This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Speed and scalability are significant issues today, at least in the application landscape. We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. However, the question arises of choosing the best one.
ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. Automating quality gates creates reliable checks and balances and speeds up the process by avoiding manual intervention.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. Reads and writes to your Primary, and even reads from Slave-1 will work at SSD speed. Amazon RDS.
Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). In some cases, you will lack benchmarking capabilities. RUM generates a lot of data.
Telltale provides Edgar with latencybenchmarks that indicate if the individual trace’s latency is abnormal for this given service. Telltale’s anomaly analysis looks at historic behavior and can evaluate whether the latency experienced by this trace is anomalous. Is this an anomaly or are we dealing with a pattern?
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Measuring the speed of time Is there already a microbenchmark for os::javaTimeMillis()? I've shared many posts about superpower observability tools, but often humble hacking is just as effective. Try changing the kernel clocksource.
Back in the day I wrote a lot of benchmarks in order to look for places where the actual performance of the CPU didn’t match what we expected. I wrote a lot of benchmarks. One benchmark I wrote measured the L2 cache latency. Finally, the Xbox 360 was designed to run at a higher clock speed, but then shipped at 3.2
Leveraging pgbench , which is a benchmarking utility that comes bundled with PostgreSQL, I will put the cluster through its paces by executing a series of DML operations. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load. Benchmarking Cache Speed Memcached is optimized for high read and write loads, making it highly efficient for rapid data access in a basic key-value store.
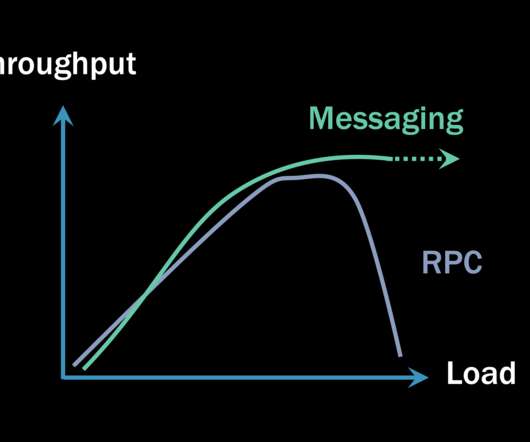
Sometimes developers only care about speed. Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. There are more steps, so the increased latency is easily explained. But the answer isn’t that simple.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Measuring the speed of time Is there already a microbenchmark for os::javaTimeMillis()? I've shared many posts about superpower observability tools, but often humble hacking is just as effective. Try changing the kernel clocksource.
Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution. Replication lag can occur due to various factors such as network latency, system resource limitations, complex transactions, or heavy write loads on the primary/master database.
Why speed matters, examples of the impact saving a few seconds of load time has had on revenue and engagement. Bandwidth, latency and it's fundamental impact on the speed of the web. An overview of tools for measuring performance, uptime monitoring, real user monitoring and performance benchmarking. Performance Tools.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Building separate models for each of the benchmarks was required to get the correct asymptotic properties.
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. Benchmark before you decide. Transparent huge pages (THP) disabled.
There will be a considerable gain if we combine this with other sets of great improvements in WAL archiving in PostgreSQL 15, as discussed in previous posts New WAL Archive Module/Library in PostgreSQL 15 and Speed Up of the WAL Archiving in PostgreSQL 15. But this comes with a considerable performance implication.
Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. Recall that single-core performance most directly translates into speed on the web. Today, either method returns a similar answer. Tap for a larger version. How bad is it?
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Measuring the speed of time Is there already a microbenchmark for os::javaTimeMillis()? I've shared many posts about superpower observability tools, but often humble hacking is just as effective. Try changing the kernel clocksource.
Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold. Pagespeed Benchmarks - US Retail - LCP When you examine a waterfall, it's pretty obvious that TTFB is the long pole in the tent, pushing out render times for the page.
