This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering. Load generators simulate traffic. This allows dynamic techniques like binary search to pinpoint the exact line of problematic code, facilitating more precise performance benchmarking.
Instead, they can ensure that services comport with the pre-established benchmarks. When organizations implement SLOs, they can improve software development processes and application performance. SLOs improve software quality. SLOs promote automation. SLOs minimize downtime. So how can teams start implementing SLOs?
Zero day refers to security vulnerabilities that are discovered in software when teams had “zero days” to work on an update or a patch to remediate the issue and, hence, are already at risk. If a malicious attacker can identify a key software vulnerability, they can exploit the vulnerability, allowing them to gain access to your systems.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
On July 19th, countless organizations had their operations disrupted by a routine software update from CrowdStrike, a popular cybersecurity software. The company was back to normal business operations as other companies continued to struggle with recovering days after the initial software push. Before a crisis. During a crisis.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. Five-nines availability: The ultimate benchmark of system availability. The nirvana state of system uptime at peak loads is known as “five-nines availability.”
We performed a standard benchmarking test using the sysbench tool to compare the performance of a DLV instance vs a standard RDS MySQL instance, as shared in the following section. Benchmarking AWS RDS DLV setup Setup 2 RDS Single DB instances 1 EC2 Instance Regular DLV Enabled Sysbench db.m6i.2xlarge 2xlarge c5.2xlarge MySQL 8.0.31
Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. Telltale provides Edgar with latency benchmarks that indicate if the individual trace’s latency is abnormal for this given service. Is this an anomaly or are we dealing with a pattern?
During the holiday season, an e-commerce platform anticipating a traffic surge could use preventive observability to predict slowdowns or overloads, proactively scale resources, optimize performance, and balance cloud costs. The resurgence of AIOps will redefine industry benchmarks for efficiency and resilience.
We took a hybrid head-based sampling approach that allows for recording 100% of traces for a specific and configurable set of requests, while continuing to randomly sample traffic per the policy set at ingestion point. The scope and complexity of our software systems continue to increase as Netflix grows. What’s next?
It is much worse to be a software developer now. JavaScript benchmark. . $2 billion : Pokémon GO revenue since launch; 10 : say happy birthday to StackOverflow; $148 million : Uber data breach fine; 75% : streaming music industry revenue in the US; 5.2 I acknowledge that. It's the fastest device I've ever tested.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
Back in the day I wrote a lot of benchmarks in order to look for places where the actual performance of the CPU didn’t match what we expected. I wrote a lot of benchmarks. One benchmark I wrote measured the L2 cache latency. So, anyway. Since the Xbox 360 CPU ran at 3.2 nanoseconds for the signals to propagate that 5.5
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Load balancers can detect when a component is not responding and put traffic redirection in motion.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures.
I suggest it’s long past time to move beyond C and SPEC benchmarks and our exclusive focus on “metal” languages. There are already standard benchmark suites for JavaScript performance in the browser, and we can include applications written in node.js (server-side JavaScript), Python web servers, and more.
Number of slow queries recorded Select types, sorts, locks, and total questions against a database Command counters and handlers used by queries give an overall traffic summary Along with this, PMM also comes with Query Analytics giving much detailed information about queries getting executed.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. offers the Software Watchdog specifically designed for this purpose.
Looking across a set of eight Java benchmarks, we find that only two of them are array dominated, the rest having between 40% to 75% of the heap footprint allocated to objects, the vast majority of which are small. Consider a B-Tree node from the B-tree Java benchmark: Uncompressed, it’s memory layout looks like (a) below. Evaluation.
Load balancing: Traffic is distributed across multiple servers to prevent any one component from becoming overloaded. Load balancers can detect when a component is not responding and put traffic redirection in motion. Fault tolerance incorporates multiple versions of hardware and software, and it also includes power supply backups.
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. But I'm not completely sure.
Implementing load balancing has several benefits when it comes to managing workload on the cloud – incoming traffic is equitably spread across various servers or resources, which reduces strain on each resource and ultimately enhances overall system efficiency. What is an example of a workload?
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. In the context of web development, performance testing entails using software tools to simulate how an application runs under specific circumstances.
One of the key strengths of synthetic monitoring solutions is that they can help you assess the performance and user experience (UX) of a site without requiring large volumes of real users driving traffic, a known weakness RUM or APM solutions. If virtualized, what is the technology used (VM, Docker, software package)?
In technical terms, network-level firewalls regulate access by blocking or permitting traffic based on predefined rules. â€At its core, WAF operates by adhering to a rulebook—a comprehensive list of conditions that dictate how to handle incoming web traffic. You've put new rules in place.
The measured traffic is not of your actual users; it is synthetically generated to collect data on page performance. Benchmark Against Competitors. Then, they can effectively benchmark their own performance against those key competitors over time. Synthetic Monitoring. Real User Monitoring (RUM). Run 24/7 Monitoring.
An opening scene involving a traffic jam of Viking boats and a musical number (“Love Can’t Afjord to wait”). While the ultimate goal is still to save money, it’s human FTE hours as opposed to hardware and software costs. Vikings fight zombies. With transformer Viking ships. A Viking shepherd superhero.
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
In technical terms, network-level firewalls regulate access by blocking or permitting traffic based on predefined rules. At its core, WAF operates by adhering to a rulebook—a comprehensive list of conditions that dictate how to handle incoming web traffic. You've put new rules in place.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. ASPLOS’19. Distributed tracing and instrumentation.
An opening scene involving a traffic jam of Viking boats and a musical number (“Love Can’t Afjord to wait”). While the ultimate goal is still to save money, it’s human FTE hours as opposed to hardware and software costs. Vikings fight zombies. With transformer Viking ships. A Viking shepherd superhero.
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. But I'm not completely sure.
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. Doing extensive benchmarks will be the subject of a future blog post. In any case, you should benchmark both RDS MySQL and Aurora before taking the decision to migrate.
This does not apply to read (SELECT) traffic. It is a good idea to run sysbench or another benchmark tool to determine your storage throughput. Whether you need consulting, support, or software solutions, Percona can assist you in achieving the best performance from your MySQL database.
No other aspect of modern software is as poorly managed in otherwise functional engineering organisations. Moving traffic from one histogram bucket to another becomes a measure of success, and teams at Level 3 begin to understand their distributions are nonparametric , and they adopt more appropriate comparisons in response.
CrUX generates an overview of performance distributions over time, with traffic collected from Google Chrome users. But account for the different types and usage behaviors of your customers (which Tobias Baldauf called cadence and cohorts ), along with bot traffic and seasonality effects. You can create your own on Chrome UX Dashboard.
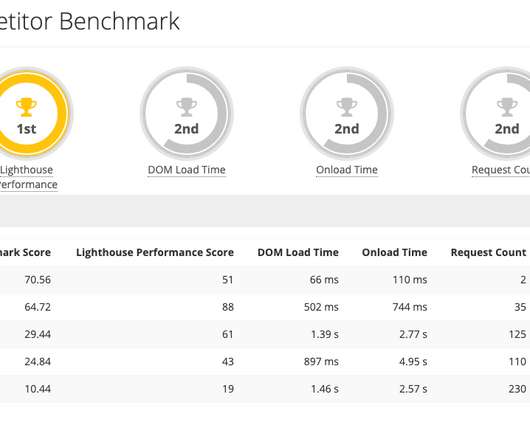
For Mac OS, we can use Network Link Conditioner , for Windows Windows Traffic Shaper , for Linux netem , and for FreeBSD dummynet. Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019. Lighthouse , a performance auditing tool integrated into DevTools. Large preview ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content