This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more.
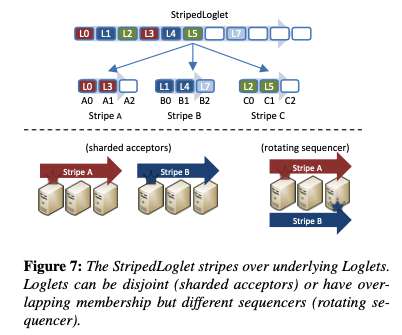
Virtual consensus in Delos , Balakrishnan et al. If you think of this a bit like mapping memory addresses to data in memory, then another parallel comes to mind: the virtual address space. We propose the novel abstraction of a virtual shared log (or VirtualLog). Facebook, Inc. ), OSDI’2020. What does the VirtualLog give us?
The Linux VM running postgres has two virtual disks – one taking transaction log writes. The post View from Nutanix storage during Postgres DB benchmark appeared first on n0derunner. A quick look at how the workload is seen from the Nutanix CVM. In this example from prior post.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. One important choice you will still have to make is what type and size of Azure virtual machine you want to use for your existing SQL Server workload.
With help from the Nutanix X-Ray team I have created an IO “benchmark” which simulates a “General Server Virtualization” workload. The post A Generalized workload generator for storage IO appeared first on n0derunner.
Migrating an on-premises SQL Server instance to an Azure Virtual Machine (VM) is a common method to migrate to Azure. IT professionals are familiar with scoping the size of VMs with regards to vCPU, memory, and storage capacity. Microsoft has helped simplify things by creating multiple types of virtual machines. Generation.
Various forms can take shape when discussing workloads within the realm of cloud computing environments – examples include order management databases, collaboration tools, videoconferencing systems, virtual desktops, and disaster recovery mechanisms. Storage is a critical aspect to consider when working with cloud workloads.
PMM2 uses VictoriaMetrics (VM) as its metrics storage engine. Please note that the focus of these tests was around standard metrics gathering and display, we’ll use a future blog post to benchmark some of the more intensive query analytics (QAN) performance numbers. Virtual Memory utilization was averaging 48 GB of RAM.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. I wrote about using CPU-Z to benchmark the Intel Xeon E5-2673 v3 processor in an Azure VM in this article. Figure 1: CPU-Z Benchmark Results for LS16v2. SQL Server Impact.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. We have long been surfing the virtualization wave (to keep it broad).
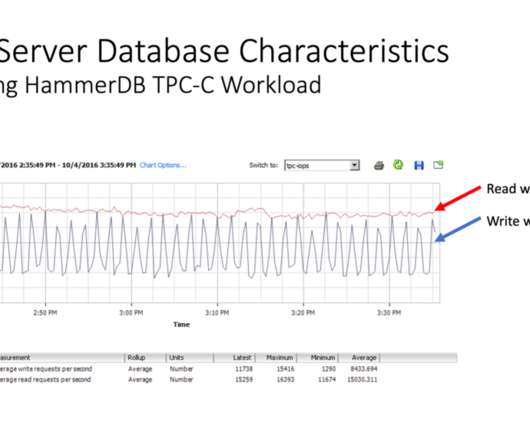
HammerDB is a software application for database benchmarking. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
Regardless of whether the computing platform to be evaluated is on-prem, containerized, virtualized, or in the cloud, it is crucial to consider several essential factors. As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components.
