This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
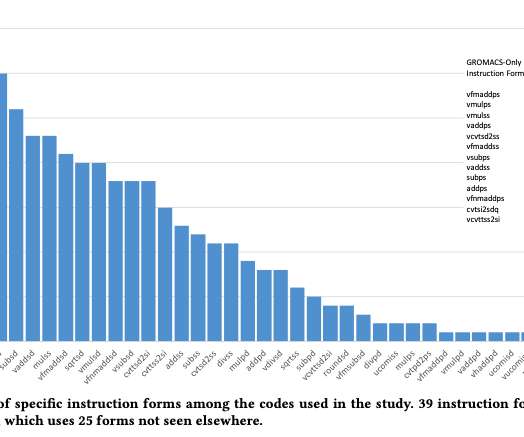
For the number of years I’ve been programming using Julia, I’ve never really been concerned with performance. Which is to say, I’ve appreciated that other people are interested in performance and have proven that Julia can be as fast as any other performance language out there.
Want your Go programs to run faster? In a previous article, we looked at How to compare strings in Go and did some benchmarking. Optimizing string comparisons in Go can improve your application’s response time and help scalability. We’re going to expand on that here.
In OpenMP® programs that take advantage of heterogenous parallelism, the master clause can be used to exploit simultaneous CPU and GPU execution. pomriq MRI reconstruction benchmark is written in C and parallelized using OpenMP. However, using the CPU and GPU resources simultaneously can improve the performance of an application.
This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language. Recently, I spent some time checking on the Performance (not a very detailed study) of the various programming languages.
MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. DigitalOcean.
Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role. Both systems continue to expand their client libraries , making them more accessible across different programming environments.
We also published our benchmarks for research purposes. The paper contains carefully crafted benchmarks, but I came up with a fun one for this blog post which I call “fizzbuzz” Let us go through all integers in sequence and count how many are divisible by 3 and how many are divisible by 5. It tells a nice story.
Improving each of these should hopefully chip away at the timings of more granular events that precede the LCP milestone, but whenever we’re making these kinds of indirect optimisation, we need to think much more carefully about how we measure and benchmark ourselves as we work. It’s vital to measure what you impact, not what you influence.
Introducing bpftop bpftop provides a dynamic real-time view of running eBPF programs. It displays the average execution runtime, events per second, and estimated total CPU % for each program. This tool minimizes overhead by enabling performance statistics only while it is active.
The inspiration (and title) for it comes from Mike Loukides’ Radar article on Real World Programming with ChatGPT , which shares a similar spirit of digging into the potential and limits of AI tools for more realistic end-to-end programming tasks. Setting the Stage: Who Am I and What Am I Trying to Build?
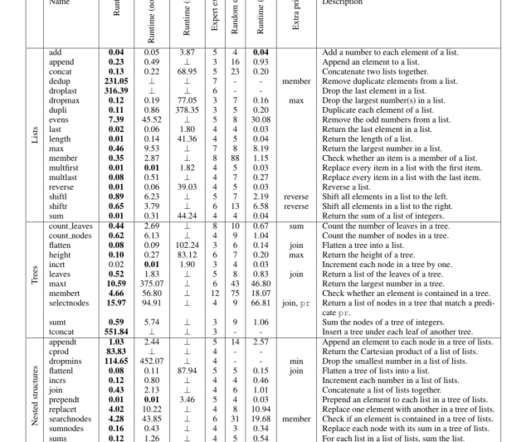
In the second approach, we show that a relatively simple, supervised sequential model (bidirectional LSTM or GRU) that uses rich, pretrained shot-level embeddings can outperform the current state-of-the-art baselines on our internal benchmarks. Figure 1: a scene consists of a sequence of shots.
And it covers more than just applications, application programming interfaces, and microservices. These include mobile, web, Internet of Things, and application programming interfaces. In today’s digital world, software is everywhere. Software is behind most of our human and business interactions. Digital experience.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle. This session looks at what it takes to accept, produce, encode, and stream your favorite content.
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. What programming languages does HammerDB use and why does it matter? Surely any language will do? Background and Concepts.
Pillar 2: ICT incident management Organizations will need a solid incident management program to meet incident reporting timeframes. Wherever possible, adopt solutions that automatically check for potential violations of DORA compliance requirements and industry benchmarks (such as the Center for Internet Security critical security controls).
The program advocates for a shift in behavior nationwide. This results in achieving a flawless OWASP benchmark score for injection attacks, ensuring 100% accuracy with no false positives. By leveraging code-level insights and transaction analysis, it can identify and prevent attacks without the need for manual configuration.
For questions regarding the process of registering or paying for Perform 2021 HOT, contact the Dynatrace University Program Team here. You’ll learn how to understand application usage patterns, infrastructure consumption, service dependencies, benchmarking performance and ensuring service levels, and enabling modern operations.
First, the company uses synthetic monitoring to develop user experience benchmarks and determine if applications are performing within expected thresholds. Cinema Experience lets users redeem vouchers for cinema tickets and is one of the company’s most popular programs. DEM in action.
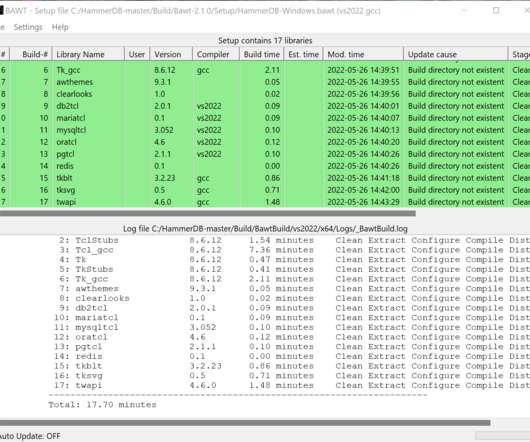
HammerDB is a load testing and benchmarking application for relational databases. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. This is why the choice of programming language is so important from the outset.
Five-nines availability: The ultimate benchmark of system availability. Such a solution with extensive application programming interfaces (APIs) and integrations to enterprise resource planning (ERP) systems make it possible to detect what was previously undetectable and initiate automatic remediation.
Querying the data While it is reasonable to create panels showing real-time load in order to explore better the types of queries that can be run against pg_stat_monitor, it is more practical to copy and query the data into tables after the benchmarking has completed its run. A script executing a benchmarking run: #!/bin/bash
