This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
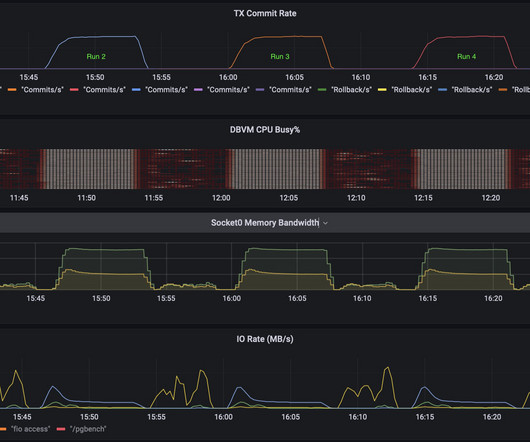
To do this I needed to drive postgres to do real transactions but have very little jitter/noise from the filesystem and storage. After reading a lot of blogs I came … The post Notes on tuning postgres for cpu and memory benchmarking appeared first on n0derunner.
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
ScaleGrid provides 30% more storage on average vs. DigitalOcean for MySQL at the same affordable price. MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. Read-Intensive Throughput Benchmark.
On average, ScaleGrid provides over 30% more storage vs. DigitalOcean for PostgreSQL at the same affordable price. ScaleGrid for PostgreSQL is architectured to leverage-high performance SSD disks on DigitalOcean, and is finely tuned and optimized to achieve the best performance on DigitalOcean infrastructure. Benchmark Tool.
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Storage: don’t break the bank!
In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience. This service leverages Cassandra and Elasticsearch for data storage and retrieval. When onboarding embedding vector data we performed an extensive benchmarking to evaluate the available datastores.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. pg_repack – reorganizes tables online to reclaim storage. PostgreSQL offers more light-weight tuning capabilities, like their Query Optimizer, and DBaaS platforms like ScaleGrid offer advanced slow query analysis.
Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. Benchmark before you decide. Cloud Different cloud providers offer a range of instance types and sizes, each with varying amounts of CPU, memory, and storage. Transparent huge pages (THP) disabled.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? To be fair, that is also true with PostgreSQL; it hasn’t been tuned either, and it, too, can also perform much better.
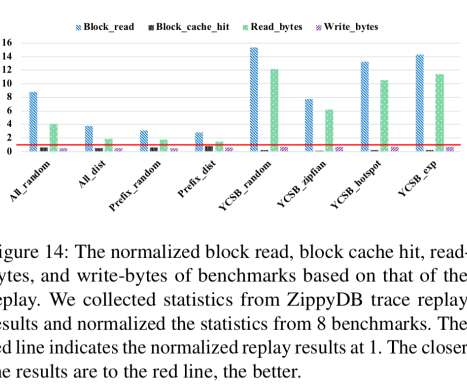
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
In this video I migrate a Postgres DB running PGbench benchmark. As the DB continues to run on the new host – the Nutanix storage detects the access patterns and “localizes” the data that the DB is accessing. Many different queries are executing in parallel, some hitting RAM cache, some hitting storage.
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. These have inspired me to summarize another performance activity: evaluating benchmark accuracy. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
xlarge 4vCPU 8GB-RAM Storage: EBS volume (root) 80GB gp2 (IOPS 240/3000) As well, high availability will be integrated, guaranteeing cluster viability in the case that one worker node goes down. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. It depends upon your application workload and its business logic.
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. These have inspired me to summarize another performance activity: evaluating benchmark accuracy. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. For storage, FIO is generally used. Benchmarking the target Two of the more popular database benchmarks for MySQL are HammerDB and sysbench. 0.42 %sys 9.52
It can help us to save costs on storage and backup times. While MySQL can handle large data sets, it is always recommended to keep only the used data in the databases, as this will make data access more efficient, and also will help to save costs on storage and backups. 1 mysql mysql 704M Dec 30 02:28 employees.ibd -rw-r --.
Linux OS Tuning for MySQL Database Performance. In this post we will review the most important Linux settings to adjust for performance tuning and optimization of a MySQL database server. We’ll note how some of the Linux parameter settings used OS tuning may vary according to different system types: physical, virtual or cloud.
Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench. The illustrations below are taken from Percona Monitoring and Management (PMM) while running this benchmark. Analyzing read/write workload by counts.
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . A good example of how tuning is an iterative process. For MySQL the dependency is at the storage engine level and in this case for the InnoDB storage engine the parameter is self-explanatory. PostgreSQL.
Otherwise, the storage engine does a scatter-gather and queries ALL partitions in a UNION that is not concurrent. This method distributes data evenly across partitions to achieve balanced storage and optimal query performance. This helps identify potential issues and fine-tune the partitioning strategy.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. InnoDB is the storage engine that will deliver the best OLTP throughput and should be chosen for this test. . This is to be expected and is due to the limitations of the scalability of the storage engine.
Stable Media Stable media is often confused with physical storage. SQL Server defines stable media as storage that can survive system restart or common failure. Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. See the article for more details. SQL Server 7.0
Another big jump, but now it was my job to run benchmarks in the lab, and write white papers that explained the new products to the world, as they were launched. I was mostly coding in C, tuning FORTRAN, and when I needed to do a lot of data analysis of benchmark results used the S-PLUS statistics language, that is the predecessor to R.
In the end, I had to add four additional permissions—”tabs”, “storage”, “scripting”, “identity”—as well as a separate “host_permissions” field to my manifest.json. Right now, widely-used benchmarks for AI code generation (e.g.,
The storage space that is required for the sparse file is only that of the actual bytes written to the file and not the maximum file size.
It is limited by the disk space; it can’t expand storage elastically; it chokes if you run few I/O intensive processes or try collaborating with 100 other users. Over time, costs for S3 and GCS became reasonable and with Egnyte’s storage plugin architecture, our customers can now bring in any storage backend of their choice.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content