This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. Instead, they can ensure that services comport with the pre-established benchmarks. This process includes benchmarking realistic SLO targets based on statistical and probabilistic analysis from Dynatrace.
However, performance can decline under high traffic conditions. Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role. Low-Latency Messaging Both Kafka and RabbitMQ are capable of low-latency messaging but use different approaches.
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Real user monitoring limitations.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
Dynatrace offers various out-of-the-box features and applications to provide a high-density overview of system health for all hosts and related metrics in a single view. Foundation and Discovery provide essential metrics and topology discovery, making it useful to quickly identify and recover affected hosts. Before a crisis.
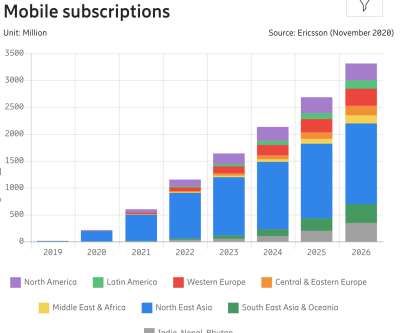
65% of businesses report that 40% of their customers now engage with them through mobile devices , and 70% of digital businesses will require IT and Ops to report digital metrics by 2025. First, the company uses synthetic monitoring to develop user experience benchmarks and determine if applications are performing within expected thresholds.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. Five-nines availability: The ultimate benchmark of system availability. The nirvana state of system uptime at peak loads is known as “five-nines availability.”
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
We took a hybrid head-based sampling approach that allows for recording 100% of traces for a specific and configurable set of requests, while continuing to randomly sample traffic per the policy set at ingestion point. This allowed us to increase total storage capacity without adding a new Cassandra node to the existing cluster.
These days, with mobile traffic accounting for over 50% of web traffic , it’s fair to assume that the very first encounter of your prospect customers with your brand will happen on a mobile device. However, there are quite a few high-profile case studies exploring the impact of mobile optimization on key business metrics.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. That said, it should also be monitored for usage, which will exhibit the traffic pressuring them. This is not an exhaustive list but an example of what we can watch for.
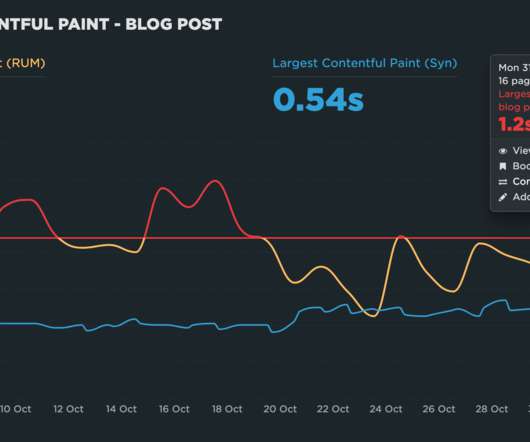
"I made my pages faster, but my business and user engagement metrics didn't change. The performance poverty line is the plateau at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
As an ad publisher, your revenue depends on two main factors: traffic to your site and ad optimization. A lot of the focus goes into the practice and processes of driving traffic to your site from an SEO perspective, but what if when visitors get to your site, they have a less than ideal experience? Dotcom-Monitor Website Monitoring.
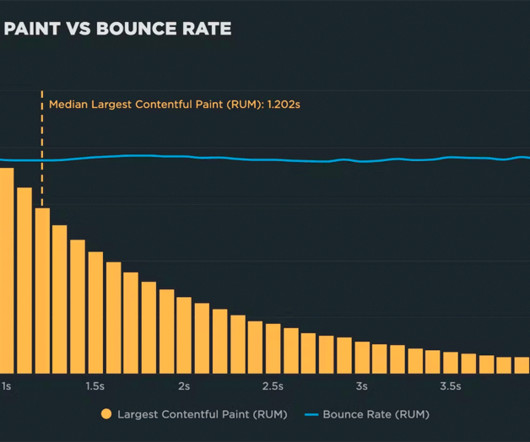
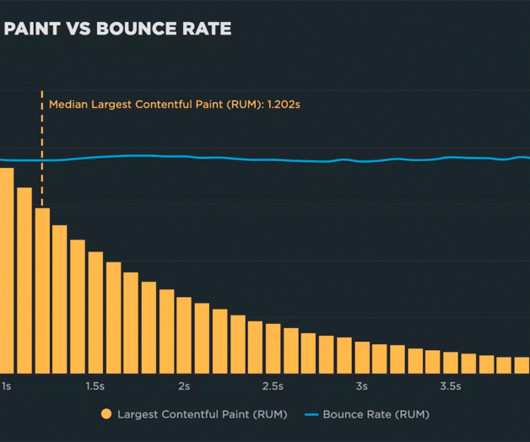
The best way to fight regressions is to create performance budgets on key metrics, and get alerted when they go out of bounds. These charts let even the most non-technical stakeholder easily see the correlation between performance and user engagement and business metrics, such as bounce rate and conversion rate.