To evaluate and benchmark our dataset, we manually labeled 20 audio tracks from various TV shows which do not overlap with our training data. Results We evaluated our models on four open datasets comprising audio data from TV programs, YouTube clips and various content such as concert, radio broadcasts, and low-fidelity folk music.
In fact, according to Stack Overflow’s annual developer survey , JavaScript and Python are now the #1 and #2 most used programming languages, respectively (excluding HTML/CSS and SQL as “programming languages”). But any time memory and application logic moves into Python land, it’s game over.
The study is conducted using a suite of 7 real-world popular scientific applications, and two well-established benchmark suites: Miniaero solves the compressible Navier-Stokes equation. PARSEC is a set of benchmarks for multi-threaded programs. is a set of benchmarks for parallel computing developed by NASA.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle. This session looks at what it takes to accept, produce, encode, and stream your favorite content.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle. This session looks at what it takes to accept, produce, encode, and stream your favorite content.
In this article, we’ll briefly outline the use-case for a library like Donkey and present our benchmarks. Donkey is the product of the quest for a highly performant Clojure HTTP stack aimed to scale at the rapid pace of growth we have been experiencing at AppsFlyer, and save us computing costs. By Yaron Elyashiv.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
Being static , it has the advantage that analysis results can be produced solely from source code without the need to execute the program. But there’s a problem: Enterprise applications represent a major failure of applying programming languages research to the real world — a black eye of the research community. JackEE in action.
Systems researchers are doing an excellent job improving the performance of 5-year old benchmarks, but gradually making it harder to explore innovative machine learning research ideas. Challenges optimising whole programs. “ Challenges evolving programming languages. “ Challenges evolving programming languages.
Netflix engineers run a series of tests and benchmarks to validate the device across multiple dimensions including compatibility of the device with the Netflix SDK, device performance, audio-video playback quality, license handling, encryption and security. Detect a regression in a test case.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. It depends upon your application workload and its business logic.
HammerDB is a software application for database benchmarking. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here.
While working on the implementation of the MPI version of the STREAM benchmark, I realized that there were some subtleties in timing that could easily lead to inaccurate and/or misleading results.
While working on the implementation of the MPI version of the STREAM benchmark, I realized that there were some subtleties in timing that could easily lead to inaccurate and/or misleading results.
Though still not “profitable” by many benchmarks, it’s a lot closer to being so, perhaps in a big way.) That early decision was notable because whereas the GPL is applied if derivative work is distributed, the AGPL license applies both for distributed work and whenever end users interact with a program over a network.
These techniques work well for scientific programs that are dominated by arrays. However, they are ineffective on object-based programs because objects do not fall neatly into fixed-size blocks and have a more irregular layout. Consider a B-Tree node from the B-tree Java benchmark: Uncompressed, it’s memory layout looks like (a) below.
If you are not already familiar with the programming languages that HammerDB uses, then this earlier post serves as an ideal introduction to what makes up the highest performing GIL free database benchmarking application. What programming languages does HammerDB use and why does it matter? WHY build from source?
A friend called out to me a peculiar feature of a conference Program Committee they were serving on: that it was part of the PC’s role to keep a look out for strong minority/female speakers and encourage them to submit to the open CFP. But on we plod.
In the table below, the numbers in each column represent the number of test programs , not the number of individual tests. Most programs (almost 800 C programs in the FreeBSD source tree) require no modifications. For a macro-benchmark PostgreSQL’s initdb tool was used. slower to 9.8% faster for system calls).
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. Provides support for "unread counts", e.g. for email and chat programs.
Depending on the application programming language, which is specified as an argument in the command line, the tool launches a compatible image profiler that contains everything it needs to successfully produce the flame graph. In secure environments where policies are defined, launching such a pod should be done by a trusted privileged user.
The Programmatically Interpretable Reinforcement Learning paper that we looked at last time out contained this passing comment coupled with a link to today’s paper choice: It is known from prior work that such [functional] languages offer natural advantages in program synthesis. That certainly caught my interest. High-level approach.
Was there some other program consuming CPU, like a misbehaving Ubuntu service that wasn't in CentOS? I love short benchmarks like this as I can disassemble the resulting binary and ensure that the compiled instructions match my expectations, and the compiler hasen't messed with it. ## 6. include <sys/time.h>
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











