This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more.
This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. This extension was built from scratch to take into account all we’ve learned and the special requirements for monitoring ephemeral, auto-scaling, micro VMs like AWS Lambda. The virtual CPU is turned off.
And we know as well as anyone: the need for fast transformations drives amazing flexibility and innovation, which is why we took Perform Hands-on Training (HOT) virtual for 2021. Here’s what’s new this year, and how you can get a front-row seat in our virtual classroom. More flexibility, more options. The Dynatrace University Team.
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. Many good security tools provide that function, and benchmarks from the Center for Internet Security (CIS) are clear and prescriptive. Why is container security tricky?
Intelligent software automation can give organizations a competitive edge by analyzing historical and compute workload data in real time to automatically provision and deprovision virtual machines and Kubernetes. The core benefits of an AIOps-automated software analytics platform include the following: Infrastructure monitoring.
In consideration of this reality, The Dynatrace Lambda monitoring extension supports all well-known IaC technologies to deploy Dynatrace along with your function. Today, Lambda can be monitored by Dynatrace in hybrid environments, thereby satisfying the enterprise requirements. This is where monitoring requirements come into play.
In consideration of this reality, The Dynatrace Lambda monitoring extension supports all well-known IaC technologies to deploy Dynatrace along with your function. Today, Lambda can be monitored by Dynatrace in hybrid environments, thereby satisfying the enterprise requirements. This is where monitoring requirements come into play.
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. We use stored procedures because, as the introductory post shows, using single SQL statements turns our database benchmark into a network test).
2022 was an exciting year for Percona Monitoring and Management (PMM). Planning for resources of a PMM Server host instance can be tricky because the numbers can change depending on the DB instances being monitored by PMM. Virtual Memory utilization was averaging 48 GB of RAM. We have tested PMM version 2.33.0
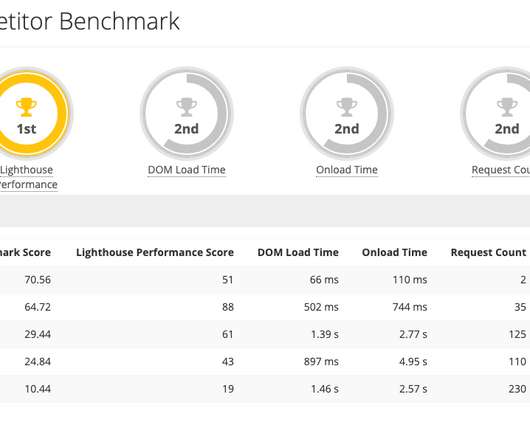
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31
Reading time 8 min There are many different classes of web performance tools, from synthetic monitoring to application performance monitoring ( APM) , to real user monitoring ( RUM ), and more. Is it a physical system or virtual? If virtualized, what is the technology used (VM, Docker, software package)?
Various forms can take shape when discussing workloads within the realm of cloud computing environments – examples include order management databases, collaboration tools, videoconferencing systems, virtual desktops, and disaster recovery mechanisms. This applies to both virtual machines and container-based deployments.
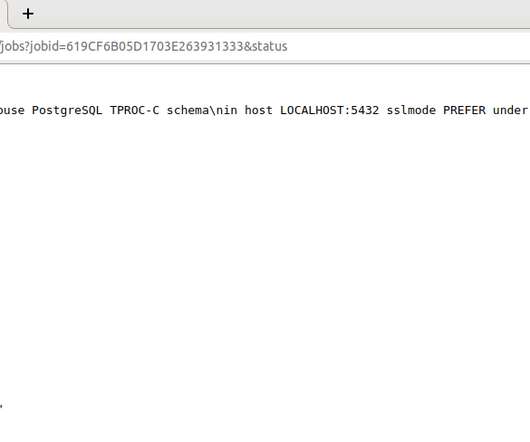
this web interface has been enhanced to add command line functionality to the service as well as extending the ability to query the database of configuration, results and timing data to be returned in JSON format, enabling a long-term repository of HammerDB benchmark data for integrating HammerDB into service based cloud environments.