If you've invested countless hours in speeding up your pages, but you're not using performance budgets to prevent regressions, you could be at risk of wasting all your efforts. INP logs the latency of all interactions throughout the entire page lifecycle. It's easier to make a fast website than it is to keep a website fast.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In early January a related paper was published by Satoshi Matsuoka et. petaflops, which is 0.8%
Memory Allocation: Allocating sufficient memory linked directly to the assigned CPU ensures effective utilization resulting in better system speed. The fundamental principles at play include evenly distributing the workload among servers for better application performance and redirecting client requests to nearby servers to reduce latency.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Speed is also something Google considers when ranking your website placement on mobile. Speed is also something Google considers when ranking your website placement on mobile.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Building separate models for each of the benchmarks was required to get the correct asymptotic properties.
On your first try, you can use it as a benchmark for optimizations later. Server caches help lower the latency between a Frontend and Backend; since key-value databases are faster than traditional relational SQL databases, it will significantly increase an API’s response time. No one likes a white blank screen, especially your users.
Even if it is 4G (5G, or whatever else) that doesn’t exactly guarantee you’ll be getting the amazing, theoretical speeds promised. Once a new network does get rolled out, it takes years for carriers to optimize it to try and close in on the promised bandwidth and latencybenchmarks.
Budgets are scaled to a benchmark network & device. JavaScript is the single most expensive part of any page in ways that are a function of both network capacity and device speed. Deciding what benchmark to use for a performance budget is crucial. Performance budgets are set early in the life of the project.
HTML, CSS, images, and fonts can all be parsed and run at near wire speeds on low-end hardware, but JavaScript is at least three times more expensive, byte-for-byte. India's speed test medians are moving quickly, but variance is orders-of-magnitude wide, with 5G penetration below 25% in the most populous areas.
In addition, such custom systems could only be benchmarked once they were deployed, so by the time multiple layers of management had each added a 50% safety margin to the initial SWAG , it was not unusual to see them running at 10% of capacity (but 150% of the lucky hardware salesman’s annual quota).
This processor has a base clock speed of 2.0GHz, with an all-core boost speed of 2.55GHz, and a max boost clock speed of 3.0GHz. I wrote about using CPU-Z to benchmark the Intel Xeon E5-2673 v3 processor in an Azure VM in this article. Figure 1: CPU-Z Benchmark Results for LS16v2. The L3 cache size is 64MB.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. When the word “performance” is heard, most people immediately think of speed. What is Performance Testing? Peak response time: The longest response time.
Performance issues surrounding Availability Groups typically were related to disk I/O or network speeds. Our customers who deployed Availability Groups were now using servers for primary and secondary replicas with 12+ core sockets and flash storage SSD arrays providing microsecond to low millisecond latencies. one without a replica).
In addition, such custom systems could only be benchmarked once they were deployed, so by the time multiple layers of management had each added a 50% safety margin to the initial SWAG , it was not unusual to see them running at 10% of capacity (but 150% of the lucky hardware salesman’s annual quota).
This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. Enhanced User Experience Whether you operate an e-commerce platform, a content management system, or any other application reliant on MySQL, users will notice and appreciate the improved speed and responsiveness.
The Lighthouse Performance score is based on some of the most important performance metrics : First Contentful Paint, First Meaningful Paint, Speed Index, Time to Interactive, First CPU Idle, and Estimated Input Latency. When it comes to network speed, Lighthouse gives you three options – and no others.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. maximum transition latency: Cannot determine or is not supported. . HammerDB difference from Sysbench. hardware limits: 1000 MHz - 3.80
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This allows the checkpoint process to maintain its speed while the random nature of the I/O requests deters any elevator seeking that could affect other I/O operations.
eCommerce Conversion Rate Benchmarks First off, we’ll start with some benchmarks. The lower conversion rate on mobile could be due to a variety of reasons including the website not being responsive for mobile devices, the speed isn’t up to par, etc. Improve Site Speed In 2019, having fast site speed is imperative.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content