This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
I can reload the exact same page under the exact same network conditions over and over, and I can guarantee I will not get the exact same, say, DOMContentLoaded each time. As noted above, it’s not actually possible to improve certain metrics in their own right. There are myriad reasons for this that I won’t cover here. duration ).
Here are some common questions I’m asked when I talk with people about performance: Which metrics should I care about? What are some good sites I can use for benchmarking? With Page Speed Benchmarks, you can do things like: See what the different metrics actually mean in terms of user-perceived performance.
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. Align business and development teams’ input on what user experience metrics to measure to understand users’ most critical digital experience aspects.
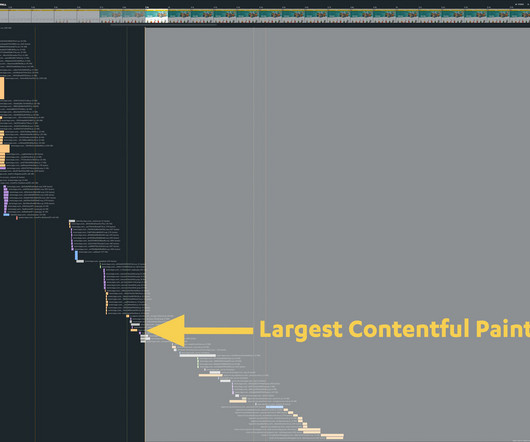
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role.
To function effectively, containers need to be able to communicate with each other and with network services. If containers are run with privileged flags, or if they receive details about host processes, they can easily become points of compromise for corporate networks. Network scanners. Why is container security tricky?
This is a potential cause for concern for anyone who cares about metrics like Largest Contentful Paint, which measures the largest visual element on a page – including videos. Given that Google continues to dominate search usage, you should care about Vitals alongside the other metrics you should be tracking. More on that below.)
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. for unplanned downtime, resource saturation, network intrusion. AI-assistance: Use AI to detect anomalies and benchmark your system. Dynatrace news.
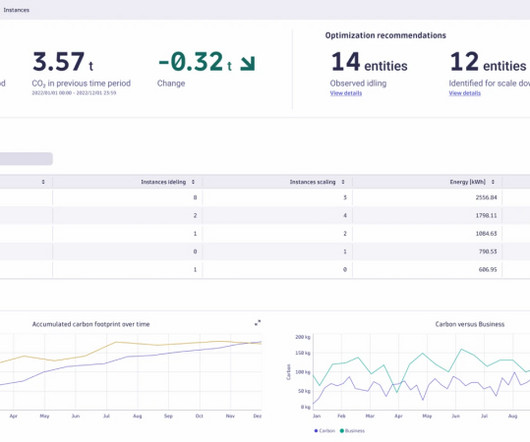
The app’s advanced algorithms and real-time data analytics translate utilization metrics into their CO2 equivalent (CO2e). These metrics include CPU, memory, disk, and network I/O. Using Carbon Impact, we can now implement efficiency measures driven by the app’s benchmarks and recommendations.
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Real user monitoring limitations.
In this session, we discuss the technologies used to run a global streaming company, growing at scale, billions of metrics, benefits of chaos in production, and how culture affects your velocity and uptime. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle.
Five-nines availability: The ultimate benchmark of system availability. Instead, to speed up response times, applications are now processing most data at the network’s perimeter, closest to the data’s origin. But is five nines availability attainable? Each decimal point closer to 100 equals higher uptime.
Dynatrace offers various out-of-the-box features and applications to provide a high-density overview of system health for all hosts and related metrics in a single view. Foundation and Discovery provide essential metrics and topology discovery, making it useful to quickly identify and recover affected hosts. Before a crisis.
What do the different metrics mean? While the focus in most cases tends to be directed toward front-end developers, it's important to remember the back-end as well if you see higher than normal start render times or increases in more basic metrics like time to first byte. What do the different metrics mean? Let's get started.
This PoC demonstrates how to install and configure pg_stat_monitor in order to extract useful and actionable metrics from a PostgreSQL database and display them on a Grafana dashboard. This allows for much better data accuracy, especially in the case of high-resolution or unreliable networks.
It can be measured based on real data from users visiting your sites ( field metric ) or in a lab environment ( lab metric ). In fact, several user-centric metrics are used to quantify web vitals. While most of the tools covered below only rely on field metrics, others use a mix of both field and lab metrics.
Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. The process started with manual pull of member account information that was part of the session.
But pages keep getting bigger and more complex year over year – and this increasing size and complexity is not fully mitigated by faster devices and networks, or by our hard-working browsers. How does page bloat affect other metrics, such as Google's Core Web Vitals? Clearly we need to keep talking about it.
Netflix engineers run a series of tests and benchmarks to validate the device across multiple dimensions including compatibility of the device with the Netflix SDK, device performance, audio-video playback quality, license handling, encryption and security. The neural network (NN)-based agent uses a deep net with fully connected layers.
Tracing as a foundation Logs, metrics, and traces are the three pillars of observability. Metrics communicate what’s happening on a macro scale, traces illustrate the ecosystem of an isolated request, and the logs provide a detail-rich snapshot into what happened within a service. starting and finishing a method).
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
four petabytes : added to Internet Archive per year; 60,000 : patents donated by Microsoft to the Open Invention Network; 30 million : DuckDuckGo daily searches; 5 seconds : Google+ session length; 1 trillion : ARM device goal; $40B : Softbank investment in 5G; 30 : Happy Birthday IRC!; They'll love it and you'll be their hero forever.