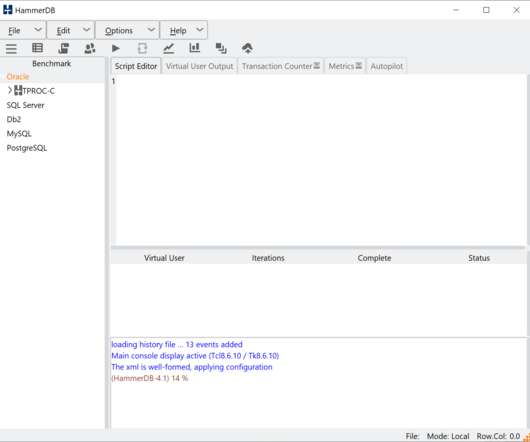
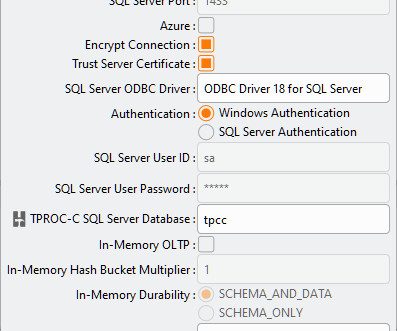
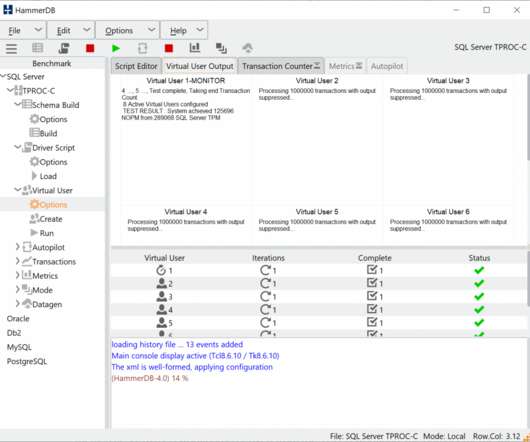
This will show the benchmark options dialog. Benchmark Options. and benchmark set with the bm argument. In the example below we have modified the SQL Server, number of warehouses to build and the virtual users to build them. A key aspect is being able to visualise the multithreaded nature of the Virtual Users.
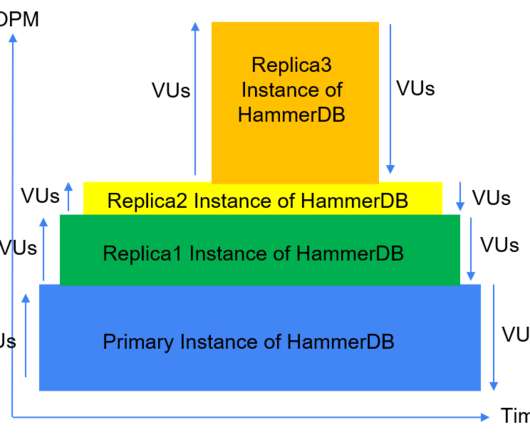
Typically, the servers are configured in a primary/replica configuration, with one server designated as the primary server that handles all incoming requests and the others designated as replica servers that monitor the primary and take over its workload if it fails. there cannot be high availability.
It will create the number of virtual users to the number of CPUs on the system where HammerDB is running. using existing tables (188,416 KB) SETTING CONFIGURATION Database set to MariaDB Benchmark set to TPC-C for MariaDB. scripts/tcl/maria/tprocc/maria_tprocc.sh TMP/hammer.DB TMP/hammer.DB TMP/hammer.DB TMP/hammer.DB TMP/hammer.DB
This is an important consideration that is often missed, so although it seems obvious, it is worth reiterating that benchmarking applications are not typically designed to be disconnected and the database restarted whilst the workload is running. When you create the virtual users, you can see the iterations value in the central panel.
BCP based load Now when we select the “Use BCP Option” We can see that we are now using an insert bulk command (although the item table being fixed at 100K rows and loaded by the monitorvirtual user continues to use regular inserts). We thank @krithikasatish and @JoshInnis for this excellent contribution to HammerDB.
