lift your overall metrics. Expanded Industry Speed Benchmarks. The current status of your performance budgets.
Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold. Pagespeed Benchmarks - US Retail - LCP When you examine a waterfall, it's pretty obvious that TTFB is the long pole in the tent, pushing out render times for the page.
For vertical scaling, Memcached allows augmenting existing servers with additional CPU cores and memory, thereby enhancing the capacity of the caching pool to manage higher traffic volumes and larger data loads.
Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. CrUX data collection and first-party RUM analytics of these metrics require live traffic, meaning results can be predicted but only verified once deployed. A 2021 Global Baseline.
Load balancing: Traffic is distributed across multiple servers to prevent any one component from becoming overloaded. Load balancers can detect when a component is not responding and put traffic redirection in motion. Failure detection: Monitoring mechanisms detect failures or issues that could lead to failures.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Just because everything works perfectly during production testing doesn’t mean that will be the case when your website is flooded with traffic.
They can also highlight very long redirection chains in your third-party traffic. They are more of a benchmark than a true measurement of real user experience. As a discovery tool, request maps are great for identifying the source of third-party, fourth-party, fifth-party, etc.,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content