This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I have generally held the view that replicating data to a secondary system is faster than sync-ing to disk, assuming the round trip network delay wasn’t high due to quality networks and co-located redundant servers. This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters.
Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers. This decoupling simplifies system architecture and supports scalability in distributed environments.
Instead, they can ensure that services comport with the pre-established benchmarks. Using data from Dynatrace and its SLO wizard , teams can easily benchmark meaningful, user-based reliability measurements and establish error budgets to implement SLOs that meet business objectives and drive greater DevOps automation. Reliability.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Two big things: They bring the messiness of the real world into your system through unstructured data. When your system is both ingesting messy real-world data AND producing nondeterministic outputs, you need a different approach.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. AWS High Performance XLarge (see system details below). MySQL Performance Benchmark Configuration.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
which is difficult when troubleshooting distributed systems. If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls.
Rather than listing the concepts, function calls, etc, available in Citus, which frankly is a bit boring, I’m going to explore scaling out a database system starting with a single host. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
However, not all user monitoring systems are created equal. In some cases, you will lack benchmarking capabilities. connectivity, access, user count, latency) of geographic regions. These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.
Querying the data While it is reasonable to create panels showing real-time load in order to explore better the types of queries that can be run against pg_stat_monitor, it is more practical to copy and query the data into tables after the benchmarking has completed its run. A script executing a benchmarking run: #!/bin/bash
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks . uname -a Linux ubuntu19 5.3.0-rc3-custom
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
you need to plan your transition to a newer version to maintain system stability and security. signifies the end of updates and support, which is crucial for maintaining system integrity. This can leave systems exposed to cyber threats and operational inefficiencies. If youre using MongoDB 6.0, Key Takeaways MongoDB 6.0
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. This segregation facilitates optimized I/O operations, preventing potential bottlenecks and enhancing overall system performance. Who can benefit from DLV? 2xlarge c5.2xlarge MySQL 8.0.31
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
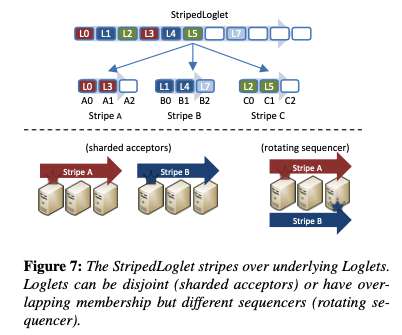
While ultimately this new system should be able to take advantage of the latest advances in consensus for improved performance, that’s not realistic given a 6-9 month in-production target. It’s such a powerful idea that I can imagine distributed systems implementers everywhere adopting it from now on. What does the VirtualLog give us?
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
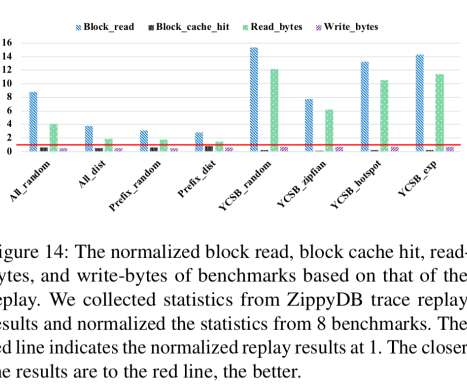
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
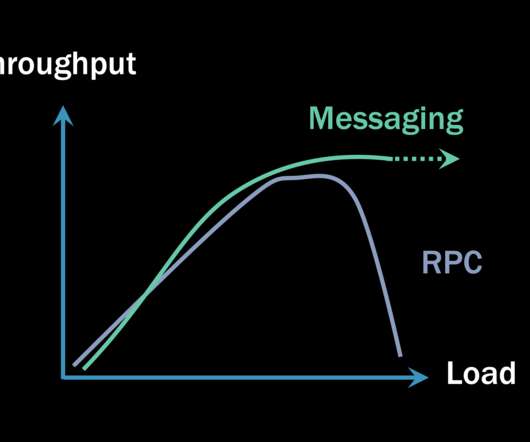
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Indexing efficiency Monitoring indexing efficiency in MySQL involves analyzing query performance, using EXPLAIN statements, utilizing performance monitoring tools, reviewing error logs, performing regular index maintenance, and benchmarking/testing. This KPI is also directly related to Query Performance and helps improve it.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. Microbenchmark os::javaTimeMillis() on both systems. Running this on the two systems saw similar results. Try changing the kernel clocksource.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and system design at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 on CentOS 7, both of them spec’d with four vCPUs but with the second one (server B) having a tad over twice as much memory than the reference one (server A).
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. Operating system Linux is the most common operating system for high-performance MySQL servers.
Benchmarking Cache Speed Memcached is optimized for high read and write loads, making it highly efficient for rapid data access in a basic key-value store. Redis’s support for pipelining in a Redis server can significantly reduce network latency by batching command executions, making it beneficial for write-heavy applications.
As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS. The goal of these benchmarks was to both quantify performance differences between the two platforms and gain an understanding of their TCO. We used an in-house benchmark called voltdb-charglt.
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. We focused on OLAP-oriented parallel data warehouse products available for AWS and restricted our attention to commercially available systems. Key findings. Query restrictions.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Only teams that master their systems can make intentional trade-offs.
on Myths and Legends of High Performance Computing — it’s a somewhat light-hearted look at some of the same issues by the leader of the team that built the Fugaku system I mention below. HPCG is led by Japan’s RIKEN Fugaku system at 16 petaflops, which is 3% of it’s peak capacity. Next generation architectures will use CXL3.0
Simply put, it’s the set of computational tasks that cloud systems perform, such as hosting databases, enabling collaboration tools, or running compute-intensive algorithms. Such demanding use cases place a great value on systems capable of fast and reliable execution, a need that spans across various industry segments.
They can also bolster uptime and limit latency issues or potential downtimes. Register now for free and experience the seamless operation of your databases across multi-cloud and hybrid-cloud systems. By spreading your data and apps around, you can get your systems to work together more smoothly and make the most out of your budget.
Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold. Pagespeed Benchmarks - US Retail - LCP When you examine a waterfall, it's pretty obvious that TTFB is the long pole in the tent, pushing out render times for the page.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Media Session API.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and system design at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
Budgets are scaled to a benchmark network & device. Tools and CI systems help them monitor progress & prevent regressions. Deciding what benchmark to use for a performance budget is crucial. Some systems show median RTTs near ~100ms for 3G users. Performance budgets are set early in the life of the project.
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . Additionally for the log disk component it is latency for an individual write that is crucial rather than the total I/O bandwidth. SQL> alter system flush buffer_cache; System altered.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content