This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
We measure PostgreSQL throughput in terms of transactions processed. Throughput in general is the rate at which something is processed, and in terms of PostgreSQL, this is the number of transactions per second (TPS) your application can handle. PostgreSQL Benchmark Setup. Benchmark Tool. Throughput. PostgreSQL Version.
As more organizations respond to the pressure to release better software faster, there is an increasing need to build quality gates into every stage of BizDevOps processes , from early development to deployment. Automating quality gates creates reliable checks and balances and speeds up the process by avoiding manual intervention.
Whether it’s optimizing algorithms or fine-tuning data structures, every decision we make can have a significant impact on the overall performance of our applications. As software engineers, we are always striving for high performance and efficiency in our code.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. The checkpoint process flushes the data into the data files. wal_buffers. Conclusion.
Synthetic clickpath monitors are a great way to automatically monitor and benchmark business-critical workflows 24/7. Some common examples of such business-critical workflows include: Sign-up processes. Soon, HTTP monitors will also be able to execute JavaScript, so stay tuned! Dynatrace news. Checking out of a retail site.
User provides a sample image to find other similar images Prior engineering work Approach #1: on-demand batch processing Our first approach to surface these innovations was a tool to trigger these algorithms on-demand and on a per-show basis. Processing took several hours to complete. Some ML algorithms are computationally intensive.
“We were able to … fine-tune our systems in a very performant way,” notes Hood. He and his team thought, “Why can’t these issues be solved autonomously with a platform that has information about these processes?” “Our brain, the source of that knowledge, was the information coming from Dynatrace.”
It is better to consider refactoring as part of the application transformation process before migrating, if possible. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices. Repeat this process throughout the different environments before development, staging, release, and production.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? To be fair, that is also true with PostgreSQL; it hasn’t been tuned either, and it, too, can also perform much better.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. of PostgreSQL users are currently in the process of migrating to the RDBMS, according to the 2019 PostgreSQL Trends Report , an astounding percentage considering this is the 4th most popular database in the world.
In theory, an existing code module or agent can be used to monitor a Lambda function if there’s a way to load it into the running Lambda process. When we set out to create the new Lambda extension, we benchmarked other dedicated Lambda monitoring solutions that were already on the market. Stay tuned?for functionality?in
While these niche products were mostly building upon AWS CloudWatch and Xray, their agents were rather limited as running an agent in process with a Lambda function comes with some challenges. These served as our benchmark when creating our Lambda monitoring extension. So, stay tuned for more blog posts and announcements.
While these niche products were mostly building upon AWS CloudWatch and Xray, their agents were rather limited as running an agent in process with a Lambda function comes with some challenges. These served as our benchmark when creating our Lambda monitoring extension. So, stay tuned for more blog posts and announcements.
Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. The process started with manual pull of member account information that was part of the session.
Evaluation : How do we evaluate such systems, especially when outputs are qualitative, subjective, or hard to benchmark? In AI systems, evaluation and monitoring dont come lastthey drive the build process from day one FIRST EVAL HARNESS Evaluation must move beyond vibes: A structured, reproducible harness lets you compare changes reliably.
Perhaps the most interesting lesson/reminder is this: it takes a lot of effort to tune a Linux kernel. Google’s data center kernel is carefully performance tuned for their workloads. A micro-benchmark suite, LEBench was then built around tee system calls responsible for most of the time spent in the kernel. Headline results.
About the cluster Following a step-by-step process, the objective is to create a four-node cluster consisting of: PostgreSQL version 15 Citus extension (I’ll be using version 11, but there are newer ones available.) In order to speed up the benchmark indexes must be added. psql pgbench <<_eof1_ qecho adding node citus3.
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operating systems almost always process each call (e.g., GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here. Stay tuned!
As datasets continue to grow in size, the amount of RAM required to store and process these datasets also increases. Benchmark before you decide. But also larger log files mean that the recovery process will be slower in case of a crash. If you see concurrency issues, you can tune this variable. I hope this helps!
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. This plays a crucial role in supervising the replication process.