Load balancing : Traffic is distributed across multiple servers to prevent any one component from becoming overloaded. Load balancers can detect when a component is not responding and put traffic redirection in motion. If a server fails, the load balancer redirects traffic to a replicated server in another cluster.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
However, that pesky 20% on the back end can have a big impact on downstream metrics like First Contentful Paint (FCP), Largest Contentful Paint (LCP), and any other 'loading' metric you can think of. See this guide to learn how you can define custom dimension data, metadata, or metric (timing, size, numeric).
You can see at a glance: Key metrics like Core Web Vitals and your User Happiness score. Your current competitive benchmarks status. Here you can still find time series charts that show how performance is trending over time across a number of key metrics, including Core Web Vitals. Expanded Industry Speed Benchmarks.
Page labels give you the ability to: Compare and benchmark similar pages across different sites. Compare and benchmark similar pages across different sites. Benchmark key pages against those of your competitors. Benchmark Dashboard from SpeedCurve. Why should I care about page labels? How do page labels help me?
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Quantitative performance testing looks at metrics like response time while qualitative testing is concerned with scalability, stability, and interoperability.
They can also highlight very long redirection chains in your third-party traffic. Researchers and major companies have been publishing case studies for years , proving that slower page load experiences impact business metrics, including conversion rate, revenue, bounce rate, and more. Design Optimizations.
Budgets are scaled to a benchmark network & device. This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made. Very rarely have we seen a team succeed that doesn’t set budgets, gather RUM metrics, and carry representative customer devices.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
Teams I've consulted are too often wrenched between celebration over "the big rewrite" launch and the morning-after realisation that the new stack is tanking business metrics. Competent managers will begin to look for more general "industry standard" baseline metrics to report against their data. Photo by Jay Heike.
"I made my pages faster, but my business and user engagement metrics didn't change. The performance plateau is the point at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
search traffic. Over the years, I've learned that performance can be mapped to all of these metrics – and almost any other business metric you can think of. To hook different people on performance, you need to understand which metric motivates them. conversions. time on site. page views. user satisfaction.
Key metrics such as CPU usage, memory usage, and disk I/O offer insights into how efficiently your database server operates. By analyzing disk I/O metrics, you can optimize queries to reduce disk reads or upgrade to faster storage solutions. Next, take a look at your metrics for the InnoDB Log File usage.
Vertical scaling allows for increases in the compute and memory capacity via upgrades to larger instance types, ideal for handling traffic demands or processing needs, while horizontal scaling involves adding read replicas to distribute workloads across multiple instances, enhancing read scalability for read-heavy applications.
Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. Tracing as a foundation Logs, metrics, and traces are the three pillars of observability. Telltale provides Edgar with latency benchmarks that indicate if the individual trace’s latency is abnormal for this given service.
The scale of the effect can be deeply situational or hard to suss out without solid metrics. Since then, the metrics conversation has moved forward significantly, culminating in Core Web Vitals , reported via the Chrome User Experience Report to reflect the real-world experiences of users. Today, either method returns a similar answer.
LogRocket tracks key metrics, incl. Getting Ready: Planning And Metrics Performance culture, Core Web Vitals, performance profiles, CrUX, Lighthouse, FID, TTI, CLS, devices. Getting Ready: Planning And Metrics. DOM complete, time to first byte, first input delay, client CPU and memory usage. Get a free trial of LogRocket today.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study, or a proof of concept using the Performance API on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Quick Wins.
Blame The Notebook Now that we have an objective metric for the slowness, let’s officially start our investigation. However, when we captured packets on the ZeroMQ socket while reproducing the issue, we didn’t observe heavy traffic on this socket that could cause such blocking. We then exported the .har
Make sure you’re tracking the right metrics Think beyond Core Web Vitals. In fact, for a lot of customers, iOS traffic – which Vitals can't track – is the most popular and has higher conversion rates. Consider adding custom metrics. Third parties can hurt important metrics, like Core Web Vitals.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content