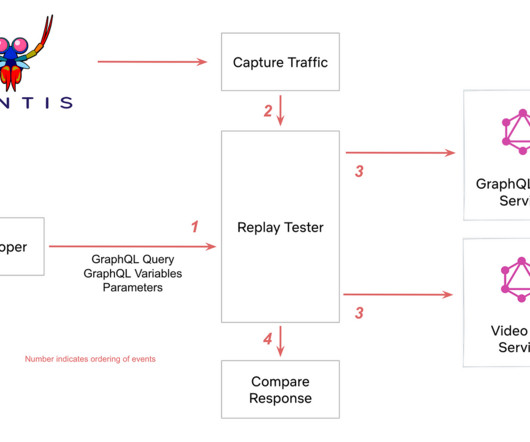


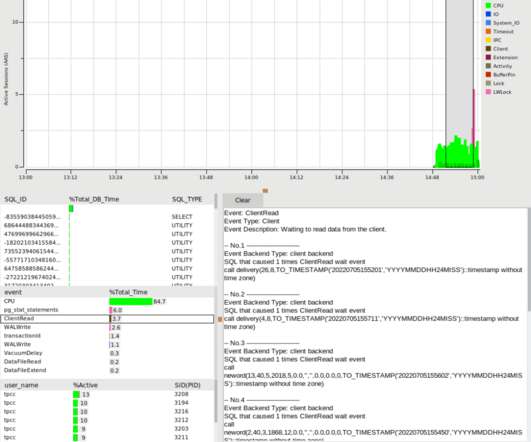




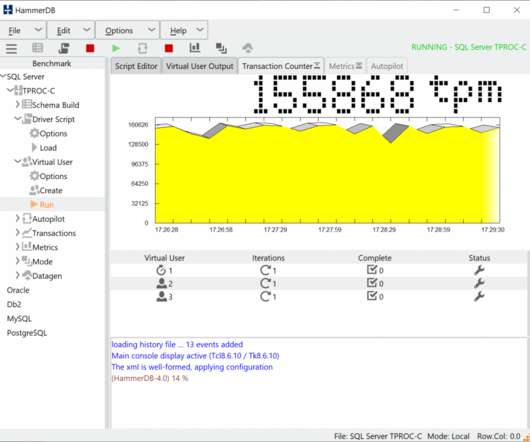


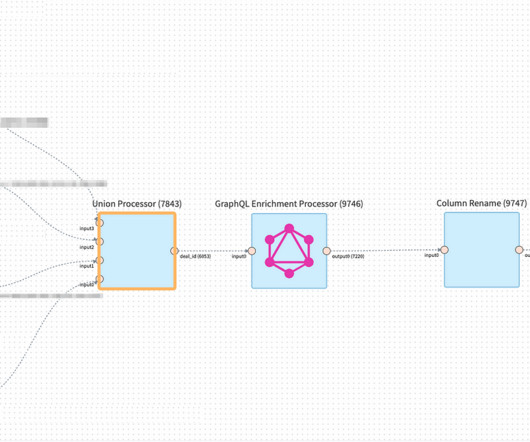























Let's personalize your content