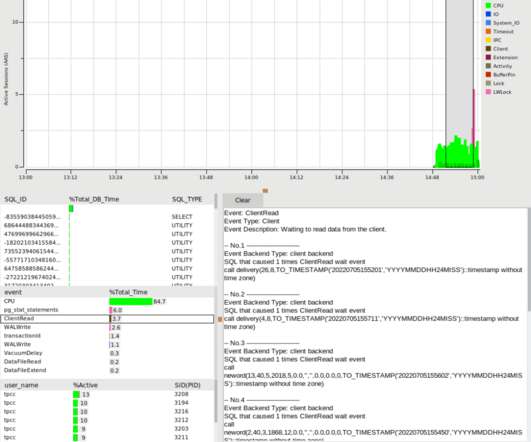
This enables the user to compare and contrast performance across different benchmark scenarios. By clicking on the Metrics Display option, HammerDB will connect to the target database and start monitoring the performance, note that if the pg_active_session_history table is empty the viewer will report an error and refuse to start.
and the test will run with the number of Virtual Users equivalent to the number of CPUs. Benchmark set to TPC-C for MariaDB. Building 20 Warehouses with 5 Virtual Users, 4 active + 1 Monitor VU(dict value maria_num_vu is set to 4). Vuser 1:Monitor Thread. Vuser 2:Waiting for Monitor Thread. vuset vu vcpu.
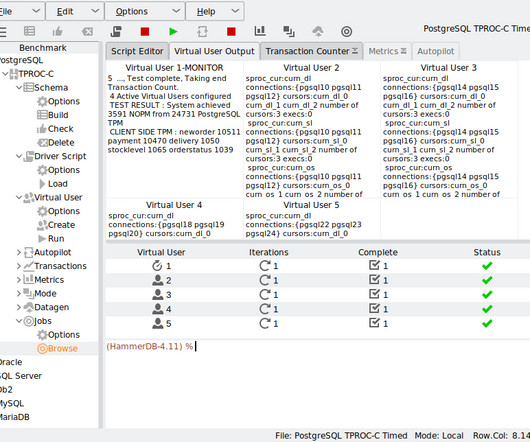
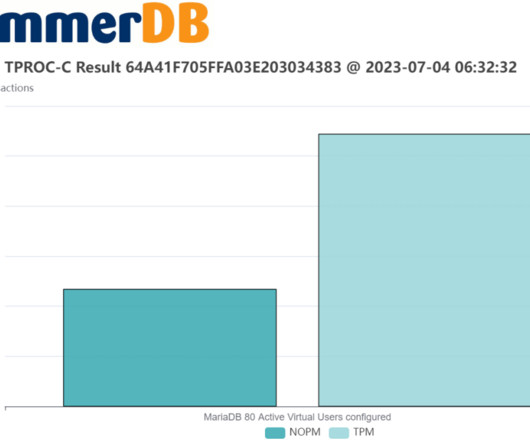
Copy Code Copied Use a different Browser Vuser 1:80 Active Virtual Users configured Vuser 1:TEST RESULT : System achieved 701702 NOPM from 1631827 MariaDB TPM Fixing throughput with keying and thinking time The key concept to understanding fixed throughput is that of keying and thinking time.
scripts/tcl/maria/tprocc/maria_tprocc_run.tcl Comparing the results When running the 80 thread sysbench-tpcc workload, monitoring with HammerDB we can see the following output. Summary Of course the more benchmarks and workloads you run against a system, the more insights you can get. Copy Code Copied Use a different Browser./tpcc.lua
It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based. Enterprise environments are monitored, continuously profiled, and analyzed on a regular basis, so this capability will indeed be put to use.
For querying a build, the status command will show whether all Virtual Users started and finished successfully, allowing a quick way to check the status of a build. . By default the summary timings are reported, however by adding the vuid you can also drill down into the timings for a specific virtual user. Use a different Browser.
The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint. more transactions than system B in the fully audited benchmark then the HammerDB result was also 1.5X I.e. if system A generated 1.5X
When taking this approach you would not focus on the test result but instead monitor the databases ability to cope with the variation in demand and transaction response times. Note that it is expected for Virtual User 1 of the replicas to end immediately with the message. Step Workloads. To implement Step Workloads, HammerDB v4.1
/restchk.tcl TEST DIRECT PRINT COMMANDS -- Printing output for db and converting JSON to text JSON format { "ora": "Oracle", "mssqls": "MSSQLServer", "db2": "Db2", "mysql": "MySQL", "pg": "PostgreSQL", "redis": "Redis" } TEXT format ora Oracle mssqls MSSQLServer db2 Db2 mysql MySQL pg PostgreSQL redis Redis Printing output for bm and converting JSON (..)