The kubectl-flame container has the hostPID option enabled, and this provides visibility of the underlying Kubernetes node process ID namespace to collect system events from running processes on the host. In the following example, we’ll see how to manually run perf on a mysqld process inside a Kubernetes pod.
We decided to run a few benchmarks to understand how the thread pool affects long-running transactions. This server is not intended to be a perfectly tuned one but just a baseline to compare the behavior under different concurrency configurations. For this reason, I’ve set up a server with the following specs: r6a.2xlarge
Some of these examples have been hand-tuned to make them efficient for TLC to check, no such tuning is done for APALACHE. 4 seconds on this same benchmark). We hope that with the growing number of users, specifications will get tuned to our model checker, as is now happening with TLC. But when TLC starts to struggle (e.g.,
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Application security products and processes, however, have not kept up with advances in software development. Bridgecrew is the cloud security platform for developers. Try it today!
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Application security products and processes, however, have not kept up with advances in software development. Bridgecrew is the cloud security platform for developers. Try it today!
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Application security products and processes, however, have not kept up with advances in software development. Bridgecrew is the cloud security platform for developers. Try it today!
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Application security products and processes, however, have not kept up with advances in software development. Bridgecrew is the cloud security platform for developers. Try it today!
Have you tuned your environment? Testing made easy An equally critical aspect of the database migration process is testing the migrated database to ensure everything will function correctly and no data will be lost or corrupted. How long does the migration process take with a third party? Have you built a testing environment?
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
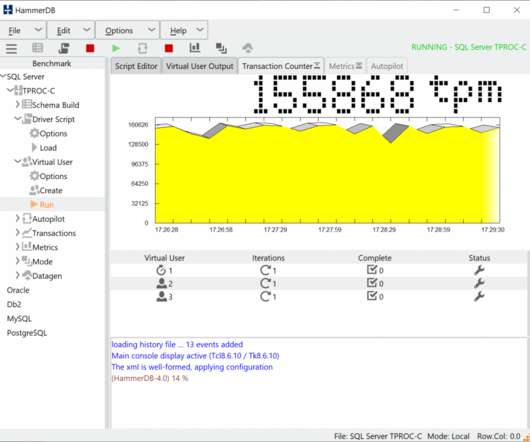
HammerDB is a load testing and benchmarking application for relational databases. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. Basic Benchmarking Concepts. To benchmark a database we introduce the concept of a Virtual User.
Crafting Your Multi-Cloud Blueprint Formulating a comprehensive multi-cloud framework is an intricate process that requires a business’s specific requirements, choosing suitable cloud services, and optimizing for performance and affordability. Getting security right in a multi-cloud setup means doing a few key things.
What about short-lived processes, like a service restarting in a loop? I love short benchmarks like this as I can disassemble the resulting binary and ensure that the compiled instructions match my expectations, and the compiler hasen't messed with it. ## 6. top(1) showed that only the Cassandra database was consuming CPU.
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . A good example of how tuning is an iterative process. This wait by the session is what is typically seen as a log wait. Checkpoint not complete.
Compression: Compression is the process of restructuring the data by changing its encoding in order to store it in fewer bytes. 1 mysql mysql 592K Dec 30 02:48 tb1.ibd ibd -rw-r --. 1 mysql mysql 464K Dec 30 02:48 tb2.ibd ibd -rw-r --. 1 mysql mysql 464K Dec 30 02:48 tb3.ibd ibd -rw-r --. 1 mysql mysql 464K Dec 30 02:48 tb4.ibd
Though still not “profitable” by many benchmarks, it’s a lot closer to being so, perhaps in a big way.) and partners) and in the process, stifling the upstarts, the truly open source little folks dreaming big. (Some might say this marked the beginning of MongoDB’s “cloud push” escalation.)
With entrance into the industry being so easy and lack of proper benchmarking (Note: this is somewhat contradictory to point 2, but more on that later) around what makes a good designer, software engineer, or product manager, we’re forced to face the facts that it’s a recipe for poor quality products. Stay tuned! Show it off.
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operating systems almost always process each call (e.g., GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here. Stay tuned!
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content