This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As more organizations move their PostgreSQL databases onto Kubernetes, a common question arises: Which storage solution best handles its demands? For stateful workloads like PostgreSQL, storage must offer high availability and safeguard data integrity, even under intense, high-volume conditions.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. If you don’t have insight into the software and services that operate your business, you can’t efficiently run your business. Dynatrace news. What is infrastructure monitoring?
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. Easier rollout thanks to log storage best practices. Easier rollout thanks to log storage best practices. Dynatrace news. Advanced customization of OneAgent deployments made easy.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle. Wednesday?—?December
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Storage: don’t break the bank!
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads.
This difference has substantial technological implications, from the classification of what’s interesting to transport to cost-effective storage (keep an eye out for later Netflix Tech Blog posts addressing these topics). As you can imagine, this comes with very real storage costs. Is this an anomaly or are we dealing with a pattern?
In summary, this model was a tightly-coupled application-to-data architecture, where machine learning algos were mixed with the backend and UI/UX software code stack. This service leverages Cassandra and Elasticsearch for data storage and retrieval. It can store and retrieve temporal (timestamp) as well as spatial (coordinates) data.
Querying the data While it is reasonable to create panels showing real-time load in order to explore better the types of queries that can be run against pg_stat_monitor, it is more practical to copy and query the data into tables after the benchmarking has completed its run. A script executing a benchmarking run: #!/bin/bash
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle. Wednesday?—?December
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle. Wednesday?—?December
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Software Update License & Support (annual). $0. Oracle also offers many tools, but they are all available as add-on solutions with additional processor license and software update license costs and support fees. pg_repack – reorganizes tables online to reclaim storage. Oracle Enterprise Edition. Not available.
Traditional self-managed ones give organizations full control over their database infrastructure, such as picking the software and scaling it up. These databases require significant time commitment along with necessary technical skills plus hardware & software costs, all of which are without dedicated team assistance.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Indexing efficiency Monitoring indexing efficiency in MySQL involves analyzing query performance, using EXPLAIN statements, utilizing performance monitoring tools, reviewing error logs, performing regular index maintenance, and benchmarking/testing. This KPI is also directly related to Query Performance and helps improve it.
Storage is a critical aspect to consider when working with cloud workloads. High availability storage options within the context of cloud computing involve highly adaptable storage solutions specifically designed for storing vast amounts of data while providing easy access to it. What is an example of a workload?
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. For cost calculations, the costs are a combination of compute costs, storage costs, data scan costs, and software license costs. Key findings. System initialisation time.
Netflix engineers run a series of tests and benchmarks to validate the device across multiple dimensions including compatibility of the device with the Netflix SDK, device performance, audio-video playback quality, license handling, encryption and security. We use Spinnaker to deploy instances and host the API containers on Titus ?—?which
PMM2 uses VictoriaMetrics (VM) as its metrics storage engine. Please note that the focus of these tests was around standard metrics gathering and display, we’ll use a future blog post to benchmark some of the more intensive query analytics (QAN) performance numbers.
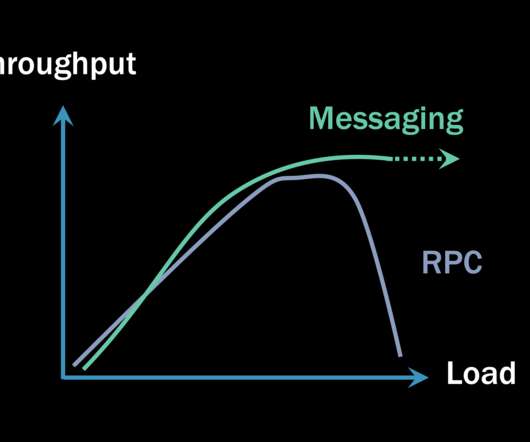
Why RPC is “faster” It’s tempting to simply write a micro-benchmark test where we issue 1000 requests to a server over HTTP and then repeat the same test with asynchronous messages. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
This is not a problem for PostgreSQL alone; every database software needs to deal with this problem. Configured checkpoint frequency, the chance of checkpoints triggered by WAL generation, storage performance, acceptable CPU overhead, type of CPU architecture, and many other factors.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. offers the Software Watchdog specifically designed for this purpose.
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking.
Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench. The illustrations below are taken from Percona Monitoring and Management (PMM) while running this benchmark. Analyzing read/write workload by counts.
Among the different components of modern software solutions, the database is one of the most critical. As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. For storage, FIO is generally used. 4.22 %usr 38.40
Over last few years, we have seen several attempts to run data workload in the containers especially distributed big data frameworks like Apache Hadoop, Apache Storm [3] , and Apache Spark [4] [5] without any software modifications. faster access to external storage and data locality (I/O, bandwidth). Storage provisioning.
It can help us to save costs on storage and backup times. While MySQL can handle large data sets, it is always recommended to keep only the used data in the databases, as this will make data access more efficient, and also will help to save costs on storage and backups. 1 mysql mysql 704M Dec 30 02:28 employees.ibd -rw-r --.
On your first try, you can use it as a benchmark for optimizations later. Developing software is becoming easier as frameworks like React, Vue, or Angular become the go-to solution for creating even the simplest applications. Caching partially stores your data and is not used as permanent storage.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. Chrome has missed several APIs for 3+ years: Storage Access API. Web Serial.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. For a macro-benchmark PostgreSQL’s initdb tool was used. slower to 9.8% faster for system calls).
After the “data dictionary” (DD) engine and DD cache are initialized on a server, the Storage Engines can ask for a table definition. Benchmarks xtrabackup –prepare on backup directory of other sizes like 10K, 50K, 100K, and 250K tables. This search tuple (key) is used to find the record to perform the undo operation.
If you are already using Cosmos DB to store your business data, you no longer need to use a different storage technology to store your NServiceBus saga data. How does this compare with Azure Storage Persistence? For a scenario of 1,000 sagas, we’ve seen a 30% performance increase using Cosmos DB over Table Storage.
With the Percona Database Performance Blog, Percona staff and leadership work hard to provide the open source community with insights, technical support, predictions and metrics around multiple open source database software technologies. Fsync Performance on Storage Devices. A Look at MyRocks Performance. Interested?
Topology management — This is the software management related specifically to the database and managing its ability to stay consistent in the event of a failure. Connection management — This is the software management related specifically to the networking and connectivity aspect of the database. What is fault tolerance?
I really wanted to go beyond these quick gut reactions that I’ve seen so much of online, so I tried using ChatGPT for a few weeks to help me implement a hobby software project and took notes on what I found interesting. That’s because once the software environment has been set up (e.g., using “22” for the year 2022). and chrono-node.
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. It also supports auto-scaling of compute and storage resources, dynamically adjusting capacity based on chosen utilization thresholds to optimize performance and costs.
A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint.
We have spent a great deal of time at ScaleOut Software re-architecting our in-memory data grid (IMDG)’s code base to make best use of many cores and large memory. For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Testing Scale-Up Performance.
Inadequate CPU, memory, or storage can lead to bottlenecks and performance degradation, so remedying these issues involves upgrading hardware or optimizing resource utilization through query and server configuration adjustments. Avoid over-indexing, which can bloat storage and slow writes. This does not apply to read (SELECT) traffic.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. InnoDB is the storage engine that will deliver the best OLTP throughput and should be chosen for this test. . CPUs which need to have their frequency coordinated by software: 0 .
Stable Media Stable media is often confused with physical storage. SQL Server defines stable media as storage that can survive system restart or common failure. Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. See the article for more details. SQL Server 7.0
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content