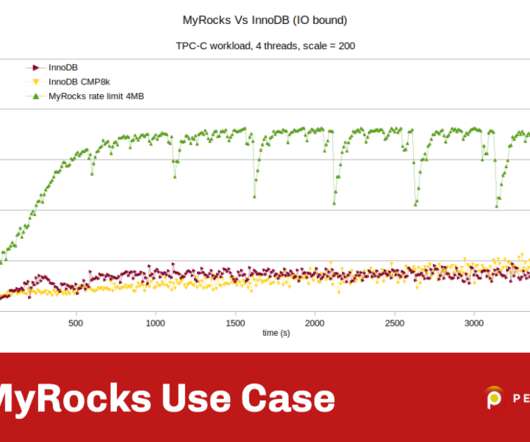
I wrote this post on MyRocks because I believe it is the most interesting new MySQL storage engine to have appeared over the last few years. The use case is the TPC-C benchmark but executed not on a high-end server but on a lower-spec virtual machine that is I/O limited like for example, with AWS EBS volumes. Conclusion.
High availability works through a combination of the following: No single point of failure (SPOF) : You must eliminate any single point of failure in the database environment, including physical or virtual hardware the database system relies on that would cause it to fail. there cannot be high availability.
Containerized data workloads running on Kubernetes offer several advantages over traditional virtual machine/bare metal based data workloads including but not limited to. faster access to external storage and data locality (I/O, bandwidth). Storage provisioning. But Kubernetes storage is evolving quite quickly.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The work includes changes to the CHERI ISA, the C compiler, the C language runtime, the virtual memory APIs, and the CheriBSD kernel. ASPLOS’19. slower to 9.8% PostgreSQL runs 6.8%
Jobs Configuration and Storage. The base configuration for the jobs storage can be found in the generic.xml file in the commandline section. <commandline> If the storage of job related data is not desired, then it is possible to disable/enable this feature with the jobs disable command. Use a different Browser.
and the test will run with the number of Virtual Users equivalent to the number of CPUs. Benchmark set to TPC-C for MariaDB. Building 20 Warehouses with 5 Virtual Users, 4 active + 1 Monitor VU(dict value maria_num_vu is set to 4). in host REDPOLL:3306 under user ROOT in database TPCC with storage engine INNODB?
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . The first example shows a data load, the second a TPC-C based workload with 5 virtual users and the 2nd example with 10 virtual users. innodb_flush_log_at_trx_commit=0. PostgreSQL.
The initial reviews and benchmarks for these processors have been very impressive: AMD EPYC 7002 Series Rome Delivers a Knockout. AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked. TPC-H Benchmark Results with SQL Server 2017. TPC-E Benchmark Results with SQL Server 2017. More total PCIe lanes and bandwidth.
We’ll note how some of the Linux parameter settings used OS tuning may vary according to different system types: physical, virtual or cloud. In this benchmark, I discovered some interesting discrepancies in performance between AMD and Intel CPUs when running under systemd. Fsync Performance on Storage Devices. Interested?
The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint. more transactions than system B in the fully audited benchmark then the HammerDB result was also 1.5X I.e. if system A generated 1.5X
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. Chrome has missed several APIs for 3+ years: Storage Access API.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Without enough infrastructure (physical or virtualized servers, networking, etc.), there cannot be high availability.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. InnoDB is the storage engine that will deliver the best OLTP throughput and should be chosen for this test. . Error in Virtual User 1: mysqlexec/db server: Table 'mysql.proc' doesn't exist.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. These are areas in which we have invested heavily to take advantage of 10 Gbps (and faster) networks and to handle intermittent network delays inherent in virtual server infrastructures.
Stable Media Stable media is often confused with physical storage. SQL Server defines stable media as storage that can survive system restart or common failure. Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. See the article for more details. SQL Server 7.0
Another big jump, but now it was my job to run benchmarks in the lab, and write white papers that explained the new products to the world, as they were launched. I was mostly coding in C, tuning FORTRAN, and when I needed to do a lot of data analysis of benchmark results used the S-PLUS statistics language, that is the predecessor to R.
The storage space that is required for the sparse file is only that of the actual bytes written to the file and not the maximum file size.
Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019. To optimize storage interally, you could use Dropbox’s new Lepton format for losslessly compressing JPEGs by an average of 22%. Faster devices on faster networks have virtually no stalls. compared to early 2015. Large preview ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content