This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Since 2021, Google has incorporated Core Web Vitals into its ranking algorithm, rewarding websites that meet these performance benchmarks. Developers and performance engineers can swiftly discover interactions that lack latency and require optimizations to reach better levels of user experience. Improved SEO. Business impact.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. What breaks your app in production isnt always what you tested for in dev! The way out? How do we do so?
Slow performance in read-write activities can be a consequence of elevated latency for disk reads and writes. Keeping these response times short, even in situations of heavy traffic, prevents latency problems and guarantees that users have an application experience that feels immediate and responsive.
We created a benchmark of misconceptions first. We tested to see if multimodal LLMs can pick up misconceptions based on pictures of kids’ handwritten exercises. 16:11 : What about latency and battery consumption? 16:22 : I haven’t done extensive tests for battery consumption, but I haven’t seen anything egregious.
The solution lies in a proactive approach that leverages synthetic monitoring with real browser testing to systematically warm CDN edges before real users arrive. We’ll examine real-world case studies, performance benchmarks, and provide actionable guidance for implementing your own CDN warm-up strategy using synthetic monitoring.
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
This article is to simply report the YCSB bench test results in detail for five NoSQL databases namely Redis, MongoDB, Couchbase, Yugabyte and BangDB and compare the result side by side. I have also used the default six test scenarios as defined by the YCSB framework. I have restricted it to 10M records for each test.
Instead, they can ensure that services comport with the pre-established benchmarks. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. Latency is the time that it takes a request to be served. SLOs improve software quality. Reliability.
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. Throughput.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Performance Test. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. MySQL on AWS Performance Test. MySQL Performance Benchmark Configuration. Amazon RDS. Instance Type.
In this blog post, we compare Azure Database for MySQL vs. ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency.
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. Because pre-production environments are used for testing before an application is released to end users, teams have no access to real-user data. What is synthetic monitoring?
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Using simple lookup indices in Cassandra gives us the ability to maintain acceptable read latencies while doing heavy writes.
Leveraging pgbench , which is a benchmarking utility that comes bundled with PostgreSQL, I will put the cluster through its paces by executing a series of DML operations. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Although the default configuration simulates loading based loosely upon TPC-B, it is nevertheless easy to test other use cases by writing one’s own transaction script files. A script executing a benchmarking run: #!/bin/bash tps, lat 11.718 ms stddev 3.951 progress: 4440.0 tps, lat 11.075 ms stddev 3.519 progress: 4445.0
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. We performed a standard benchmarkingtest using the sysbench tool to compare the performance of a DLV instance vs a standard RDS MySQL instance, as shared in the following section.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks . uname -a Linux ubuntu19 5.3.0-rc3-custom
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Organizations must prepare for the EOL by creating a migration strategy, ensuring data backups, assessing compatibility with newer versions, and conducting thorough testing post-upgrade. This process involves several steps, including backup and restore best practices, exploring upgrade paths and strategies, and testing and validation.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 This explains, in part , how PostgreSQL performed better out of the box for this test workload. The throughput didn’t double but increased by 57%.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
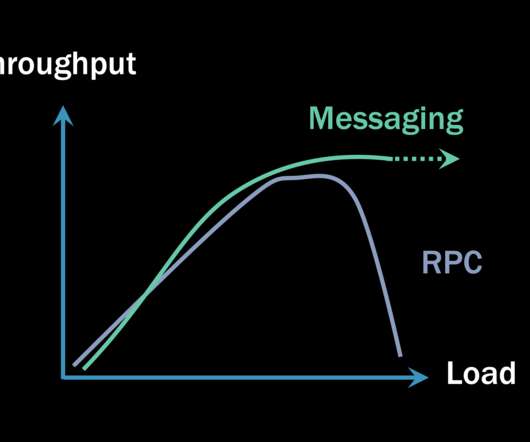
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging. Messaging doesn’t do that.
micro) The tests We will have very simple test cases. The second test will define how well the increasing load is served inside the previously identified range. Let us take a look also the latency: Here the situation starts to be a little bit more complicated. For documentation, the sysbench commands are: Test1 sysbench./src/lua/windmills/oltp_read.lua
Web performance is a broad subject, and you’ll find no shortage of performance testing tips and tutorials all over the web. Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. What is Performance Testing?
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. I couldn’t see any adverse effect on the TPS on quick tests.
Indexing efficiency Monitoring indexing efficiency in MySQL involves analyzing query performance, using EXPLAIN statements, utilizing performance monitoring tools, reviewing error logs, performing regular index maintenance, and benchmarking/testing. This KPI is also directly related to Query Performance and helps improve it.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. AWS is the #1 cloud provider for open-source database hosting, and the go-to cloud for MySQL deployments.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Building separate models for each of the benchmarks was required to get the correct asymptotic properties.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. There's also a test and println() in the loop to, hopefully, convince the compiler not to optimize-out an otherwise empty loop. This will slow this test a little.) Trying it out: centos$ time java TimeBench.
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. As it is infeasible to test every OLAP system runnable on AWS, we chose widely-used systems that represented a variety of architectures and cost models. Key findings.
As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS. The goal of these benchmarks was to both quantify performance differences between the two platforms and gain an understanding of their TCO. We used an in-house benchmark called voltdb-charglt.
Creating a HCI benchmark to simulate multi-tennent workloads. In such a case we have a Bandwidth heavy workload profile (reporting) sharing with a Latency Sensitive workload (transactional). We supply a pre-configured scenario which we call the DB Colocation test. Time based benchmark actions.
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. Benchmark before you decide. Transparent huge pages (THP) disabled.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Lower is better.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Building separate models for each of the benchmarks was required to get the correct asymptotic properties.
Budgets are scaled to a benchmark network & device. Automating testing against an objective baseline. Deciding what benchmark to use for a performance budget is crucial. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). What’s going on here?
If you are new to running Oracle, SQL Server, MySQL and PostgreSQL TPC-C workloads with HammerDB and have needed to investigate I/O performance the chances are that you have experienced waits on writing to the Redo, Transaction Log or WAL depending on the database you are testing. SQL> alter system flush buffer_cache; System altered.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content