Vuser 1:1 Active Virtual Users configured Vuser 1:TEST RESULT : System achieved 39945 NOPM from 92893 SQL Server TPM Vuser 1:Gathering timing data from Active Virtual Users. Running this script returns output as follows using the Python loop to drive HammerDB. Vuser 2:FINISHED SUCCESS Vuser 1:Calculating timings.
I then analyzed performance during the benchmark ([active benchmarking]), and used other benchmarks to confirm findings. To understand the overhead further I'll need to use instruction-level profiling, such as by using perf annotate, and PMC (Performance Monitoring Counter) analysis of the CPU cycles (more on this later). ## 2.
<benchmark> <first_result>TPM</first_result> </benchmark> So why not just print NOPM and report a single metric for TPROC-C as per the official TPC-C workloads? Similarly for SQL Server TPM records Batches/sec which is the same value seen in the Activity Monitor in SSMS. Activity Monitor.
Containerized data workloads running on Kubernetes offer several advantages over traditional virtual machine/bare metal based data workloads including but not limited to. support for logging, monitoring, and observability. In fact, if we go by current trends containerised microservices running on Kubernetes are the future.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Failure detection: Monitoring mechanisms detect failures or issues that could lead to failures. there cannot be high availability.
The spread of where consumers want to consume content, at home, at the office, at the gym, on a plane, at any time where there is connectivity, puts significant pressure on the network and performance monitoring teams for streaming brands. Load and stress-testing benchmark goals for the backend technological components.
We’ll note how some of the Linux parameter settings used OS tuning may vary according to different system types: physical, virtual or cloud. In this benchmark, I discovered some interesting discrepancies in performance between AMD and Intel CPUs when running under systemd. A Look at MyRocks Performance.
This article Threads Done Right… With Tcl gives an excellent overview of these capabilities and it should be clear that to build a scalable benchmarking tool this thread performance and scalability is key. As virtual users are started the database specific packages and workload specific modules are loaded into the virtual user threads.
And today, we still have type in a digital context, but it travels through cables, wirelessly on smartphones, and in virtual reality glasses in 3D. In addition, typefaces can be more or less legible on different screens and monitor resolutions because they can be rendered with varying degrees of quality and sharpness.
Monitoring and Profiling : Continuously monitor trigger performance to identify and address slow-performing triggers promptly. Testing and Benchmarking : Thoroughly test triggers in a staging environment to evaluate their impact on performance. Benchmark different trigger implementations to identify the most efficient option.
Teams looking to grow past Level 1 develop (or uncover they already had) Real User Monitoring (" RUM data") infrastructure in previous cycles. This also requires an investment in infrastructure and continuous monitoring. Browsers provide a lot of data about site performance. Nothing is more depressing than managerial cosplay.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. monitoring. Error in Virtual User 1: mysqlexec/db server: Table 'mysql.proc' doesn't exist. Vuser 1:56 Active Virtual Users configured.
I then analyzed performance during the benchmark ([active benchmarking]), and used other benchmarks to confirm findings. To understand the overhead further I'll need to use instruction-level profiling, such as by using perf annotate, and PMC (Performance Monitoring Counter) analysis of the CPU cycles (more on this later). ## 2.
Another big jump, but now it was my job to run benchmarks in the lab, and write white papers that explained the new products to the world, as they were launched. I was mostly coding in C, tuning FORTRAN, and when I needed to do a lot of data analysis of benchmark results used the S-PLUS statistics language, that is the predecessor to R.
This guide has been kindly supported by our friends at LogRocket , a service that combines frontend performance monitoring , session replay, and product analytics to help you build better customer experiences. Good for raising alarms and monitoring changes over time, not so good for understanding user experience. Vitaly Friedman.
Latch enforcement changes the virtual memory protection ( VirtualProtect ) as the database pages are transitioned between the clean and dirty states.
To efficiently utilize our compute resources, Titus employs a CPU oversubscription feature , meaning the combined virtual CPUs allocated to containers exceed the number of available physical CPUs on a Titus agent. You will notice a do-while loop that is linear to the virtual memory area.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content