This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. What is RabbitMQ? This allows Kafka clusters to handle high-throughput workloads efficiently.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Recovery time of the latency p90. However, we noticed that GPT 3.5
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. Scalability. PostgreSQL offers free scalability, and can scale up to millions of transactions per seconds. Oracle Enterprise is recommended for high workloads which are highly scalable, but costly. PostgreSQL.
Because they’re separate, they allow for faster release cycles, greater scalability, and the flexibility to test new methodologies and technologies. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices. Keeping track of the migration stages, phases, and environments is not always easy.
An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Our engineering teams tuned their services for performance after factoring in increased resource utilization due to tracing. Storage: don’t break the bank!
In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience. The primary searcher used in the current implementation is called Marken — scalable annotation service built at Netflix. We will continue to share our work in this space, so stay tuned.
Benchmark before you decide. Some cloud providers also offer specialized instances for database workloads, which may provide additional features and optimizations for performance and scalability. If you see concurrency issues, you can tune this variable. Transparent huge pages (THP) disabled. I hope this helps!
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io 's 5-part learning path: Scalability and System Design for Developers. Generous free tier.
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io 's 5-part learning path: Scalability and System Design for Developers. Generous free tier.
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io 's 5-part learning path: Scalability and System Design for Developers. Generous free tier.
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io 's 5-part learning path: Scalability and System Design for Developers. Generous free tier.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. Setup The setup consists of creating 10K tables with sysbench and adding 20 FKs to 20 tables.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
Manual flame graphs collection Although the tool is excellent and automatically provides flame graphs, we don’t have much control over tuning the selected profiler. A simple sysbench benchmark on MySQL shows an overhead between six and 10 percent on CPU-bound systems when running perf with the default sampling frequency of 4000 Hz.
This process thoroughly assesses factors like cost-effectiveness, security measures, control levels, scalability options, customization possibilities, performance standards, and availability expectations. Choosing the Right Cloud Services Choosing the right cloud services is crucial in developing an efficient multi cloud strategy.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Have you tuned your environment? This means they can ensure that every possible scenario is tested, from data integrity checks to performance benchmarks. Look for firms with a proven track record, positive client testimonials, and those that offer scalable solutions. What’s your plan to mitigate or minimize downtime?
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench.
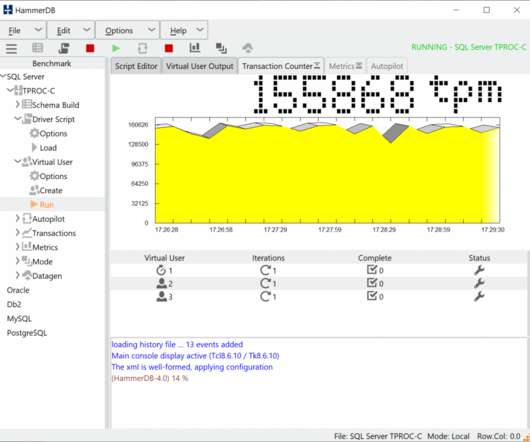
HammerDB is a load testing and benchmarking application for relational databases. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. Basic Benchmarking Concepts. Database benchmarking in parallel.
They came up with a horizontally scalable NoSQL database. Though still not “profitable” by many benchmarks, it’s a lot closer to being so, perhaps in a big way.) Some might say this marked the beginning of MongoDB’s “cloud push” escalation.) 2017: MongoDB goes public, trading as MDB.
That’s right; I’ve parked day-to-day design work in favor of becoming someone very active in the design community, focusing on best practice design advice and scalable systems. Stay tuned! I now find myself working as a Designer Advocate at Figma. We’re All Faking It. No one really knows what they are doing. I’d be happy to help!
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Quantitative performance testing looks at metrics like response time while qualitative testing is concerned with scalability, stability, and interoperability.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. This is to be expected and is due to the limitations of the scalability of the storage engine. HammerDB difference from Sysbench. perf special.
Enhanced Scalability : Partitioning enhances the database’s ability to scale, as data can be distributed across different storage devices. This helps identify potential issues and fine-tune the partitioning strategy. In summary, MySQL partitioning brings substantial advantages to both query performance and maintenance.
I became the Sun UK local specialist in performance and hardware, and as Sun transitioned from a desktop workstation company to sell high end multiprocessor servers I was helping customers find and fix scalability problems. This was followed by a greatly expanded second edition with some additional chapters by Rich Pettit.
He has a keen interest in web technologies, performance tuning, security, and the practical use of technology. Doug is a freelance mobile performance expert, a popular speaker – particularly on the topic of web tuning and image optimization – and the author of High Performance Android Apps. Doug Sillars. Doug Sillars.
However, the algorithm has been tuned and the resulting affect is minimal. For example, the I/O speed of a snapshot database could limit certain query scalabilities.
For highly scalable services, going outside of java process is costly, even to go to Memcache or Redis so we do in-memory cache with varying TTL for some highly used data structures like access control computation, feature flags, routing metadata etc. The dedicated Security team runs automated security benchmark tests before every release.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content