Thanks to progress in networks and browsers (but not devices), a more generous global budget cap has emerged for sites constructed the "modern" way: ~100KiB of HTML/CSS/fonts and ~300-350KiB of JS (compressed) is the new rule-of-thumb limit for at least the next year or two. Modern network performance and availability.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. Replication lag can occur due to various factors such as network latency, system resource limitations, complex transactions, or heavy write loads on the primary/master database.
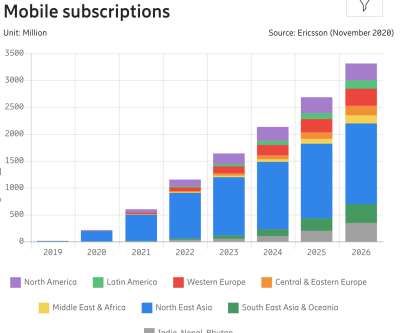
The gotcha here is that, if your mobile experience isn’t optimized for various devices and network conditions, these customers will never appear in your analytics — just because your website or app will be barely usable on their devices, and so they are unlikely to return. Driving Business Metrics. billion by 2026. Large preview ).
In this session, we discuss the technologies used to run a global streaming company, growing at scale, billions of metrics, benefits of chaos in production, and how culture affects your velocity and uptime. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle.
In this session, we discuss the technologies used to run a global streaming company, growing at scale, billions of metrics, benefits of chaos in production, and how culture affects your velocity and uptime. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle.
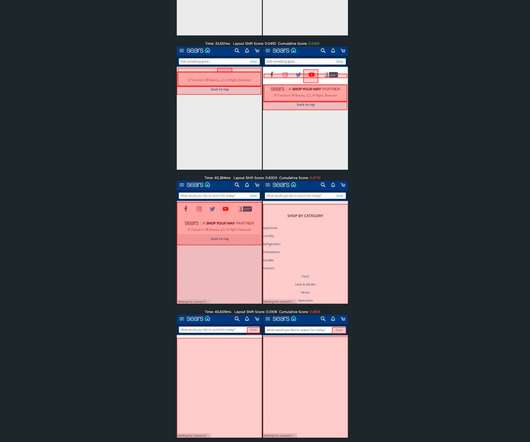
The newcomer to the scene was Cumulative Layout Shift (CLS), and, not surprisingly, it's the metric that's gotten the most questions. Does it correlate to user behaviour or business metrics in any measurable way? While I understand why score-based metrics add value, I'm a visual person. How is it calculated? is considered poor.
tpcorg/hammerdb:postgres and start the image Copy Code Copied Use a different Browser hammerdb@REDPOLL:~$ sudo docker run --network=host -it --name hammerdb-postgres tpcorg/hammerdb:postgres bash root@REDPOLL:/home/hammerdb/HammerDB-4.7# hammerpost will also gather system level metrics that you can use to analyze your tests.
However, that pesky 20% on the back end can have a big impact on downstream metrics like First Contentful Paint (FCP), Largest Contentful Paint (LCP), and any other 'loading' metric you can think of. The use of server-timing headers by content delivery networks closes a big gap. But what happens when it doesn't?
As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. For the network, we can use Iperf to assess the network bandwidth between the client and the database server to ensure it will be enough to meet our peak requirement.
We constrain ourselves to a real-world baseline device + network configuration to measure progress. Budgets are scaled to a benchmarknetwork & device. This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made. Partner meetings are illuminating.
In this case, we are not going to be talking about infrastructure services, such as a cloud computing platform like Microsoft Azure or a content distribution network like Akamai. And JavaScript can certainly make requests for additional network resources. Sometimes, the visitor’s browser itself can be the origin of network activity.
The idea behind this is to speed up cluster resources such as garbage collection, reduce image transfer over the network, and accelerate the application launch. A simple sysbench benchmark on MySQL shows an overhead between six and 10 percent on CPU-bound systems when running perf with the default sampling frequency of 4000 Hz.
” Here are additional metrics used to determine the reliability of a database, make adjustments that minimize downtime, and set benchmarks for meeting business continuity requirements. Without enough infrastructure (physical or virtualized servers, networking, etc.), Networking equipment (switches, routers, etc.)
Site performance is potentially the most important metric. Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Having a slow site might leave you on page 452 of search results, regardless of any other metric. Source: Google /SOASTA Research, 2018.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. Another window into this question is provided by the Web Confluence Metrics project.
While throughput performance is important, especially in data-centers, single threaded performance remains a pivotal metric for a large swath of application domains (HPC, Finance etc.). Instead, the focus has been on boosting aggregate performance by increasing core count.
We track LEGO.com, along with a handful of other leading ecommerce sites, in our public-facing Retail Benchmarks dashboard , which I encourage you to check out. Are you using a content delivery network (CDN) to bring elements like images closer to your users, so that delivery times are faster? Are images optimized?
Reduced network and device capacity correlate with other access challenges. Teams I've consulted are too often wrenched between celebration over "the big rewrite" launch and the morning-after realisation that the new stack is tanking business metrics. Accessibility: Performance is the foundation of access. Photo by Jay Heike.
These are the bestsellers in the web performance field, including the good old Speed Up Your Site (2003) by Andy King; Steve Souders’ Even Faster Web Sites (2009) ; Ilya Grigorik’s High Performance Browser Networking (2013) ; Tammy Everts’ Time is Money (2016) ; and a handful of more recent publications. Time is Money.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content